This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dynatrace Managed is intrinsically highly available as it stores three copies of all events, user sessions, and metrics across its cluster nodes. This means that Dynatrace continues full operation when a majority of nodes are up and a maximum of two nodes are down at a time. Dynatrace news. Self-contained turnkey solution.
As we did with IBM Power , we’re delighted to share that IBM and Dynatrace have joined forces to bring the Dynatrace Operator, along with the comprehensive capabilities of the Dynatrace platform, to Red Hat OpenShift on the IBM Z and LinuxONE architecture (s390x). Dynatrace observability is available for Red Hat OpenShift on IBM Power.
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. But is five nines availability attainable? Downtime per year. 90% (one nine).
Having released this functionality in an Early Adopter Release with OneAgent version 1.173 and Dynatrace version 1.174 back in August 2019, we’re now happy to announce the General Availability of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux. Host-performance measures.
Do you keep an eye on the support of distributions and versions of operatingsystems within your environment? With this information, you can find answers to questions such as: Which operatingsystems and versions does Dynatrace support? Which operatingsystems and versions does Dynatrace support?
Hyper-V plays a vital role in ensuring the reliable operations of data centers that are based on Microsoft platforms. Microsoft Hyper-V is a virtualization platform that manages virtual machines (VMs) on Windows-based systems. This leads to a more efficient and streamlined experience for users.
We’re happy to announce the Early Adopter Release of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux (available with OneAgent version 1.173 and Dynatrace version 1.174). For details on available metrics, see our help page on host performance monitoring.
When an application runs on a single large computing element, a single operatingsystem can monitor every aspect of the system. Modern operatingsystems provide capabilities to observe and report various metrics about the applications running. Just as the code is monolithic, so is the logging.
As Kubernetes adoption increases and it continues to advance technologically, Kubernetes has emerged as the “operatingsystem” of the cloud. Kubernetes is emerging as the “operatingsystem” of the cloud. Kubernetes is emerging as the “operatingsystem” of the cloud. Kubernetes moved to the cloud in 2022.
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operatingsystem, CPU cycles, and memory. There is no need to plan for extra resources, update operatingsystems, or install frameworks. The provider is essentially your system administrator.
Compare PostgreSQL vs. Oracle functionality across available tools, capabilities and services. Compare ease of use across compatibility, extensions, tuning, operatingsystems, languages and support providers. PostgreSQL is an open source object-relational database system with over 30 years of active development.
ITOA automates repetitive cloud operations tasks and streamlines the flow of analytics into decision-making processes. Additionally, ITOA gathers and processes information from applications, services, networks, operatingsystems, and cloud infrastructure hardware logs in real time.
You will likely need to write code to integrate systems and handle complex tasks or incoming network requests. As a bonus, operations staff never needs to update operatingsystems or hardware, because AWS manages servers with no stoppage of application functionality. How does AWS Lambda work?
A message queue is a form of middleware used in software development to enable communications between services, programs, and dissimilar components, such as operatingsystems and communication protocols. A message queue enables the smooth flow of information to make complex systems work. Two styles of message queuing.
A message queue is a form of middleware used in software development to enable communications between services, programs, and dissimilar components, such as operatingsystems and communication protocols. A message queue enables the smooth flow of information to make complex systems work. Two styles of message queuing.
Think of containers as the packaging for microservices that separate the content from its environment – the underlying operatingsystem and infrastructure. Initially developed by Google, it’s now available in many distributions and widely supported by all public cloud vendors.
We were able to meaningfully improve both the predictability and performance of these containers by taking some of the CPU isolation responsibility away from the operatingsystem and moving towards a data driven solution involving combinatorial optimization and machine learning.
We had some fun getting hardware figured out, and I used a 3D printer to make some cases, but the whole project was interrupted by the delivery of the iPhone by Apple in late 2007. Reed wanted to know if we should do it, and whether it was possible in the time available?
A log is a detailed, timestamped record of an event generated by an operatingsystem, computing environment, application, server, or network device. Logs can include data about user inputs, system processes, and hardware states. “Logging” is the practice of generating and storing logs for later analysis.
We continue to grow our public synthetic monitoring locations, but customers using Dynatrace Synthetic still need to monitor the performance and availability of internal web applications. With private synthetic browser monitors, we bring the testing capabilities available in public locations right into your own environment.
In contrast, observability enables teams to understand a system’s internal state by analyzing the data it generates, including logs, metrics, and traces. Every hardware, software, cloud infrastructure component, container, open source tool, and microservice generates records of every activity within modern environments.
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. Operatingsystem Linux is the most common operatingsystem for high-performance MySQL servers.
A software tester’s work life includes making sure that systems that have been designed to achieve specific results behave exactly as they should. These systems are a combination of different hardware and software which have been configured to perform the desired task. An Example. Types of Configuration Testing.
For medium to large scale applications, compatible with all commonly availableoperatingsystems and internet browsers is essential. Hardware Compatibility Testing: In this scenario, an application is tested against various hardware configurations to check behavior. Missing content and overlapping.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. Variations within these storage systems are called distributed file systems.
