This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. But is five nines availability attainable? What is always-on infrastructure?
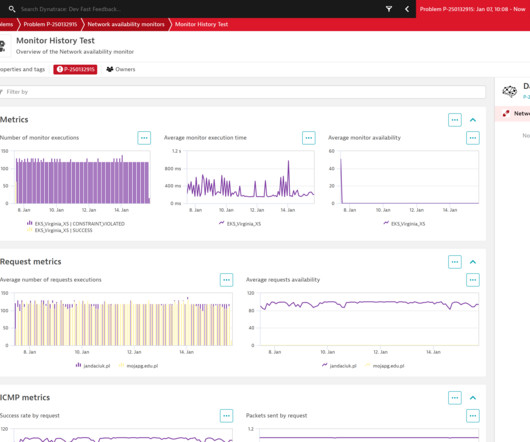
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Our script, available on GitHub , provides details. into NAM test definitions.
As modern multicloud environments become more distributed and complex, having real-time insights into applications and infrastructure while keeping data residency in local markets is crucial. As of October 2024, Dynatrace is available on Microsoft Azure Australia East region, enabling joint customers to maintain a local SaaS presence.
In today's world, the need for highly available and fault-tolerant systems is more important than ever. Furthermore, with the increased adoption of microservices and containerization , the need for a reliable infrastructure that can automatically detect and recover from failures has become critical.
Expectations for network monitoring In today’s digital landscape, businesses rely heavily on their IT infrastructure to deliver seamless services to customers. The market demands a robust solution that can monitor applications and the underlying network infrastructure to ensure end-to-end availability and performance.
In September, we announced the availability of the Dynatrace Software Intelligence Platform on Microsoft Azure as a SaaS solution and natively in the Azure portal. Today, we are excited to provide an update that Dynatrace SaaS on Azure is now generally available (GA) to the public through Dynatrace sales channels. Dynatrace news.
To solve this problem , Dynatrace offers a fully automated approach to infrastructure and application observability including Kubernetes control plane, deployments, pods, nodes, and a wide array of cloud-native technologies. None of this complexity is exposed to application and infrastructure teams.
Forbes estimates that cloud budgets will break all previous records as businesses will spend over $1 trillion on cloud computing infrastructure in 2024. By integrating observability tools in CI/CD pipelines, organizations can increase deployment frequency, minimize risks, and build highly available systems.
An hourly rate for Infrastructure Monitoring The Dynatrace Platform Subscription (DPS) offers a flat rate for Infrastructure Monitoring , providing observability for cloud platforms, containers, networks, and data center technologies with no limits on host memory and with AIOps included.
Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. With Dashboards , you can monitor business performance, user interactions, security vulnerabilities, IT infrastructure health, and so much more, all in real time.
However, this category requires near-immediate access to the current count at low latencies, all while keeping infrastructure costs to a minimum. Eventually Consistent : This category needs accurate and durable counts, and is willing to tolerate a slight delay in accuracy and a slightly higher infrastructure cost as a trade-off.
.” While this methodology extends to every layer of the IT stack, infrastructure as code (IAC) is the most prominent example. Here, we’ll tackle the basics, benefits, and best practices of IAC, as well as choosing infrastructure-as-code tools for your organization. What is infrastructure as code? Consistency.
Dynatrace with Red Hat OpenShift monitoring stands out for the following reasons: With infrastructure health monitoring and optimization, you can assess the status of your infrastructure at a glance to understand resource consumption and thus optimize resource allocation for cost efficiency.
On the other hand, Tenable focuses on infrastructure, conducting comprehensive scans of hosts, web applications, and compliance checks. This division can lead to alert noise from critical security findings in infrastructure, which might not always be relevant to your production environment and applications.
However, the extended infrastructure of CDNs requires diligent monitoring to ensure optimal performance and identify potential issues. CDN observability refers to gaining insights into the CDN infrastructure's performance, availability, and reliability. What Is CDN Observability?
More than 90% of enterprises now rely on a hybrid cloud infrastructure to deliver innovative digital services and capture new markets. That’s because cloud platforms offer flexibility and extensibility for an organization’s existing infrastructure. Dynatrace news. With public clouds, multiple organizations share resources.
Streamlining observability with Dynatrace OneAgent on AWS Image Builder In our ongoing collaboration with AWS, we’re excited to make the Dynatrace OneAgent available as a first-class integration on AWS Image Builder via the AWS Marketplace.
Infrastructure and operations teams must maintain infrastructure health for IT environments. With the Infrastructure & Operations app ITOps teams can quickly track down performance issues at their source, in the problematic infrastructure entities, by following items indicated in red. What’s next?
Thats why Dynatrace will make its AI-powered, unified observability platform generally available on Google Cloud for all customers later this year. The power of Dynatrace unified observability on Google Cloud By the end of June, the latest Dynatrace core innovations will be available on Google Cloud, including the following: Dynatrace Grail.
Take your monitoring, data exploration, and storytelling to the next level with outstanding data visualization All your applications and underlying infrastructure produce vast volumes of data that you need to monitor or analyze for insights. Infrastructure health: A honeycomb chart is often used to visualize infrastructure health.
Dynatrace integrates application performance monitoring (APM), infrastructure monitoring, and real-user monitoring (RUM) into a single platform, with its Foundation & Discovery mode offering a cost-effective, unified view of the entire infrastructure, including non-critical applications previously monitored using legacy APM tools.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. While the SLO management web UI and API are already available, the dashboard tile will be released within the next weeks.
