This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In October 2021, Dynatrace announced the availability of the Dynatrace Software Intelligence Platform on Google Cloud as a software as a service (SaaS) solution. Today, we are excited to announce this SaaS delivery model is now generally available (GA) to the public through Dynatrace sales channels.
In recent years, function-as-a-service (FaaS) platforms such as Google Cloud Functions (GCF) have gained popularity as an easy way to run code in a highly available, fault-tolerant serverless environment. What is Google Cloud Functions? GCF is part of the Google Cloud Platform. How Google Cloud Functions works.
Dynatrace industry-leading tracing, metrics, and log ingestion provide the level of high fidelity data that teams need to make accurate predictions about capacity. This is important because manual tracing is super costly and there is a lack of information available on this topic to assist developers.
Cloud-native observability for Google’s fully managed GKE Autopilot clusters demands new methods of gathering metrics, traces, and logs for workloads, pods, and containers to enable better accessibility for operations teams. First, we create a small Kubernetes cluster in the Google Cloud Console. and GKE Autopilot 126.
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. If you’ve read about observability, you likely know that collecting the measurements of logs, metrics, and distributed traces are the three key pillars to achieving success.
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Like any IT or business project, you’ll need to track critical key metrics. Here are nine key DevOps metrics and DevOps KPIs that will help you be successful.
Dynatrace Synthetic Monitoring allows you to proactively monitor the availability of your public as well as your internal web applications and API endpoints from locations around the globe or important internal locations such as branch offices. Ensure better user experience with paint-focused performance metrics. Dynatrace news.
Metrics matter. But without complex analytics to make sense of them in context, metrics are often too raw to be useful on their own. To achieve relevant insights, raw metrics typically need to be processed through filtering, aggregation, or arithmetic operations. Examples of metric calculations. Dynatrace news.
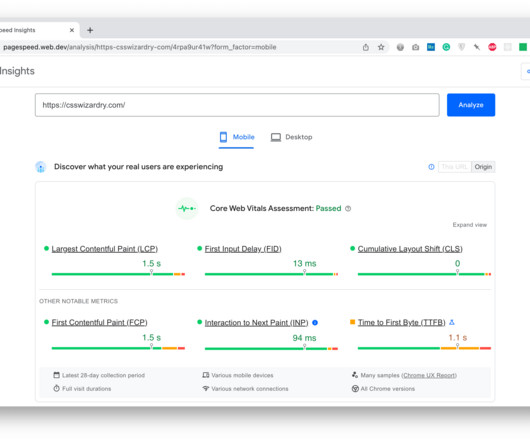
Metrics that offer measurable, repeatable insight into the user experience from the moment they arrive on a website from a mobile or desktop device. Great user experiences start with Core Web Vitals (CWVs) — a set of metrics defined by Google to help measure user experience at scale. When do these metrics matter?
To provide “quality signals that are essential to delivering a great user experience on the web,” Google introduced their Core Web Vitals initiative last year, advocating the Largest contentful paint , Cumulative layout shift , and First input delay metrics. by Google Core Web Vitals is?certainly?valuable,?it?leaves
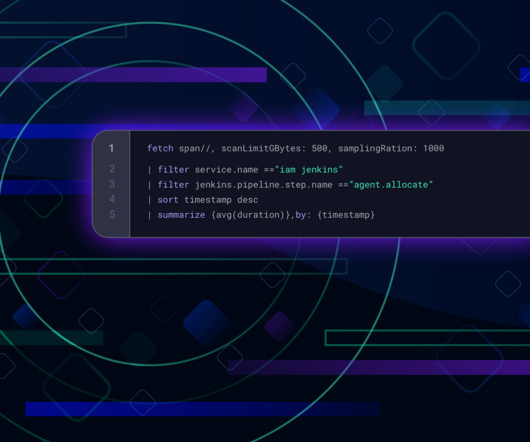
Welcome back to the second part of our blog series on how easy it is to get enterprise-grade observability at scale in Dynatrace for your OpenTelemetry custom metrics. In Part 1 , we announced our new OpenTelemetry custom-metric exporters that provide the broadest language coverage on the market, including Go , .NET record(value); }.
