This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Site reliability engineering (SRE) plays a vital role in ensuring Java applications' high availability, performance, and scalability. This discipline merges softwareengineering and operations, aiming to create a robust infrastructure that supports seamless user experiences.
All the data bound to hosts is analyzed by the Davis AI causation engine and made available on custom dashboards and events pages. One of our softwareengineers, Tomasz Gajger, has been involved in a research project related to GPU performance analysis. Example 1: Gain visibility into your NVIDIA GPUs. What’s next.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
SRE is the transformation of traditional operations practices by using softwareengineering and DevOps principles to improve the availability, performance, and scalability of releases by building resiliency into apps and infrastructure. Investing in automation and tooling to avoid toil. SRE vs DevOps? Reduced latency.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of softwareengineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026. Automation, automation, automation.
Platform engineering is a practice that outlines how development teams build internal platforms to create self-service capabilities for softwareengineering teams. The result is a cloud-native approach to software delivery. Platform engineering cannot stand alone, however.
Platform engineering creates and manages a shared infrastructure and set of tools, such as internal developer platforms (IDPs) , to enable software developers to build, deploy, and operate applications more efficiently. “That means making it available, resilient, and secure,” Grabner said.
Problem remediation is too time-consuming According to the DevOps Automation Pulse Survey 2023 , on average, a softwareengineer takes nine hours to remediate a problem within a production application. With that, Softwareengineers, SREs, and DevOps can define a broad automation and remediation mapping.
Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE focuses on automation.
Softwareengineering for machine learning: a case study Amershi et al., More specifically, we’ll be looking at the results of an internal study with over 500 participants designed to figure out how product development and softwareengineering is changing at Microsoft with the rise of AI and ML. ICSE’19.
Keeping pace with modern digital transformation requires ensuring that applications are responsive, resilient, and always available amid increased complexity. Site reliability engineering (SRE) has recently become a critical discipline in recent years as the world has shifted in favor of web-based interactions.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data.
Build an umbrella for Development and Operations In modern softwareengineering, the discipline of platform engineering delivers DevSecOps practices to developers to bridge the gaps between development, security, and operations and enhance the developer experience. For full details, see Dynatrace Documentation.
While infrastructure has historically been treated as a bottleneck where proper scaling and compute power are applied to improve performance, these aspects are now typically addressed by hyperscalers that offer cloud-based infrastructure and infrastructure as a service.
Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE focuses on automation.
About two years ago, we, at our newly formed Machine Learning Infrastructure team started asking our data scientists a question: “What is the hardest thing for you as a data scientist at Netflix?” mainly because of mundane reasons related to softwareengineering. like they would do in a Jupyter notebook.
All such automation is available while your environment is continuously enriched with additional contextual information that connects the responsible teams with your software development process. Associated ownership information is available on each entity page. Assignment of vulnerabilities to the responsible team members.
Check out the following use cases to learn how to drive innovation from development to production efficiently and securely with platform engineering observability. According to Deinhammer, once software is released into production, it’s usually deployed at a large scale—often in complex multicloud or hybrid setups.
December 2 1pm-2pm CMP 326-R Capacity Management Made Easy with Amazon EC2 Auto Scaling Vadim Filanovsky , Senior Performance Engineer & Anoop Kapoor, AWS Abstract :Amazon EC2 Auto Scaling offers a hands-free capacity management experience to help customers maintain a healthy fleet, improve application availability, and reduce costs.
It’s also a great opportunity for you to learn more about the available roles, the technical challenges the teams are facing and what it’s like to work on a backend engineering team at Netflix. If you want to practice, focus on medium-difficulty real-world problems you might encounter in a softwareengineering role.
Interview with Pallavi Phadnis This post is part of our “ Data Engineers of Netflix ” series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Pallavi Phadnis is a Senior SoftwareEngineer at Netflix. Pallavi, what’s your journey to data engineering at Netflix?
In response to the scale and complexity of modern cloud-native technology, organizations are increasingly reliant on automation to properly manage their infrastructure and workflows. Operations automation: The operations section addresses the level of automation organizations use in maintaining and managing existing software.
Motivation Growth in the cloud has exploded, and it is now easier than ever to create infrastructure on the fly. Groups beyond softwareengineering teams are standing up their own systems and automation. At many companies, managing cloud hygiene and security usually falls under the infrastructure or security teams.
HDR was launched at Netflix in 2016 and the number of titles available in HDR has been growing ever since. Join us and be a part of the amazing team that brought you this tech-blog; open positions: SoftwareEngineer, Cloud Gaming SoftwareEngineer, Live Streaming References [1] L. Krasula, A. Choudhury, S.
