This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In September, we announced the availability of the Dynatrace Software Intelligence Platform on Microsoft Azure as a SaaS solution and natively in the Azure portal. Today, we are excited to provide an update that Dynatrace SaaS on Azure is now generally available (GA) to the public through Dynatrace sales channels. Dynatrace news.
You can now: Kickstart your creation journey using ready-made dashboards Accelerate your data exploration with seamless integration between apps Start from scratch with the new Explore interface Search for known metrics from anywhere Let’s look at each of these paths through an end-to-end use case focused on Kubernetes monitoring.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. While the SLO management web UI and API are already available, the dashboard tile will be released within the next weeks.
Thanks to the power of Grail, those details are available for all executions stored for the entire retention period during which synthetic results are kept. It now fully supports not only Network Availability Monitors but also HTTP synthetic monitors. Details of requests sent during each monitor execution are also available.
Imagine you’re using a lot of OpenTelemetry and Prometheus metrics on a crucial platform. A histogram is a specific type of metric that allows users to understand the distribution of data points over a period of time. You’re gathering a lot of data, but you can’t make sense of it. What are histograms, and why use them?
From a cost perspective, internal customers waste valuable time sending tickets to operations teams asking for metrics, logs, and traces to be enabled. A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. This approach is costly and error prone.
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Our script, available on GitHub , provides details. into NAM test definitions.
The release candidate of OpenTelemetry metrics was announced earlier this year at Kubecon in Valencia, Spain. Since then, organizations have embraced OTLP as an all-in-one protocol for observability signals, including metrics, traces, and logs, which will also gain Dynatrace support in early 2023.
For years, logs have been the dominant approach many observability vendors have taken to report business metrics on dashboards. Most of the use cases in these two broad categories benefit from the flexibility that comes from multiple available sources of business data.
Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. Even if infrastructure metrics aren’t your thing, you’re welcome to join us on this creative journey simply swap out the suggested metrics for ones that interest you.
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. If you’ve read about observability, you likely know that collecting the measurements of logs, metrics, and distributed traces are the three key pillars to achieving success.
A Dynatrace API token with the following permissions: Ingest OpenTelemetry traces ( openTelemetryTrace.ingest ) Ingest metrics ( metrics.ingest ) Ingest logs ( logs.ingest ) To set up the token, see Dynatrace API – Tokens and authentication in Dynatrace documentation. If you don’t have one, you can use a trial account.
Telemetry data, such as traces and metrics, allow you to analyze the end-to-end performance of your deployed applications. It automates tasks such as provisioning and scaling Dynatrace monitoring components, updating configurations, and ensuring the health and availability of your monitoring infrastructure.
Dynatrace, available as an Azure-native service , has a longstanding partnership with Microsoft, deeply rooted in a strong “build with” approach to deliver seamless user experience. This enables Dynatrace customers to achieve faster time-to-value and accelerate innovation.
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. But is five nines availability attainable? Downtime per year. 90% (one nine).
The end goal, of course, is to optimize the availability of organizations’ software. Dynatrace is widely recognized for its AI capabilities’ ability to predict and prevent issues, and automatically identify root causes, maximizing availability. Automation, however, should not be done in isolation of tech.
Access policies for Dynatrace Grail™ data lakehouse are still available as service-related policies; they allow you to control access to the monitoring data on a per-data-source level, for example, logs and metrics. All other default policies on the service level, for example, “AutomationEngine – User” access, are now marked as Legacy.
Chances are, youre a seasoned expert who visualizes meticulously identified key metrics across several sophisticated charts. Activate Davis AI to analyze charts within seconds Davis AI can help you expand your dashboards and dive deeper into your available data to extract additional information.
To achieve the best visual outcome, we recommend experimenting with the available customization options. While histograms look much like time-series bar charts, they’re different in that each bar represents a count (often termed frequency) of metric values. Try different cell shapes.
A Kubernetes SLO that continuously evaluates CPU, memory usage, and capacity and compares these available resources to the requested and utilized memory of Kubernetes workloads makes potential resource waste visible, revealing opportunities for countermeasures.
To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. Named after the Greek god who brought fire down from Mount Olympus, Prometheus metrics have been transforming observability since the project’s inception in 2012.
That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags. In addition to tracing, observability also defines two other key concepts, metrics and logs. When software runs in a monolithic stack on on-site servers, observability is manageable enough. What is OpenTelemetry?
address these limitations and brings new monitoring and analytical capabilities that weren’t available to Extensions 1.0: Comprehensive metrics support Extensions 2.0 These bundles ensure the provisioning of pre-configured dashboards, alerts, unified analysis views, and a topology model that relates metrics and entities.
The Carbon Impact app directly supports our customers sustainability efforts through granular real-time emissions reporting and analytics, translating host utilization metrics into their CO2 equivalent (CO2e). The certification results are now publicly available. Today, Carbon Impact has a new name: Cost & Carbon Optimization.