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
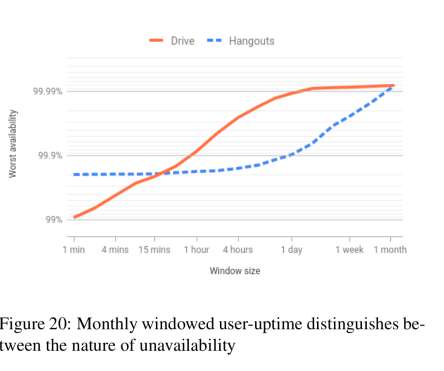
Meaningful availability , Hauer et al., This very clearly written paper describes the Google G Suite team’s search for a meaningful availabilitymetric: one that accurately reflected what their end users experienced, and that could be used by engineers to pinpoint issues and guide improvements. > NSDI’20.
Google’s Core Web Vitals initiative was launched in May of 2020 and, since then, its role in Search has morphed and evolved as roll-outs have been made and feedback has been received. However, to this day, messaging from Google can seem somewhat unclear and, in places, even contradictory. Don’t have time to read 5,500+ words?
Dynatrace Visually complete is a point-in-time web performance metric that measures when the visual area of a page has finished loading. Dynatrace is the only solution that provides these user experience metrics consistently for real user monitoring as well as for synthetic monitors. More precisely, you can now: . What you can achieve.
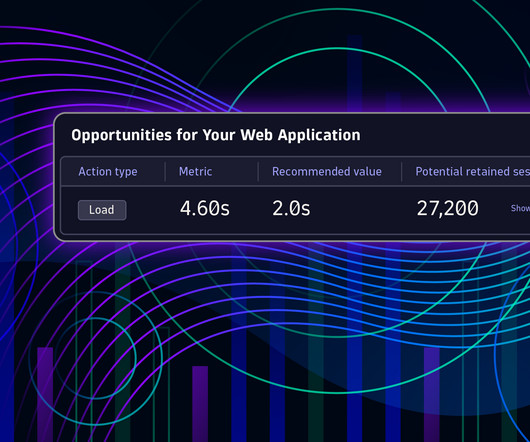
When a page is slow to load, users are quick to abandon the site; research by Google , Vodafone , Akamai , and others has repeatedly shown that even small (~100 ms) degradations in page performance can increase abandonment, lost revenue, and lead to persistent changes in user behavior.
How To Monitor And Optimize Google Core Web Vitals How To Monitor And Optimize Google Core Web Vitals Matt Zeunert 2024-04-16T10:00:00+00:00 2024-04-16T12:05:36+00:00 This article is sponsored by DebugBear Google’s Core Web Vitals initiative has increased the attention website owners need to pay to user experience.
Historically, I’d maybe look at Google Analytics—or a RUM solution if the client had one already—but this is only useful for showing me particular outliers, and not necessarily any patterns across the whole project. Any time you run a test with WebPageTest, you’ll get this table of different milestones and metrics. See entry 6.
You’ve fired up Google Lighthouse from Chrome’s DevTools because everyone and their uncle uses it to evaluate performance. Except, don’t — at least not using Google Lighthouse as your sole proof. Google Lighthouse is merely one tool in a complete performance toolkit. That’s what we’re aiming for, after all!
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. According to Google’s SRE handbook , best practices, there are “ Four Golden Signals ” we can convert into four SLOs for services: reliability, latency, availability, and saturation.
And how can you verify this performance consistently across a multicloud environment that also uses Microsoft Azure and Google Cloud Platform frameworks? But how can you ensure that your applications meet these pillars and deliver the best outcomes for your business? This workflow uses the Dynatrace Site Reliability Guardian application.
The flip side of speeding up delivery, however, is that each software release comes with the risk of impacting your goals of availability, performance, or any business KPIs. Which metrics are relevant for your business, anyway? Modern observability tools provide many metrics, but which ones are really important for your business?
Just as people use Xerox as shorthand for paper copies and say “Google” instead of internet search, Docker has become synonymous with containers. An orchestration platform needs to expose data about its internal states and activities in the form of logs, events, metrics, or transaction traces. What is Docker? Observability.
While Dynatrace provides software intelligence to accelerate your company’s digital transformation, web analytics tools like Adobe Analytics help you deeply understand your user journeys, segmentation, behavior, and strategic business metrics such as revenue, orders, and conversion goals. Google Analytics. Intercom (Session ID).
The most important things to have in mind, and measure KPIs for, when working towards delivery of excellent Digital Experiences are: Availability: Is the touchpoint available when the user wants to use it? Is the functionality available frictionless? Functionality: Can the user achieve what they want to do?
Flexible pricing models that offer discounts based on commitment or availability can greatly reduce cloud waste. This includes spot instances such as unused cloud capacity that’s available at a discounted price. Hyperscaler cloud service providers such as AWS, Microsoft Azure, and Google Cloud Platform can do this, too.