But we couldn’t adopt the old style approach of upgrading systems through a maintenance outage, as many businesses around the world are relying on our platform for 24/7 availability. This is a given, whether you are using the highest quality hardware or lowest cost components. Primitives not frameworks. No gatekeepers.
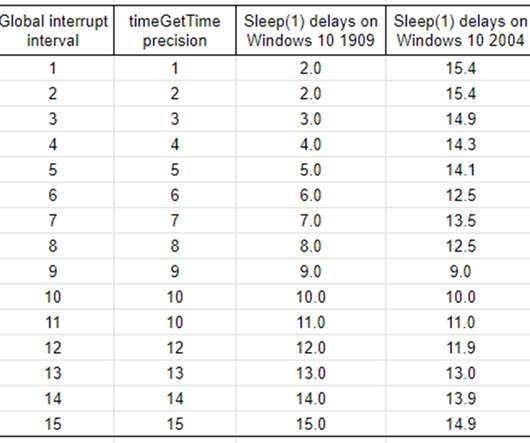
First, a bit of operating-system design context. Ideally the CPU goes to sleep when Sleep(1) is called, in order to save power, so how does the operatingsystem (OS) wake your thread if the CPU is sleeping? The answer is hardware interrupts. Timer interrupts and their raison d’être.
To achieve optimal tracking results it is important to choose wisely among available tools like Prometheus or Grafana, which offer deeper insights into understanding your Redis instances for better performance optimization. Or even having limitations when trying vertical/horizontal scalability while ensuring availability at all times.
There were five trends and topics for 2021, Serverless First, Chaos Engineering, Wardley Mapping, Huge Hardware, Sustainability. I’d even use it to manage datacenter failover or failover for other cloud vendors, as what you really need is a highly available control plane that is totally independent of your own failure modes.
When it comes to hardware support to mitigate software security issues, there is a significant gap between what is available in products today and known solutions. Attestation—Providing systems the means to attest or verify the integrity of their components. hardware support for malware detection/prevention).
To achieve optimal tracking results it is important to choose wisely among available tools like Prometheus or Grafana, which offer deeper insights into understanding your Redis® instances for better performance optimization. Or even having limitations when trying vertical/horizontal scalability while ensuring availability at all times.
Mobile phones are rapidly becoming touchscreens and touchscreen phones are increasingly all-touch, with the largest possible display area and fewer and fewer hardware buttons. The hardware matters, but the underlying OS is the same , and pretty much all apps will run on any device of the same age. Editor’s Note.
We looked at a couple of papers that had pre-prints available last week, today we’ll be looking at one of the most anticipated papers of this year’s crop: Amazon’s Firecracker. If no slot is currently available for a requested function, the Placement service will allocate a slot using time-based leasing.
It’s important to note that recommended throughput levels may vary depending on factors such as operatingsystem type, network bandwidth availability, and hardware quality. Memory RSS (Resident Set Size) is the number of bytes that the operatingsystem has allocated to Redis.
Standardization is still important, of course, because it makes these improvements available portably, with portable guarantees for C++ code on all platforms. Given that allocation is a costly operation in most operatingsystems, this becomes important in performance-critical environments. Thanks, Ben!
s announcement of Amazon RDS for Microsoft SQL Server and.NET support for AWS Elastic Beanstalk marks another important step in our commitment to increase the flexibility for AWS customers to use the choice of operatingsystem, programming language, development tools and database software that meet their application requirements.
This removes the burden of purchasing and maintaining your hardware, storage and networking infrastructure, while still giving you a very familiar experience with Windows and SQL Server itself. You will still have to maintain your operatingsystem, SQL Server and databases just like you would in an on-premises scenario.
Inside the memory, they can be allocated any available space. When a program leaves the memory, space becomes available; however, the OS may or may not be able to allocate vacant memory space to another program or process as it has some issues. The next version of the pg_gather will have these details available.
This metric is interesting because we don’t always have the luxury of parallelizing every application we run, and our operatingsystems almost always process each call (e.g., Multicore processors have huge amounts of available DRAM bandwidth – maybe it does not even make sense for a single core to try to use that much?
Software and hardware components are autonomous and execute tasks concurrently. Concurrency refers to the system’s ability to carry out multiple tasks in parallel and manage the access and usage of shared resources. Big systems cost big money. Monitoring a Distributed System. Heterogeneity. Fault Tolerance.
Pre-publication gates were valuable when better answers weren't available, but commentators should update their priors to account for hardware and software progress of the past 13 years. Fast forward a decade, and both the software and hardware situations have changed dramatically. Don't like the consequences?
Conventional computers now sport touchscreens and otherwise blur the lines between device types – and between mobile and desktop operatingsystems. Touch Design for Mobile Interfaces presents and shares real information on hardware, people, interactions, and environments. Shipping starting late-December. Print + eBook.
Zswap is readily available and runs as a swap device in the Linux kernel. Using zswap means that no new hardware solutions are required, enabling rapid deployment across clusters. Using zswap means that no new hardware solutions are required, enabling rapid deployment across clusters.
A wide range of users with different operatingsystems, browsers, hardware configurations and other variables provides a wide sample size that helps developers discover as many issues as possible. APM has two primary goals: ensuring application availability and optimizing application performance. Basic server metrics.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content