The five key metrics to improve customer satisfaction To help turn this around, Dynatrace makes available its unified observability platform, which captures all CX interactions and transactions in an automated, intelligent manner – including user session replays. When combined, key metrics will generate an accurate CX index score.
The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data. The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Boost your operational resilience: Combining availability and security is now essential.
With Dynatrace, customers can utilize the full set of Azure capabilities, including metrics and data from the Azure platform, and automatically identify workflow optimization opportunities. By prioritizing observability, organizations can ensure the availability, performance, and security of business-critical applications.
The type of breached baseline (auto-detected baseline or fixed manual threshold) is also available as additional information in the crash rate increase section. The post Identify issues immediately with actionable metrics and context in Dynatrace Problem view appeared first on Dynatrace blog. How to get started. New to Dynatrace?
Implementing clustering and quorum queues in RabbitMQ significantly improves load distribution and data redundancy, ensuring high availability and fault tolerance for messaging services. Classic queues can be used in clusters, emphasizing their behavior during node failures, particularly regarding durability and availability.
You can either continue with the custom infrastructure metrics dashboard you created in Part I or use the dashboard we prepared here (Dynatrace login required). exploring your data when you know your desired outcome but are unfamiliar with the available data. Select the tile and go to the Visual tab. Expand the Single value section.
The Dynatrace platform now enables comprehensive data exploration and interactive analytics across data sets (trace, logs, events, and metrics)empowering you to solve complex use cases, handle any observability scenario, and gain unprecedented visibility into your systems.
Your teams want to iterate rapidly but face multiple hurdles: Increased complexity: Microservices and container-based apps generate massive logs and metrics. You can select any trigger thats available for standard workflows, including schedules, problem triggers, customer event triggers, or on-demand triggers.
This dual-path approach leverages Kafkas capability for low-latency streaming and Icebergs efficient management of large-scale, immutable datasets, ensuring both real-time responsiveness and comprehensive historical data availability. These alerts promptly notify us of any potential issues, enabling us to swiftly address regressions.
Thats why Dynatrace will make its AI-powered, unified observability platform generally available on Google Cloud for all customers later this year. The power of Dynatrace unified observability on Google Cloud By the end of June, the latest Dynatrace core innovations will be available on Google Cloud, including the following: Dynatrace Grail.
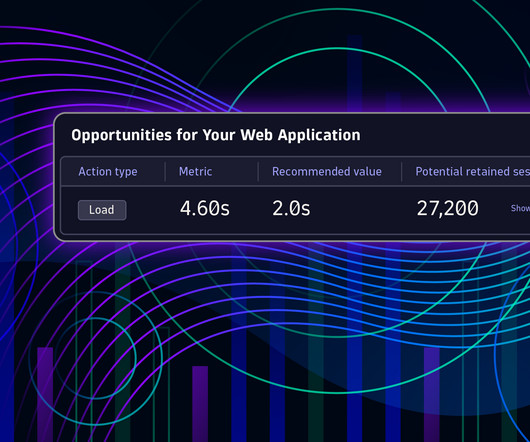
To provide “quality signals that are essential to delivering a great user experience on the web,” Google introduced their Core Web Vitals initiative last year, advocating the Largest contentful paint , Cumulative layout shift , and First input delay metrics. with: Aggregated field metrics?rather?than?valuable?details
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
The addition of more and more metrics over time has only made this increasingly complex. Performance metrics to improve can be Visually Complete, Speed Index, or other timing metrics associated with the page load cycle. It predicts user behavior based on performance/error experience.
There are numerous programming languages available today, with new ones continuously emerging. The following list is prepared after considering metrics like recent trends, language popularity, career prospects, open-source projects, and more. Which Automation Programming Language Is the Best for Testing?
So, we relied on higher-level metrics-based testing: AB Testing and Sticky Canaries. To determine customer impact, we could compare various metrics such as error rates, latencies, and time to render. We spent the next few months diving into these high-level metrics and fixing issues such as cache TTLs, flawed client assumptions, etc.
As our customers adopt agile software development and continuous delivery to drive value faster, they face new risks that could impact availability, performance, and business KPIs. An SLI is a measurement of the performance or availability of an entity. The measurement equates to a metric that captures expected results.
The standard dictionary subscript notation is also available. Imagine a ML practitioner on the Netflix Content ML team, sourcing features from hundreds of columns in our data warehouse, and creating a multitude of models against a growing suite of metrics. You can access Configs of any past runs easily through the Client API.
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. According to Google’s SRE handbook , best practices, there are “ Four Golden Signals ” we can convert into four SLOs for services: reliability, latency, availability, and saturation.
Ingest OpenTelemetry traces ( openTelemetryTrace.ingest ) Ingest metrics ( metrics.ingest ) Ingest logs ( logs.ingest ) A Kubernetes cluster (we recommend using kind) Helm, to install the demo on your Kubernetes cluster Once your Kubernetes cluster is up and running, the next step is to create a secret containing the Dynatrace API token.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content