This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The release candidate of OpenTelemetry metrics was announced earlier this year at Kubecon in Valencia, Spain. Since then, organizations have embraced OTLP as an all-in-one protocol for observability signals, including metrics, traces, and logs, which will also gain Dynatrace support in early 2023.
Today, Dynatrace is happy to announce OneAgent support for discovering and automatically capturing OpenTelemetry trace data for Java. PurePath integrates OpenTelemetry Java data for enterprise-grade collection and contextual analytics. Use-case example: WorldAtlas sample application. protection of sensitive data.
As a Software Engineer, the mind is trained to seek optimizations in every aspect of development and ooze out every bit of available CPU Resource to deliver a performing application. Considering all aspects and needs of current enterprise development, it is C++ and Java which outscore the other in terms of speed. Ahem, Slow!
Although these COBOL applications operate with consistent performance, companies and governments are forced to transform them to new platforms and rewrite them in modern programming languages (like Java) for several reasons. Thus, implementing applications in Java can result in considerable financial savings.
Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. Spring Boot, on the other hand, is a Java framework for building cloud-native Java applications. Davis topology-aware anomaly detection and alerting for your Micrometer metrics. Here’s how it works. of Micrometer.
Dynatrace is fully committed to the OpenTelemetry community and to the seamless integration of OpenTelemetry data , including ingestion of custom metrics , into the Dynatrace open analytics platform. Find OpenTracing for Java seamlessly integrated into PurePath 4. ConcurrentMap<String, String> map = getTracingHazelcast().getMap("map");
Having released this functionality in an Early Adopter Release with OneAgent version 1.173 and Dynatrace version 1.174 back in August 2019, we’re now happy to announce the General Availability of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux.
There are numerous programming languages available today, with new ones continuously emerging. The following list is prepared after considering metrics like recent trends, language popularity, career prospects, open-source projects, and more. Which Automation Programming Language Is the Best for Testing?
To provide you with more value when monitoring hosts in infrastructure mode, we’re extending our infrastructure mode with a range of metrics that have until now only been available in full-stack mode. Monitor any infrastructure component and backing service that’s written in Java. Monitor additional metrics.
focused on technology coverage, building on the flexibility of JMX for Java and Python-based coded extensions for everything else. address these limitations and brings new monitoring and analytical capabilities that weren’t available to Extensions 1.0: Comprehensive metrics support Extensions 2.0 Dynatrace Extensions 1.0
Solution : Use optimized methods to access / query for specific data, e.g.: getNodeByType resulted in 98% reduction of CPU usage, better performance, returned high availability and reduced operational costs. The metrics are great for anyone in operations and capacity planning. Why Devs – and Immigrants to Qatar – Love Dynatrace!
As the application owner of an e-commerce application, for example, you can enrich the source code of your application with domain-specific knowledge by adding actionable semantics to collected performance or business metrics. New OpenTelemetry metrics exporters provide the broadest language support on the market.
That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags. In addition to tracing, observability also defines two other key concepts, metrics and logs. When software runs in a monolithic stack on on-site servers, observability is manageable enough.
Welcome back to the second part of our blog series on how easy it is to get enterprise-grade observability at scale in Dynatrace for your OpenTelemetry custom metrics. In Part 1 , we announced our new OpenTelemetry custom-metric exporters that provide the broadest language coverage on the market, including Go , .NET record(value); }.
We’re happy to announce the Early Adopter Release of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux (available with OneAgent version 1.173 and Dynatrace version 1.174). For details on availablemetrics, see our help page on host performance monitoring.
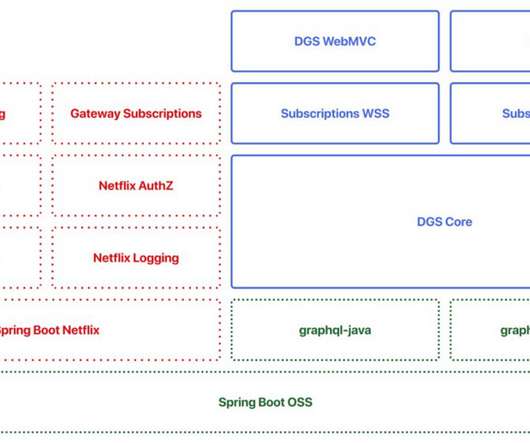
By open-sourcing the project, we hope to contribute to the Java and GraphQL communities and learn from and collaborate with everyone who will be using the framework to make it even better in the future. The transition to the new federated architecture meant that many of our backend teams needed to adopt GraphQL in our Java ecosystem.
