This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. But is five nines availability attainable? Downtime per year. 90% (one nine).
Dynatrace Managed is intrinsically highly available as it stores three copies of all events, user sessions, and metrics across its cluster nodes. Our Premium High Availability comes with the following features: Active-active deployment model for optimum hardware utilization. Dynatrace news. Self-contained turnkey solution.
IBM Z and LinuxONE mainframes running the Linux operating system enable you to respond faster to business demands, protect data from core to cloud, and streamline insights and automation. Dynatrace observability is available for Red Hat OpenShift on IBM Power. Learn more about the new Kubernetes Experience for Platform Engineering.
Dynatrace Managed now available on the Google Cloud Platform. Since each node should have the same hardware configuration, you only need to do this once as it will then be applied to each and every node. For more details, see Dynatrace Managed hardware and systems requirements.
Managing High Availability (HA) in your PostgreSQL hosting is very important to ensuring your database deployment clusters maintain exceptional uptime and strong operational performance so your data is always available to your application. Effective management of failover and switchover operations is crucial for high availability.
Having released this functionality in an Early Adopter Release with OneAgent version 1.173 and Dynatrace version 1.174 back in August 2019, we’re now happy to announce the General Availability of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux. Host-performance measures.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges.
Building resilient systems requires comprehensive error management. Errors could occur in any part of the system / or its ecosystem and there are different ways of handling these e.g. Datacenter - data center failure where the whole DC could become unavailable due to power failure, network connectivity failure, environmental catastrophe, etc.
We’re happy to announce the Early Adopter Release of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux (available with OneAgent version 1.173 and Dynatrace version 1.174). For details on available metrics, see our help page on host performance monitoring.
Do you keep an eye on the support of distributions and versions of operating systems within your environment? With this information, you can find answers to questions such as: Which operating systems and versions does Dynatrace support? Which operating systems and versions does Dynatrace support? What about ActiveGates?
Microsoft Hyper-V is a virtualization platform that manages virtual machines (VMs) on Windows-based systems. It enables multiple operating systems to run simultaneously on the same physical hardware and integrates closely with Windows-hosted services. This leads to a more efficient and streamlined experience for users.
At Intel we've been creating a new analyzer tool to help reduce AI costs called AI Flame Graphs : a visualization that shows an AI accelerator or GPU hardware profile along with the full software stack, based on my CPU flame graphs. Programs that exist in the file system. The towers are getting smaller as optimizations are added.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. Some disruption might occur, but it will be minimal.
Greenplum Database is an open-source , hardware-agnostic MPP database for analytics, based on PostgreSQL and developed by Pivotal who was later acquired by VMware. The MPP system leverages a shared-nothing architecture to handle multiple operations in parallel. Typically an MPP system has one leader node and one or many compute nodes.
Introduction to Message Brokers Message brokers enable applications, services, and systems to communicate by acting as intermediaries between senders and receivers. This decoupling simplifies system architecture and supports scalability in distributed environments.
Since we moved to AWS in May 2014 we have had an availability of 99.95%! It was on August 25 th at 14:00 when Davis initially alerted on a disk write latency issues to Elastic File System (EFS) on one of our EC2 instances in AWS’s Sydney Data Center. Sydney, we have a disk write latency problem!
When an application runs on a single large computing element, a single operating system can monitor every aspect of the system. Modern operating systems provide capabilities to observe and report various metrics about the applications running. Just as the code is monolithic, so is the logging.
Understanding sustained memory bandwidth in these systems starts with assuming 100% utilization and then reviewing the factors that get in the way (e.g., This requires a completely different approach to modeling the memory system — one based on Little’s Law from queueing theory. cache lines -> 5.6 cache lines -> 5.6
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. This guide delves into how these systems work, the challenges they solve, and their essential role in businesses and technology.
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operating system, CPU cycles, and memory. There is no need to plan for extra resources, update operating systems, or install frameworks. The provider is essentially your system administrator. What is serverless computing?
Infrastructure health The underlying infrastructure’s health directly impacts application availability and performance. Vulnerabilities or hardware failures can disrupt deployments and compromise application security. Start your journey with Keptn by downloading the first Release Candidate for v2 available now on GitHub.
Ensuring your monitoring system stays up and running is vital. High availability (HA) minimizes downtime for Percona Monitoring and Management (PMM) during hardware failures, in times of disaster recovery, or increased usage of the tool.
This transition to public, private, and hybrid cloud is driving organizations to automate and virtualize IT operations to lower costs and optimize cloud processes and systems. Besides the traditional systemhardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure.
When it comes to access to their applications, users demand instant, reliable, and secure interactions — and that means databases must be highly available. With database high availability (HA), services are largely uninterrupted, and end users are largely satisfied. The obvious answer is this: To achieve high availability.
Enhanced customer confidence through excellent service availability. If your organisation is involved in achieving APRA compliance, you are likely facing the daunting effort of de-risking critical system delivery. Moreover, for banking organisations, there is a good chance some of those systems are outdated.
As Kubernetes adoption increases and it continues to advance technologically, Kubernetes has emerged as the “operating system” of the cloud. Kubernetes is emerging as the “operating system” of the cloud. Kubernetes is emerging as the “operating system” of the cloud. Kubernetes moved to the cloud in 2022.