These UA campaigns typically feature static creatives, launch trailers, and game review videos on platforms like Google, Meta, and TikTok. The primary goals of these campaigns are to encourage more people to install and play the games, making incremental installs and engagement crucial metrics for evaluating their effectiveness.
Organizations are constantly being measured against the best available digital experiences — coming from Google, Amazon, Facebook, and other industry leaders. Some of the factors that affect user experience include: Availability : Is the touchpoint available when the user wants to use it? Break down silos.
Keeping pace with modern digital transformation requires ensuring that applications are responsive, resilient, and always available amid increased complexity. As a result, site reliability has emerged as a critical success metric for many organizations. availability. Service-level objectives (SLOs).
These are just a fraction of the technology buzzwords you’ll find as you Google your way around the internet. Loosely defined, Observability boils down to inferring the internal health and state of a system by looking at the external data it produces, which most commonly are logs, metrics, and traces. Dynatrace news.
Leveraging cloud-native technologies like Kubernetes or Red Hat OpenShift in multicloud ecosystems across Amazon Web Services (AWS) , Microsoft Azure, and Google Cloud Platform (GCP) for faster digital transformation introduces a whole host of challenges. Track log metrics and receive alerts without manually setting thresholds.
How To Use Google CrUX To Analyze And Compare The Performance Of JS Frameworks. How To Use Google CrUX To Analyze And Compare The Performance Of JS Frameworks. As I previously mentioned, my primary data source for this analysis is Google CrUX. Starting in June 2021, these metrics have become a ranking factor for Google search.
According to the Google Site Reliability Engineering (SRE) handbook, monitoring the four golden signals is crucial in delivering high-performing software solutions. While this connection might sound simple, finding the right metrics to measure the needed SLIs takes time and effort.
Keptn: A reference implementation of Google’s SRE principles. Software engineer Taras Tsugrii of Meta (formerly Facebook) paid Keptn a high compliment, saying it feels like a reference implementation of Google’s SRE principles , which are the search giant’s techniques for ensuring the integrity of its sites and services.
You also might be required to capture syslog messages from cloud services on AWS, Azure, and Google Cloud related to resource provisioning, scaling, and security events. Without seeing syslog data in the context of your infrastructure, metrics, and transaction traces, you’re slowed down by manual work with siloed data.
Automated Metric Anomaly Detection. Thanks to the automated dependency information (=Dynatrace Smartscape), Dynatrace’s AI Davis automatically analyzes every single metric along the dependency tree. From here we also get access to all other pod & process relevant metrics, e.g. memory, threads, … or accessing the container logs.
Every organization’s goal is to keep its systems available and resilient to support business demands. This view shows the availability SLO for key application functions, like login and vehicle list, as well as a large set of timeframes, like last 30 minutes, last hour, today, and last six days. Dynatrace news.
the newly released mobile app available on Android and iOS , uses Davis AIOps to push alert notifications directly to your phone and significantly reduce the incident response times. Now every second matters for the Site Reliability Engineering Team as it affects Mean Time to Resolution (MTTR) metrics! Dynatrace 3.0, An issue occurs.
Cloud providers such as Google, Amazon Web Services, and Microsoft also followed suit with frameworks such as Google Cloud Functions , AWS Lambda , and Microsoft Azure Functions. Increased availability. In-depth, AI-driven metrics can help to manage this simplicity. How does function as a service work?
service availability with <50ms latency for an application with no revenue impact. For example, constant SLO violations of service availability for the check deposit application would create customer dissatisfaction leading to potential revenue impact. Let’s take service availability for example.
If that service is slow, failing, or not available at all it results in frustration mentioned in some of the comments on social media and the app store. In the workshop, I also answered the question: How can we measure those metrics (=SLIs) that are behind our objectives? Availability. App Rating. Response time. Error rate.
However, such observation periods come with a disadvantage: incidents can pile up and there is a delay between those incidents and the corresponding health metrics ultimately dropping low enough to trigger a warning. Most monitoring tools offer only a single SLO metric. Get up and running in under a minute with SLO templates.
Several distributions of Kubernetes rely on containerd as their default container runtime, including the IBM Kubernetes Service (IKS) and Google Kubernetes Engine (GKE). This category hosts many single-purpose projects and solutions that focus either on metrics, traces, or logs. Enable containerd monitoring for Kubernetes.
At Dynatrace, we measure the DORA metrics from Google. While tracking the time to restore a service and the change failure rate require an issue management system, the first two metrics can be acquired by looking at the pipelines. The first DORA metric is rather easy; we simply look at the throughput of the main branch.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content