Its design prioritizes high availability and efficient data transfer with minimal overhead, making it a practical choice for handling real-time data pipelines and distributed event processing. It follows a push-based approach, ensuring messages are distributed to consumers as soon as they become available.
A single API team maintained both the Java implementation of the Falcor framework and the API Server. So, we relied on higher-level metrics-based testing: AB Testing and Sticky Canaries. To determine customer impact, we could compare various metrics such as error rates, latencies, and time to render. How does it work?
We’re proud to announce the general availability of OneAgent full-stack monitoring for the AIX operating system. Monitoring IBM Power Systems isn’t a simple task, due to its specific architecture, there aren’t many tools available on the market. The ones that are available are old generation. Dynatrace news.
Java, Go, and Node.js That trend will likely continue as Kubernetes security awareness further rises and a new class of security solutions becomes available. In general, metrics collectors and providers are most common, followed by log and tracing projects. Java, Go, and Node.js Kubernetes moved to the cloud in 2022.
Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. Spring Boot, on the other hand, is a Java framework for building cloud-native Java applications. Davis topology-aware anomaly detection and alerting for your Micrometer metrics. Here’s how it works. of Micrometer.
Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. Spring Boot, on the other hand, is a Java framework for building cloud-native Java applications. Davis topology-aware anomaly detection and alerting for your Micrometer metrics. Here’s how it works. of Micrometer.
Another benefit of defining custom APIs is that the memory allocation and surviving object metrics are split by each custom API definition. While the amount of bytes allocated for the Java API is typically 1.5X the average, in this case, the allocation for the Java API was more than 3X higher than the average, 41 TiB.
Listen, learn, improve, and repeat The latest update to the Citrix monitoring extension is now available. Effortlessly monitor your Citrix environment with Dynatrace The Citrix monitoring process now employs two methods to collect metrics and provide complete Citrix performance observability.
The following is the screenshot of the Dynatrace Problem Ticket: Dynatrace detected the crash of notes.exe and additionally found the root cause to be high garbage collection of that java process. The following chart shows an interesting fact: the notes processes peaked at 593MB even though plenty of memory was still available on the host.
This has led to the recent release of our new Lambda monitoring extension supporting Node.js, Java, and Python. To handle N parallel requests, N Lambda instances need to be available, and AWS will spin up up to 1000 such instances automatically to handle 1000 parallel requests. Dynatrace has offered a Lambda code module for Node.js
Resource consumption: Observing computational resource availability and saturation, whether deployed in cloud-native environments like Kubernetes or CPU-enabled servers. OpenTelemetry has become a standard for collecting traces, metrics, and logs. Maintained under the Apache 2.0 However, Python models are trickier.
Collector Custom Resource A custom resource (CR) represents a customization of a specific Kubernetes installation that isnt necessarily available in a default Kubernetes installation; CRs help make Kubernetes more modular. There are two versions available: v1alpha1 : apiVersion: opentelemetry.io/v1alpha1 spec.containers[*].name}'
Spring also introduced Micrometer, a vendor-agnostic metric API with rich instrumentation options. Soon after, Dynatrace built a registry for exporting Micrometer metrics. Our data APIs, which ingest millions of metrics, traces, and logs per second, are reconciled using Micrometer-based metrics.
Manual and configuration-heavy approaches to putting telemetry data into context and connecting metrics, traces, and logs simply don’t scale. Automatic contextualization of log data works out-of-the-box for popular languages like Java,NET, Node.js, Go, and PHP, as well as for NGiNX and Apache Web servers. How to get started.
