This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Provide an at-a-glance view of your system’s health and performance Dynatrace guides you in quickly getting the most valuable SLOs set up in just a few clicks. Heterogeneous services require heterogeneous indicators Metrics, logs, and traces are the core ingredients for making your environment observable.
Imagine you’re using a lot of OpenTelemetry and Prometheus metrics on a crucial platform. A histogram is a specific type of metric that allows users to understand the distribution of data points over a period of time. In practical applications, percentiles are particularly useful for web performance analysis.
You can now: Kickstart your creation journey using ready-made dashboards Accelerate your data exploration with seamless integration between apps Start from scratch with the new Explore interface Search for known metrics from anywhere Let’s look at each of these paths through an end-to-end use case focused on Kubernetes monitoring.
This allows you to build customized visualizations with Dashboards or perform in-depth analysis with Notebooks. Thanks to the power of Grail, those details are available for all executions stored for the entire retention period during which synthetic results are kept. The new Dynatrace Synthetic app allows you to analyze these results.
Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. With Dashboards , you can monitor business performance, user interactions, security vulnerabilities, IT infrastructure health, and so much more, all in real time.
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. In a monitoring scenario, you typically preconfigure dashboards that are meant to alert you to performance issues you expect to see later. What is observability?
The release candidate of OpenTelemetry metrics was announced earlier this year at Kubecon in Valencia, Spain. Since then, organizations have embraced OTLP as an all-in-one protocol for observability signals, including metrics, traces, and logs, which will also gain Dynatrace support in early 2023.
For years, logs have been the dominant approach many observability vendors have taken to report business metrics on dashboards. Most of the use cases in these two broad categories benefit from the flexibility that comes from multiple available sources of business data.
Ensuring smooth operations is no small feat, whether you’re in charge of application performance, IT infrastructure, or business processes. Chances are, youre a seasoned expert who visualizes meticulously identified key metrics across several sophisticated charts. For instance, in a web shop, sales might vary by day of the week.
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Our script, available on GitHub , provides details. into NAM test definitions.
Service-level objectives (SLOs) can play a vital role in ensuring that all stakeholders have visibility into the resources being used and the performance of their applications. If your team is responsible for setting up Kubernetes clusters, you might want to monitor and optimize the workload performance when setting up SLOs.
Telemetry data, such as traces and metrics, allow you to analyze the end-to-end performance of your deployed applications. You can automatically detect and analyze performance issues across your entire tech stack with Davis® AI. Dynatrace observability is available for Red Hat OpenShift on IBM Power.
DataJunction: Unifying Experimentation and Analytics Yian Shang , AnhLe At Netflix, like in many organizations, creating and using metrics is often more complex than it should be. DJ acts as a central store where metric definitions can live and evolve. As an example, imagine an analyst wanting to create a Total Streaming Hours metric.
Break data silos and add context for faster, more strategic decisions : Unifying metrics, logs, traces, and user behavior within a single platform enables real-time decisions rooted in full context, not guesswork. Standardizing platforms minimizes inconsistencies, eases regulatory compliance, and enhances software quality and security.
Service Level Objectives (SLO) tracking: Honeycomb charts can visualize SLOs, helping you monitor whether your services meet performance and reliability targets. To achieve the best visual outcome, we recommend experimenting with the available customization options. Based on the color, you immediately see if any SLOs are off track.
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. But is five nines availability attainable? Downtime per year. 90% (one nine).
Now, Dynatrace has the ability to turn numerical values from logs into metrics, which unlocks AI-powered answers, context, and automation for your apps and infrastructure, at scale. The parameter Billed Duration is only available in logs , so it makes sense to extract it from your logs so that you can keep an eye on your cloud costs.
The end goal, of course, is to optimize the availability of organizations’ software. Dynatrace is widely recognized for its AI capabilities’ ability to predict and prevent issues, and automatically identify root causes, maximizing availability. That’s where observability from Dynatrace goes far beyond “observing systems.”
Spark-Radiant is Apache Spark Performance and Cost Optimizer. Spark-Radiant will help optimize performance and cost considering catalyst optimizer rules, enhance auto-scaling in Spark, collect important metrics related to a Spark job, Bloom filter index in Spark, etc. Spark-Radiant is now available and ready to use.
With Dynatrace, customers can utilize the full set of Azure capabilities, including metrics and data from the Azure platform, and automatically identify workflow optimization opportunities. By prioritizing observability, organizations can ensure the availability, performance, and security of business-critical applications.
address these limitations and brings new monitoring and analytical capabilities that weren’t available to Extensions 1.0: address these limitations and brings new monitoring and analytical capabilities that weren’t available to Extensions 1.0: Comprehensive metrics support Extensions 2.0 available, and more are in the pipeline.
That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags. In addition to tracing, observability also defines two other key concepts, metrics and logs. When software runs in a monolithic stack on on-site servers, observability is manageable enough. What is OpenTelemetry?
To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. Named after the Greek god who brought fire down from Mount Olympus, Prometheus metrics have been transforming observability since the project’s inception in 2012.
