This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
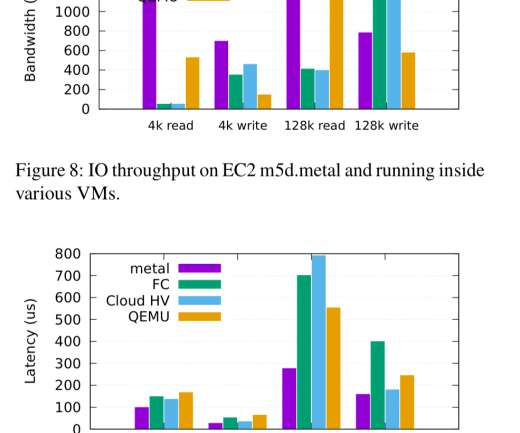
At Netflix, we periodically reevaluate our workloads to optimize utilization of available capacity. While we understand it’s virtually impossible to achieve a linear increase in throughput as the number of vCPUs grow, a near-linear increase is attainable. We decided to move one of our Java microservices?—?let’s let’s call it GS2?—?to
Microsoft Hyper-V is a virtualization platform that manages virtual machines (VMs) on Windows-based systems. It enables multiple operating systems to run simultaneously on the same physical hardware and integrates closely with Windows-hosted services. This leads to a more efficient and streamlined experience for users.
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operating system, CPU cycles, and memory. VMware commercialized the idea of virtual machines, and cloud providers embraced the same concept with services like Amazon EC2, Google Compute, and Azure virtual machines.
This transition to public, private, and hybrid cloud is driving organizations to automate and virtualize IT operations to lower costs and optimize cloud processes and systems. Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure.
They use the same hardware, APIs, tools, and management controls for both the public and private clouds. Five available hybrid cloud platforms from the top public cloud providers include the following: Azure Stack : Consumers can access different Azure cloud services from their own data center and build applications for Azure cloud.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
Accordingly, the remaining 27% of clusters are self-managed by the customer on cloud virtual machines. On-premises data centers invest in higher capacity servers since they provide more flexibility in the long run, while the procurement price of hardware is only one of many cost factors.
We looked at a couple of papers that had pre-prints available last week, today we’ll be looking at one of the most anticipated papers of this year’s crop: Amazon’s Firecracker. Firecracker is the virtual machine monitor (VMM) that powers AWS Lambda and AWS Fargate, and has been used in production at AWS since 2018.
Each of these models is suitable for production deployments and high traffic applications, and are available for all of our supported databases, including MySQL , PostgreSQL , Redis™ and MongoDB® database ( Greenplum® database coming soon). Here are the databases and cloud providers supported through each model: Supported Databases.
When it comes to access to their applications, users demand instant, reliable, and secure interactions — and that means databases must be highly available. With database high availability (HA), services are largely uninterrupted, and end users are largely satisfied. The obvious answer is this: To achieve high availability.
Cloud providers then manage physical hardware, virtual machines, and web server software management. Increased availability. Because FaaS is a cloud-native approach, it makes great use of multisite cloud architecture to improve availability and reliability. Consider the challenges of function as a service.
However, that assumes he or she is available and has time to talk. Without it, sending an email over a long distance would require the immediate availability of every node on the routing network to forward each message. The concept is like text messaging — a feature most mobile phone users understand. Two styles of message queuing.
However, that assumes he or she is available and has time to talk. Without it, sending an email over a long distance would require the immediate availability of every node on the routing network to forward each message. The concept is like text messaging — a feature most mobile phone users understand. Two styles of message queuing.
With so much at stake, database high availability and fault tolerance have become must-have items, but many companies just aren’t certain which one they must have. This blog article will examine shared attributes of high availability (HA) and fault tolerance (FT). What does high availability mean?
This removes the burden of purchasing and maintaining your hardware, storage and networking infrastructure, while still giving you a very familiar experience with Windows and SQL Server itself. One important choice you will still have to make is what type and size of Azure virtual machine you want to use for your existing SQL Server workload.
