This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In September, we announced the availability of the Dynatrace Software Intelligence Platform on Microsoft Azure as a SaaS solution and natively in the Azure portal. Today, we are excited to provide an update that Dynatrace SaaS on Azure is now generally available (GA) to the public through Dynatrace sales channels. Dynatrace news.
Managing SNMP devices at scale can be challenging SNMP (Simple Network Management Protocol) provides a standardized framework for monitoring and managing devices on IP networks. Its simplicity, scalability, and compatibility with a wide range of hardware make it an ideal choice for network management across diverse environments.
Dynatrace Managed is intrinsically highly available as it stores three copies of all events, user sessions, and metrics across its cluster nodes. The network latency between cluster nodes should be around 10 ms or less. Minimized cross-data center network traffic. Dynatrace news. Self-contained turnkey solution.
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. But is five nines availability attainable? Downtime per year. 90% (one nine).
Having released this functionality in an Early Adopter Release with OneAgent version 1.173 and Dynatrace version 1.174 back in August 2019, we’re now happy to announce the General Availability of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux. Release details.
Managing High Availability (HA) in your PostgreSQL hosting is very important to ensuring your database deployment clusters maintain exceptional uptime and strong operational performance so your data is always available to your application. Effective management of failover and switchover operations is crucial for high availability.
And there are a lot of monitoring tools available providing all kinds of features and concepts. For example, you can monitor the behavior of your applications, the hardware usage of your server nodes, or even the network traffic between servers.
We continue to grow our public synthetic monitoring locations, but customers using Dynatrace Synthetic still need to monitor the performance and availability of internal web applications. With private synthetic browser monitors, we bring the testing capabilities available in public locations right into your own environment.
Datacenter - data center failure where the whole DC could become unavailable due to power failure, network connectivity failure, environmental catastrophe, etc. Redundancy in power, network, cooling systems, and possibly everything else relevant. this is addressed through monitoring and redundancy. Again the approach here is the same.
We’re happy to announce the Early Adopter Release of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux (available with OneAgent version 1.173 and Dynatrace version 1.174). For details on available metrics, see our help page on host performance monitoring.
It enables multiple operating systems to run simultaneously on the same physical hardware and integrates closely with Windows-hosted services. Firstly, managing virtual networks can be complex as networking in a virtual environment differs significantly from traditional networking.
Implementing clustering and quorum queues in RabbitMQ significantly improves load distribution and data redundancy, ensuring high availability and fault tolerance for messaging services. Classic queues can be used in clusters, emphasizing their behavior during node failures, particularly regarding durability and availability.
It also provides information for organizations setting up high recovery mechanisms for transaction reconciliation and settlement in case of failure, as well as transaction disruption events during a network failure. The fail-over condition arises due to uncontrolled network failure, OS failure, hardware failure or DR drill.
Greenplum Database is an open-source , hardware-agnostic MPP database for analytics, based on PostgreSQL and developed by Pivotal who was later acquired by VMware. Greenplum interconnect is the networking layer of the architecture, and manages communication between the Greenplum segments and master host network infrastructure.
Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure. Although modern cloud systems simplify tasks, such as deploying apps and provisioning new hardware and servers, hybrid cloud and multicloud environments are often complex.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
This centralization means all aspects of the system can share underlying hardware, are generally written in the same programming language, and the operating system level monitoring and diagnostic tools can help developers understand the entire state of the system.
They can also develop proactive security measures capable of stopping threats before they breach network defenses. For example, an organization might use security analytics tools to monitor user behavior and network traffic. But, observability doesn’t stop at simply discovering data across your network.
Container technology is very powerful as small teams can develop and package their application on laptops and then deploy it anywhere into staging or production environments without having to worry about dependencies, configurations, OS, hardware, and so on. Networking. In production, containers are easy to replicate.
This operational data could be gathered from live running infrastructures using software agents, hypervisors, or network logs, for example. Additionally, ITOA gathers and processes information from applications, services, networks, operating systems, and cloud infrastructure hardware logs in real time.
However, that assumes he or she is available and has time to talk. Without it, sending an email over a long distance would require the immediate availability of every node on the routing network to forward each message. The concept is like text messaging — a feature most mobile phone users understand. Watch webinar now!
However, that assumes he or she is available and has time to talk. Without it, sending an email over a long distance would require the immediate availability of every node on the routing network to forward each message. The concept is like text messaging — a feature most mobile phone users understand.
Other distributions like Debian and Fedora are available as well, in addition to other software like VMware, NGINX, Docker, and, of course, Java. This is especially the case with microservices and applications created around multiple tiers, where cheaper hardware alternatives play a significant role in the infrastructure footprint.
These metrics help to keep a network system up and running?, If one system has an MTTR of 24 hours and another has an MTTR of three days with equal time between failures, the first system is more valuable because its availability is higher. MTTF measures the reliability of a network and durability of its hardware.
Enhanced customer confidence through excellent service availability. In modern cloud environments, every piece of hardware, software, cloud infrastructure component, container, open-source tool, and microservice generates records of every activity. Reduced operational costs by avoiding costly incidents.