While Fluentd solves the challenges of collecting and normalizing Kubernetes events and logs, Kubernetes performance and availability problems can rarely be solved by investigating logs in isolation. Detailed performance analysis for better software architecture and resource allocation. Transaction breakdowns.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Boost your operational resilience: Combining availability and security is now essential.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Implementing clustering and quorum queues in RabbitMQ significantly improves load distribution and data redundancy, ensuring high availability and fault tolerance for messaging services.
The five key metrics to improve customer satisfaction To help turn this around, Dynatrace makes available its unified observability platform, which captures all CX interactions and transactions in an automated, intelligent manner – including user session replays. When combined, key metrics will generate an accurate CX index score.
This article explores SLOs for service performance. According to the Google Site Reliability Engineering (SRE) handbook, monitoring the four golden signals is crucial in delivering high-performing software solutions. While this connection might sound simple, finding the right metrics to measure the needed SLIs takes time and effort.
Observability means how well you can understand what is happening in a system by collecting metrics, logs, and traces. This allows you to get comfortable with all the underlying metrics and log data. Observability of Azure infrastructure and all the services it supports helps you pinpoint performance issues and eliminate guesswork.
Whenever a performance problem is flagged, Infrastructure and Operations (I&O) practitioners strive to resolve the issue as soon as possible by identifying the root cause, understanding the impact, obtaining the relevant details, and fixing the issue within the shortest possible timeframe—the meantime to resolution (MTTR). Dynatrace news.
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. BlackDuck performs a security and vulnerability check, returning a scan result.
The Dynatrace platform now enables comprehensive data exploration and interactive analytics across data sets (trace, logs, events, and metrics)empowering you to solve complex use cases, handle any observability scenario, and gain unprecedented visibility into your systems. But why stop there?
The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data. The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data.
This dual-path approach leverages Kafkas capability for low-latency streaming and Icebergs efficient management of large-scale, immutable datasets, ensuring both real-time responsiveness and comprehensive historical data availability. This integration will not only optimize performance but also ensure more efficient resource utilization.
Managing cloud performance is increasingly challenging for organizations that spread workloads across a greater variety of platforms. Moreover, organizations have to balance maintaining security, retaining cloud management expertise, and managing infrastructure performance. Rural lifestyle retail giant Tractor Supply Co.
Your teams want to iterate rapidly but face multiple hurdles: Increased complexity: Microservices and container-based apps generate massive logs and metrics. You can select any trigger thats available for standard workflows, including schedules, problem triggers, customer event triggers, or on-demand triggers.
You can either continue with the custom infrastructure metrics dashboard you created in Part I or use the dashboard we prepared here (Dynatrace login required). exploring your data when you know your desired outcome but are unfamiliar with the available data. Select the tile and go to the Visual tab. Expand the Single value section.
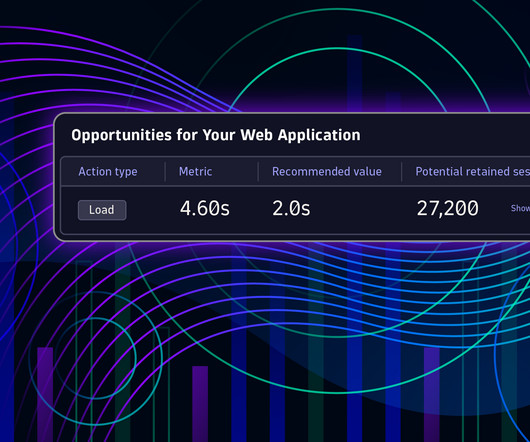
Performance and error optimization is complicated, and the approach to driving improvement has long relied on static recommendations disconnected from a site’s end users and their experiences. Sometimes, these recommendations are so far from current performance or cost so much to implement that they seem irrelevant or unattainable.
Particularly during the COVID-19 pandemic, we’ve seen how poor application performance can impact business bottom lines and lead to lost revenue for many organizations, as laid out in our recent blog post about digital experience. with: Aggregated field metrics?rather?than?valuable?details Metrics and recommendations?rather
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
This blog post will share broadly-applicable techniques (beyond GraphQL) we used to perform this migration. So, we relied on higher-level metrics-based testing: AB Testing and Sticky Canaries. To determine customer impact, we could compare various metrics such as error rates, latencies, and time to render.
With more organizations taking the multicloud plunge, monitoring cloud infrastructure is critical to ensure all components of the cloud computing stack are available, high-performing, and secure. APM provides real-time visibility into the status and performance of applications. predict and prevent security breaches and outages.
As our customers adopt agile software development and continuous delivery to drive value faster, they face new risks that could impact availability, performance, and business KPIs. An SLI is a measurement of the performance or availability of an entity. The measurement equates to a metric that captures expected results.
Dynatrace container monitoring supports customers as they collect metrics, traces, logs, and other observability-enabled data to improve the health and performance of containerized applications. VAPO is available in both Microsoft Azure and AWS. It’s an enterprise product that we use to help modernize the VA,” Fuqua said.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content