With the average cost of unplanned downtime running from $300,000 to $500,000 per hour , businesses are increasingly using high availability (HA) technologies to maximize application uptime. Where a high availability design once worked well, it can no longer keep up with more complex requirements. there cannot be high availability.
Organizations hit this cloud operations wall when replacing static virtual machines with dynamic container orchestration and expanding to multicloud environments. While modern cloud systems simplify tasks — such as deploying apps and provisioning new hardware and servers — cloud environments can be surprisingly complex.
Lift & Shift is where you basically just move physical or virtual hosts to the cloud – essentially you just run your host on somebody else’s hardware. All available in Dynatrace in the UI or through the API! if you have a feature that relies on dedicated hardware and that users only execute once per week (e.g:
But we couldn’t adopt the old style approach of upgrading systems through a maintenance outage, as many businesses around the world are relying on our platform for 24/7 availability. This is a given, whether you are using the highest quality hardware or lowest cost components. Primitives not frameworks.
Instead of diving in arguing about specific points (which I partly did in my earlier post – start from The Future of Performance Testing if you are interested), I decided to talk to people who monetize on these “myths” So here is a virtual interview with Guillaume Betaillouloux , co-founder and Performance Director of OctoPerf.
When it comes to hardware support to mitigate software security issues, there is a significant gap between what is available in products today and known solutions. Acceleration—Adding hardware support to reduce the runtime overheads of security features. hardware support for malware detection/prevention).
These systems are a combination of different hardware and software which have been configured to perform the desired task. Configuration testing is performed to discover the optimum combinations of software and hardware specifications that allow the system to work without flaws. Types of Configuration Testing.
Balancing Low Latency, High Availability and Cloud Choice Cloud hosting is no longer just an option — it’s now, in many cases, the default choice. Let’s look at the top cloud computing use cases, the use cases for which cloud probably isn’t the best route available, and the use cases where a hybrid approach may be best.
Chatbots and virtual assistants Chatbots and virtual assistants are becoming more common on websites and web applications as they provide an efficient and convenient way for users to interact with a business. These technologies can answer questions, provide customer support, or even complete transactions.
A scalable architecture needs to distribute work across many threads in order to facilitate all the CPUs of a physical or virtual machine. Ultimately, it leads to a state where your system won’t be able to process more data even if you add more hardware. Now let’s see how this works for the two use cases mentioned earlier.
EPU: Emotion Processing Unit is designed by Emoshape , as the MCU microchip design to enable a true emotional response in AI, robots and consumer electronic devices as a result of a virtually unlimited cognitive process. HPU: Holographic Processing Unit (HPU) is the specific hardware of Microsoft’s Hololens.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. Variations within these storage systems are called distributed file systems.
There were five trends and topics for 2021, Serverless First, Chaos Engineering, Wardley Mapping, Huge Hardware, Sustainability. I’d even use it to manage datacenter failover or failover for other cloud vendors, as what you really need is a highly available control plane that is totally independent of your own failure modes.
On May 8, OReilly Media will be hosting Coding with AI: The End of Software Development as We Know It a live virtual tech conference spotlighting how AI is already supercharging developers, boosting productivity, and providing real value to their organizations.
It is very gratifying to see all of our learning and experience become available to our customers in the form of an easy-to-use managed service. It provides multi-data center replication, high availability, and offers rock-solid durability. Customers can typically achieve average service-side in the single-digit milliseconds.
The main change last week is that the committee decided to postpone supporting contracts on virtual functions; work will continue on that and other extensions. Standardization is still important, of course, because it makes these improvements available portably, with portable guarantees for C++ code on all platforms. Thanks, Ben!
This post mines publicly available data on the pace of compatibility fixes and feature additions to assess the claim. The information it captures is, however, available going back somewhat further, providing a fuller picture of the trend lines of engine completeness. Count of APIs available from JavaScript by Web Confluence.