They use the same hardware, APIs, tools, and management controls for both the public and private clouds. Five available hybrid cloud platforms from the top public cloud providers include the following: Azure Stack : Consumers can access different Azure cloud services from their own data center and build applications for Azure cloud.
Cloud providers then manage physical hardware, virtual machines, and web server software management. Infrastructure as a service (IaaS) handles compute, storage, and network resources. Increased availability. Function as a service is a cloud computing model that runs code in small modular pieces, or microservices.
Cloud migration is the process of transferring some or all your data, software, and operations to a cloud-based computing environment that offers unlimited scale and high availability. They need enough hardware to serve their anticipated volume and keep things running smoothly without buying too much or too little. Reduced cost.
With so much at stake, database high availability and fault tolerance have become must-have items, but many companies just aren’t certain which one they must have. This blog article will examine shared attributes of high availability (HA) and fault tolerance (FT). What does high availability mean?
You will likely need to write code to integrate systems and handle complex tasks or incoming network requests. As a bonus, operations staff never needs to update operating systems or hardware, because AWS manages servers with no stoppage of application functionality. Customizing and connecting these services requires code.
While most of our cloud & platform partners have their own dependency analysis tooling, most of them focus on basic dependency detection based on network connection analysis between hosts. What is the network traffic going to be between services we migrate and those that have to stay in the current data center?
Each of these models is suitable for production deployments and high traffic applications, and are available for all of our supported databases, including MySQL , PostgreSQL , Redis™ and MongoDB® database ( Greenplum® database coming soon). Here are the databases and cloud providers supported through each model: Supported Databases.
In the past few years, we have seen an explosion in the use of Deep Learning as its software platforms mature and the supporting hardware, especially GPUs with larger memories, become widely available. Deep Learning in Neural Networks: An Overview. 2014.09.003).
Snap: a microkernel approach to host networking Marty et al., This paper describes the networking stack, Snap , that has been running in production at Google for the last three years+. Pony Express, as we saw earlier, is a ground-up implementation of networking primitives. SOSP’19. It reminds me of ZeroMQ.
A log is a detailed, timestamped record of an event generated by an operating system, computing environment, application, server, or network device. Logs can include data about user inputs, system processes, and hardware states. “Logging” is the practice of generating and storing logs for later analysis.
Its design prioritizes high availability and efficient data transfer with minimal overhead, making it a practical choice for handling real-time data pipelines and distributed event processing. It follows a push-based approach, ensuring messages are distributed to consumers as soon as they become available.
But it’s not easy: to pull this off, VFX studios need to build and operate serious technical infrastructure (compute, storage, networking, and software licensing), otherwise known as a “ render farm.” via direct plug-ins, and is available on multi-cloud platform services. Additionally, Conductor supports render management systems?—?including
By bringing computation closer to the data source, edge-based deployments reduce latency, enhance real-time capabilities, and optimize network bandwidth. Use hardware-based encryption and ensure regular over-the-air updates to maintain device security. Inconsistent network performance affecting data synchronization.
While our goal is to roll out AV1 on all of our platforms, we see a good fit for AV1’s compression efficiency in the mobile space where cellular networks can be unreliable, and our members have limited data plans. AV1-libaom compression efficiency as measured against VP9-libvpx.
While our goal is to roll out AV1 on all of our platforms, we see a good fit for AV1’s compression efficiency in the mobile space where cellular networks can be unreliable, and our members have limited data plans. AV1-libaom compression efficiency as measured against VP9-libvpx.
Compare PostgreSQL vs. Oracle functionality across available tools, capabilities and services. Not available. Not available. Not available. New Oracle versions are generally available every 2-4 years. Data encryption can be achieved with advanced security plugins like pgcrypto which are available for free.
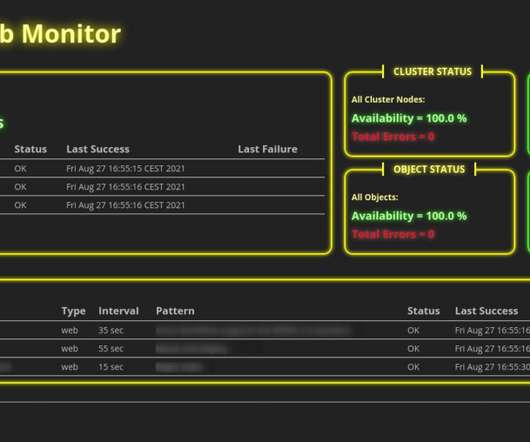
As an application owner, you need to ensure the continuous availability and performance of your applications from your end-users’ point of view. Sometimes, you need to check the availability of internal resources that aren’t accessible from outside your network. More information is available in Dynatrace Help.
With the average cost of unplanned downtime running from $300,000 to $500,000 per hour , businesses are increasingly using high availability (HA) technologies to maximize application uptime. Where a high availability design once worked well, it can no longer keep up with more complex requirements. there cannot be high availability.
Complementing the hardware is the software on the RAE and in the cloud, and bridging the software on both ends is a bi-directional control plane. For example, when running tests, the state of the device will change from “available for testing” to “in test.” In this blog post, we will focus on the latter feature set.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content