Managing High Availability (HA) in your PostgreSQL hosting is very important to ensuring your database deployment clusters maintain exceptional uptime and strong operational performance so your data is always available to your application. Effective management of failover and switchover operations is crucial for high availability.
The end goal, of course, is to optimize the availability of organizations’ software. Dynatrace is widely recognized for its AI capabilities’ ability to predict and prevent issues, and automatically identify root causes, maximizing availability. Eventually, the goal is to arrive at self-healing through autonomous cloud operations.
The importance of critical infrastructure and services While digital government is necessary, protecting critical infrastructure and services is equally important. Critical infrastructure and services refer to the systems, facilities, and assets vital for the functioning of society and the economy.
As file sizes grow and workflows become more complex, these issues are magnified, leading to inefficiencies that slow down post-production and reduce the available time spent on creativework. Depending on the market, or production budget, cutting-edge technology might not be available or affordable. So what isit?
In this blog, I would like to share a few best practices for creating High Available (HA) Applications in Mule 4 from an infrastructure perspective ONLY ( CloudHub in this article refers to CloudHub 1.0 Most of the configuration details (only relevant to HA) shared here are taken from MuleSoft Documentation/Articles/Blogs.
This is partly due to the complexity of instrumenting and analyzing emissions across diverse cloud and on-premises infrastructures. Integration with existing systems and processes : Integration with existing IT infrastructure, observability solutions, and workflows often requires significant investment and customization.
Dynatrace, available as an Azure-native service , has a longstanding partnership with Microsoft, deeply rooted in a strong “build with” approach to deliver seamless user experience. This enables Dynatrace customers to achieve faster time-to-value and accelerate innovation.
Track business metrics, key performance indicators (KPIs), and service level objectives (SLOs) — automatically and in context with IT infrastructure and services — to promote collaboration between business and IT teams. Two of the most important categories are: Business reporting, analytics, and automation.
Boost your operational resilience: Combining availability and security is now essential. Configuration and Compliance , adding the configuration layer security to both applications and infrastructure and connecting it to compliance. Its time to adopt a unified observability and security approach.
By gaining insights into how your Kubernetes workloads utilize computing and memory resources, you can make informed decisions about how to size and plan your infrastructure, leading to reduced costs. These out-of-the-box templates and their visualization within the Kubernetes app will be available early next year.
This blog post explains how Dynatrace simplifies log ingestion, whether youre onboarding logs from your infrastructure using OneAgent, cloud services using log forwarding, or driving open-source standardization leveraging OpenTelemetry (OTel), Fluent Bit, or any other API-based ingestion methods.
Ensuring smooth operations is no small feat, whether you’re in charge of application performance, IT infrastructure, or business processes. Activate Davis AI to analyze charts within seconds Davis AI can help you expand your dashboards and dive deeper into your available data to extract additional information.
With more organizations taking the multicloud plunge, monitoring cloud infrastructure is critical to ensure all components of the cloud computing stack are available, high-performing, and secure. Website monitoring examines a cloud-hosted website’s processes, traffic, availability, and resource use. Website monitoring.
address these limitations and brings new monitoring and analytical capabilities that weren’t available to Extensions 1.0: are automatically distributed to a group of ActiveGates, balancing the load automatically and switching workloads in case of infrastructure failure, to assure continued monitoring execution. Extensions 2.0
Its design prioritizes high availability and efficient data transfer with minimal overhead, making it a practical choice for handling real-time data pipelines and distributed event processing. It follows a push-based approach, ensuring messages are distributed to consumers as soon as they become available.
Site reliability engineering (SRE) plays a vital role in ensuring Java applications' high availability, performance, and scalability. This discipline merges software engineering and operations, aiming to create a robust infrastructure that supports seamless user experiences.
You can either continue with the custom infrastructure metrics dashboard you created in Part I or use the dashboard we prepared here (Dynatrace login required). exploring your data when you know your desired outcome but are unfamiliar with the available data.
With the many observability options available from Dynatrace, you can seamlessly monitor hybrid Kubernetes environments in a unified platform, gaining end-to-end visibility across both operating systems and the underlying cluster. The containers list as individual PaaS hosts after successful deployment.
Challenges The cloud network infrastructure that Netflix utilizes today consists of AWS services such as VPC, DirectConnect, VPC Peering, Transit Gateways, NAT Gateways, etc and Netflix owned devices. These metrics are visualized using Lumen , a self-service dashboarding infrastructure.
In this blog post, youll learn how Dynatrace OneAgent automatically identifies Journald and ingests structured logs into Dynatrace while enriching them with topology and infrastructure context. Why migrate from Syslog to Journald Journald provides a more modern alternative that addresses the limitations of existing Syslog implementations.
Navigate digital infrastructure complexity In today’s rapidly evolving digital environment, organizations face increasing pressure from customers and competitors to deliver faster, more secure innovations. Use case: Digital infrastructure change The problem is not always in the application.
These include traditional on-premises network devices and servers for infrastructure applications like databases, websites, or email. Without seeing syslog data in the context of your infrastructure, metrics, and transaction traces, you’re slowed down by manual work with siloed data. Setting up your first Environment ActiveGate?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content