This paper presents Snowflake design and implementation along with a discussion on how recent changes in cloud infrastructure (emerging hardware, fine-grained billing, etc.) Tenant isolation is achieved by provisioning a separate virtual warehouse (VW) for each tenant. From shared-nothing to disaggregation. Workload characteristics.
Inside the memory, they can be allocated any available space. When a program leaves the memory, space becomes available; however, the OS may or may not be able to allocate vacant memory space to another program or process as it has some issues. The next version of the pg_gather will have these details available.
Last week we saw the benefits of rethinking memory and pointer models at the hardware level when it came to object storage and compression ( Zippads ). The protections are hardware implemented and cannot be forged in software. At hardware reset the boot code is granted maximally permissive architectural capabilities.
CLI tools The Cassandra systems were EC2 virtual machine (Xen) instances. As a Xen guest, this profile was gathered using perf(1) and the kernel's software cpu-clock soft interrupts, not the hardware NMI. Note that Ubuntu also has a frame to show entry into vDSO (virtual dynamic shared object). But I'm not completely sure.
Both concepts are virtually omnipresent and at the top of most buzzword rankings. As a result, there is a critical mass of data available. The management consultants at McKinsey expect that the global market for AI-based services, software and hardware will grow annually by 15-25% and reach a volume of around USD 130 billion in 2025.
A year after the first web servers became available, how many companies had websites or were experimenting with building them? That pricing won’t be sustainable, particularly as hardware shortages drive up the cost of building infrastructure. Certainly not two-thirds of them. We expect search to be everywhere. AI will be the same.
To address these challenges, architects must design robust and scalable MongoDB databases and adopt appropriate sharding strategies that can efficiently handle increasing workloads while ensuring continuous availability. Sharding is a preferred approach for database systems facing substantial growth and needing high availability.
cpupower frequency-info analyzing CPU 0: driver: intel_pstate CPUs which run at the same hardware frequency: 0 CPUs which need to have their frequency coordinated by software: 0 maximum transition latency: Cannot determine or is not supported. hardware limits: 1000 MHz - 4.00 hardware limits: 1000 MHz - 4.00
This technique saves two instructions in the prologue and epilogue and makes one additional general-purpose register (%rbp) available." It was also a virtual machine that lacked low-level hardware profiling capabilities, so I wasn't able to do cycle analysis to confirm that the 10% was entirely frame pointer-based.
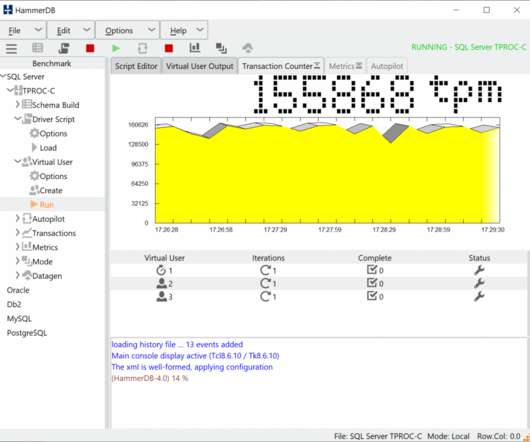
It enables the user to measure database performance and make comparative judgements about database hardware and software. These factors meant that often when looking for database performance information, the results for a particular combination of software and hardware were not available. What is HammerDB? Supported Databases.
To benchmark a database we introduce the concept of a Virtual User. We could use processes, however given we may want to create hundreds or thousands of virtual users multithreading is the best approach to implement a Virtual User. Basic Benchmarking Concepts. The Python GIL. Tcl Multithreading in parallel.
Fast forward a few years after Azure SQL Database was released to when Azure SQL Managed Instance was in public preview, and "vCores" (virtual cores) were announced for Azure SQL Database. Gen 5 is the primary hardware option now for most regions since Gen 4 is aging out. New Hardware Configuration for Provisioned Compute Tier.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content