Test tools are software or hardware designed to test a system or application. Various test tools are available for different types of testing, including unit testing, integration testing, and more. In addition to automating testing tasks, test tools can produce test data, monitor system performance, and report on test results.
Oracle Database is a commercial, proprietary multi-model database management system produced by Oracle Corporation, and the largest relational database management system (RDBMS) in the world. Compare PostgreSQL vs. Oracle functionality across available tools, capabilities and services. Not available. Not available.
AWS Lambda enables organizations to access many types of functions from AWS’ cloud-based services, such as: Data processing, to execute code based on triggers, system states, or user actions. You will likely need to write code to integrate systems and handle complex tasks or incoming network requests.
With so much at stake, database high availability and fault tolerance have become must-have items, but many companies just aren’t certain which one they must have. This blog article will examine shared attributes of high availability (HA) and fault tolerance (FT). What does high availability mean?
A message queue is a form of middleware used in software development to enable communications between services, programs, and dissimilar components, such as operating systems and communication protocols. A message queue enables the smooth flow of information to make complex systems work. Two styles of message queuing.
A message queue is a form of middleware used in software development to enable communications between services, programs, and dissimilar components, such as operating systems and communication protocols. A message queue enables the smooth flow of information to make complex systems work. Two styles of message queuing.
Cloud migration is the process of transferring some or all your data, software, and operations to a cloud-based computing environment that offers unlimited scale and high availability. They need enough hardware to serve their anticipated volume and keep things running smoothly without buying too much or too little. Reduced cost.
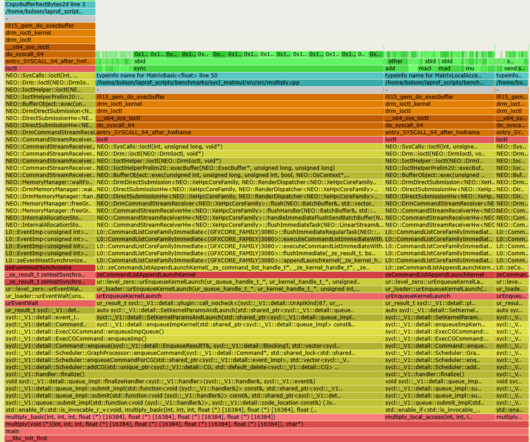
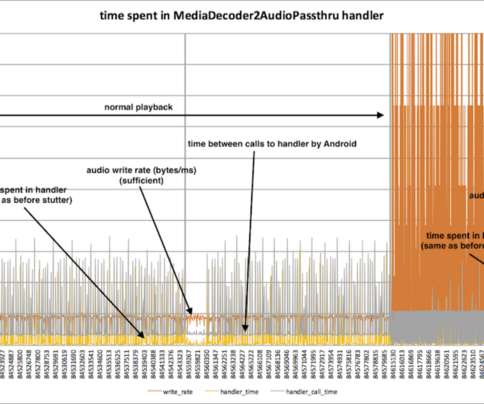
All four players involved in the device were on the call: there was the large European pay TV company (the operator) launching the device, the contractor integrating the set-top-box firmware (the integrator), the system-on-a-chip provider (the chip vendor), and myself (Netflix). This phase is buffering, before playback starts.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Simplicity.
There’s no other competing software that can provide this level of value with minimum effort and optimal hardware utilization that can scale up to web-scale! We’re continuously investing in performance optimizations, high availability, and resilience for Dynatrace Managed deployments. Support for high memory instances.
We were able to meaningfully improve both the predictability and performance of these containers by taking some of the CPU isolation responsibility away from the operating system and moving towards a data driven solution involving combinatorial optimization and machine learning. We want to extend the system to support CPU oversubscription.
Teams can then act before attackers have the chance to compromise key data or bring down critical systems. This data helps teams see where attacks began, which systems were targeted, and what techniques attackers used. Proactive protection, however, focuses on finding evidence of attacks before they compromise key systems.
They use the same hardware, APIs, tools, and management controls for both the public and private clouds. Five available hybrid cloud platforms from the top public cloud providers include the following: Azure Stack : Consumers can access different Azure cloud services from their own data center and build applications for Azure cloud.
We designed DynamoDB to operate with at least 99.999% availability. More than a decade ago, Amazon embarked on a mission to build a distributed system that challenged conventional methods of data storage and querying. These databases trade off complex querying capabilities and consistency for scale and availability.
Cloud providers then manage physical hardware, virtual machines, and web server software management. Increased availability. Because FaaS is a cloud-native approach, it makes great use of multisite cloud architecture to improve availability and reliability. Consider the challenges of function as a service. Limited visibility.
Think of containers as the packaging for microservices that separate the content from its environment – the underlying operating system and infrastructure. It becomes immediately clear there must be number of mechanisms in place to coordinate such a distributed system. In production, containers are easy to replicate.
Additionally, ITOA gathers and processes information from applications, services, networks, operating systems, and cloud infrastructure hardware logs in real time. Operations analytics ensures IT systems perform as expected. ITOA can evaluate operating system functions and reduce costs with optimized IT resource management.
These metrics help to keep a network system up and running?, Containment: Implements actions to safeguard affected systems, resolves incidents quickly and escalates an event to other teams when necessary. Maintenance: Reduces the risk of an incident occurring again with root-cause analysis and continuous improvements to the system.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content