In a recent webinar , Dynatrace DevOps activist Andi Grabner and senior softwareengineer Yarden Laifenfeld explored developer observability. They also care about infrastructure: SREs require system visibility and incident management. Dynatrace enables teams to specify SLOs, such as latency, uptime, availability, and more.
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. In effect, the engineer designs and builds the world wherein the software operates. What: The Modern Stack of ML Infrastructure.
Serverless architectures help developers innovate more efficiently and effectively by removing the burden of managing underlying infrastructure. – Robert Trueman, Head of SoftwareEngineering at CDL. available for quite some time?already. available due to an attached OneAgent extension, we’ve added a dedicated?
Triplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Join Etleap , an Amazon Redshift ETL tool to learn the latest trends in designing a modern analytics infrastructure. Who's Hiring? Make your job search O (1), not O ( n ).
In the absence of true A/B testing, our analyses rely on using the available data to adjust away spurious correlations between the treatment and the outcome metrics. But how well we can do so depends on whether the available data is sufficient to account for all such correlations. without having to become softwareengineers themselves.
Triplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. For heads of IT/Engineering responsible for building an analytics infrastructure , Etleap is an ETL solution for creating perfect data pipelines from day one. Who's Hiring?
Triplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Join Etleap , an Amazon Redshift ETL tool to learn the latest trends in designing a modern analytics infrastructure. Who's Hiring? Make your job search O (1), not O ( n ).
Triplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Join Etleap , an Amazon Redshift ETL tool to learn the latest trends in designing a modern analytics infrastructure. Who's Hiring? Make your job search O (1), not O ( n ).
Triplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. For heads of IT/Engineering responsible for building an analytics infrastructure , Etleap is an ETL solution for creating perfect data pipelines from day one. Who's Hiring?
Another key theme at Dynatrace Perform 2024 is organizations’ growing adoption of platform engineering , which helps accelerate the delivery of software applications. Platform engineering improves developer productivity by providing self-service capabilities with automated infrastructure operations.
Triplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Join Etleap , an Amazon Redshift ETL tool to learn the latest trends in designing a modern analytics infrastructure. Who's Hiring? Make your job search O (1), not O ( n ).
About two years ago, we, at our newly formed Machine Learning Infrastructure team started asking our data scientists a question: “What is the hardest thing for you as a data scientist at Netflix?” mainly because of mundane reasons related to softwareengineering. like they would do in a Jupyter notebook.
Senior DevOps Engineer : Your engineering work will focus on using your deep knowledge of the web stack including firewalls, web applications, caches and data stores to create innovative infrastructure architectures that are resilient, scalable, and blazingly fast. Please apply here. Please apply here. Apply here.
Triplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Shape the future of software in your industry. Receive occasional invitations to chat with for 30 minutes about your area of expertise and software usage. Who's Hiring?
Triplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Join Etleap , an Amazon Redshift ETL tool to learn the latest trends in designing a modern analytics infrastructure. Who's Hiring? Make your job search O (1), not O ( n ).
Triplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. For heads of IT/Engineering responsible for building an analytics infrastructure , Etleap is an ETL solution for creating perfect data pipelines from day one. Who's Hiring?
Triplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. For heads of IT/Engineering responsible for building an analytics infrastructure , Etleap is an ETL solution for creating perfect data pipelines from day one. Who's Hiring?
Triplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Shape the future of software in your industry. Receive occasional invitations to chat with for 30 minutes about your area of expertise and software usage. Who's Hiring?
Site reliability engineering (SRE) is a software operations methodology that enables organizations to create highly reliable and scalable applications. SRE applies softwareengineering principles to operations and infrastructure processes. Site reliability engineers, or SREs, lead these efforts.
Engineers will be tasked with building new products and features to solve business and ecommerce challenges as we're dealing with engaging problems at a massive scale and will create solutions that impact millions of people around the world. Client libraries are available for Node, Ruby, Python, PHP, Go, Java and.NET. Apply here.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































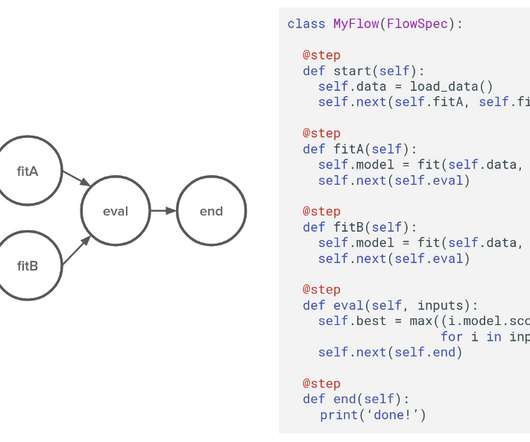












Let's personalize your content