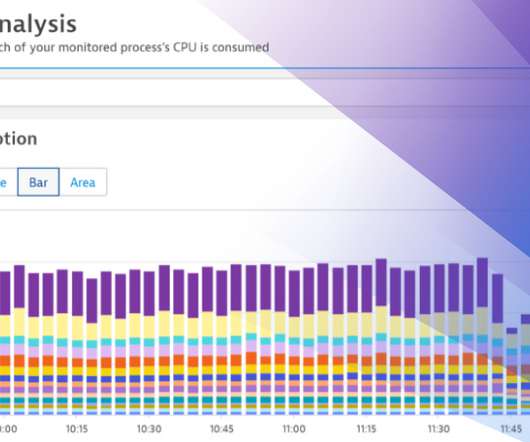
While in classic bare-metal stacks CPU resources are made “available” through over-provisioning, in modern SaaS environments you only pay for those CPU resources that you use—no over-provisioning of resources is required. Analyzing and optimizing CPU consumption has always been an important concern.
Making applications observable—relying on metrics, logs, and traces to understand what software is doing and how it’s performing—has become increasingly important as workloads are shifting to multicloud environments. We also introduced our demo app and explained how to define the metrics and traces it uses.
Monitoring SAP products can present challenges Monitoring SAP systems can be challenging due to the inherent complexity of using different technologies—such as ABAP, Java, and cloud offerings—and the sheer amount of generated data. Any insights can be annotated and documented with the help of markdown. Architectural overview.
As organizations adopt more cloud-native technologies, observability data—telemetry from applications and infrastructure, including logs, metrics, and traces—and security data are converging. In the cloud, infrastructure components are often distributed across multiple regions, availability zones, and even multiple cloud providers.
Symptoms : No data is provided for affected metrics on dashboards, alerts, and custom device pages populated by the affected extension metrics. These pages are now available to be used in security policies: Settings > Anomaly detection > Applications. General Availability (Build 1.231.196). Dashboards.
To emit a run queue latency metric, we leveraged three eBPF hooks: sched_wakeup, sched_wakeup_new, and sched_switch. There are kfuncs available to lock and unlock RCU read-side critical sections. When a cgroup ID correlates with a container, we emit a percentile timer Atlas metric (runq.latency) for that container.
I have been using it at my current tour through different conferences ( Devoxx , Confitura ) and meetups, ( Cloud Native , KraQA , Trojmiasto Java UG ) where I’ve promoted keptn. Automated Metric Anomaly Detection. Prometheus is a great open source monitoring solution in the cloud-native space that gives me a lot of metrics.
Dynatrace monitors your full stack and offers you thousands of metrics with almost zero configuration. This article we help distinguish between process metrics, external metrics and PurePaths (traces). OneAgent & application metrics. OneAgent & cloud metrics. Dynatrace news.
With other products, we had to make guesses about the impacted services based solely on metrics”. By observing these metrics, you can easily catch unbalanced message processing that could result in severe problems such as queue overflows when producer services send significantly more messages to the queue than consumer services can process.
Figure 5 shows the service flow of a Java-based application hosted on VMware. A service flow of a Java-based application hosted on VMware. In Figure 7, we can pick the service from the service flow, look at the metrics, and then compare the performance changes in a single, built-in Dynatrace feature.
Other distributions like Debian and Fedora are available as well, in addition to other software like VMware, NGINX, Docker, and, of course, Java. OneAgent for the ARM platform comes with several deep-code monitoring modules: Java, NGINX, and Node.js. For details on availablemetrics, see host performance monitoring.
With the release of Dynatrace 1.194, we’ve added CPU related infrastructure metrics for LPARs (host metrics) and regions (process metrics) and expanded our multidimensional analysis to IBM Z systems, including CICS, IMS, and the CICS transaction gateway. . This metric helps you to understand your current workload.
Achieving the ideal state with aggregated, centralized log data, metrics, traces , and other metadata is challenging—particularly for multicloud environments. Further, these resources support countless Kubernetes clusters and Java-based architectures. Metrics are often tracked and measured relative to a baseline or threshold.
Cloud-native observability for Google’s fully managed GKE Autopilot clusters demands new methods of gathering metrics, traces, and logs for workloads, pods, and containers to enable better accessibility for operations teams. Managed Kubernetes clusters on GKE Autopilot have gained unprecedented momentum among enterprises.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content