This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
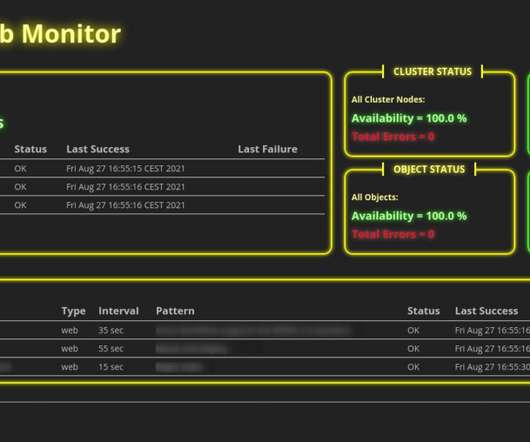
If you run several web servers in your organization or even public web servers on the internet, you need some kind of monitoring. If your servers go down for some reason, this may not be funny for your colleagues, customer, and even for yourself. For that reason, we use monitoring tools.
In a MySQL master-slave high availability (HA) setup, it is important to continuously monitor the health of the master and slave servers so you can detect potential issues and take corrective actions. MySQL Master Server Health Checks. Important Health Checks for your MySQL Master-Slave Servers Click To Tweet.
MySQL does not limit the number of slaves that you can connect to the master server in a replication topology. A classic solution for this problem is to deploy a binlog server – an intermediate proxy server that sits between the master and its slaves. Ripple is an open source binlog server developed by Pavel Ivanov.
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Our script, available on GitHub , provides details. Are the corresponding services running on those hosts?
Both categories share common requirements, such as high throughput and high availability. Eventually Consistent Global Counter While some users may accept the limitations of a Best-Effort counter, others opt for precise counts, durability and global availability. This is where most of the complexity in Counter Abstraction comes in.
MySQL Server generates several logs that can help you monitor the activities of the server. Setting Up MySQL Server Logging. As an example, let’s have some criteria for managing general MySQL query logs. Managing MySQL Server Logs: Rotate, Compress, Retain & Delete Click To Tweet.
Dynatrace Managed is intrinsically highly available as it stores three copies of all events, user sessions, and metrics across its cluster nodes. For example, in a three-node cluster, one node can go down; in a cluster with five or more nodes, two nodes can go down. Turnkey high availability across globally distributed data centers.
We’re happy to announce the General Availability of cross-environment dashboarding capabilities (having released this functionality in an Early Adopter release with Dynatrace version 1.172 back in June 2019). Keep the token secret available for the second and final configuration step. Dynatrace news.
For example, it supports string and numerical values, enabling a multitude of different use cases. You can use it to visualize CPU utilization across your hosts, disk space used, server-side response time, web request/service failure rates, or any other area where you need to spot outliers immediately. Try different cell shapes.
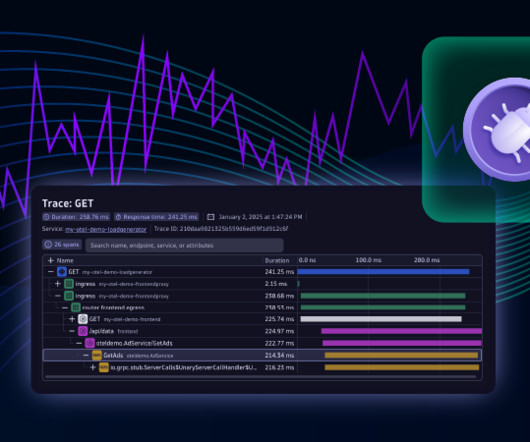
In this example use case, we’re investigating a high CPU load issue in an application using OpenTelemetry. Dynatrace OpenPipeline is configured to ingest logs from our environment, including the AdService example service. Dynatrace Live Debugger will be generally available (GA) within the next 90 days.
OneAgent knows where to connect for further runtime configuration and where to send data because the installer itself is pre-configured to connect to the exact tenant and server that it’s downloaded from. But what if your environment grows and you decide to distribute data between two Dynatrace servers?
For a detailed explanation of this example and walkthrough, visit our blog post, Debug complex performance issues in production. Observability for Developers is generally available except for Traces powered by Grail and Live Debugger, which are currently in preview and will be generally available within the next 90 days.
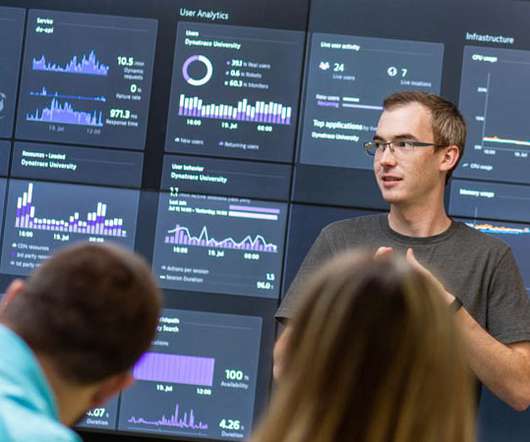
Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. Host Monitoring dashboards offer real-time visibility into the health and performance of servers and network infrastructure, enabling proactive issue detection and resolution.
The following components make up the OCP control plane: API server: Tracks the state of all other components and takes care of communication within and outside the cluster. Controller Manager: Runs controllers such as the node controller responsible for handling node availability.
It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data. Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL.
Analyzing impression history, for example, might help determine how well a specific row on the home page is functioning or assess the effectiveness of a merchandising strategy. These events are promptly relayed from the client side to our servers, entering a centralized event processing queue.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it.
When deploying in production, it’s highly recommended to setup in a MongoDB replica set configuration so your data is geographically distributed for high availability. servers.mongodirector.com:27017,SG-example-1.servers.mongodirector.com:27017,SG-example-2.servers.mongodirector.com:27017/admin?replicaSet=RS-example&ssl=true'
IBM Power servers enable customers to respond faster to business demands, protect data from core to cloud, and streamline insights and automation. It automates tasks such as provisioning and scaling Dynatrace monitoring components, updating configurations, and ensuring the health and availability of the monitoring infrastructure.
A significant feature of Chronicle Queue Enterprise is support for TCP replication across multiple servers to ensure the high availability of application infrastructure. This is the first time I have benchmarked it with a realistic example. This is the first time I have benchmarked it with a realistic example.
Redis Server: 5.07, x86/64. MongoDB server: 4.4.2, BangDB server: 2.0.0, An application example is a session store recording recent actions. Application example: photo tagging; add a tag is an update, but most operations are to read tags. Application example: user status updates; people want to read the latest.
Too many concurrent server requests can lead to website crashes if youre not equipped to deal with them. The good news is that you can maximize availability and prevent website crashes by designing websites specifically for these events. You can free up space and reduce the load on your server by compressing and optimizing images.
For example, Amazon Web Services (AWS) charges for data transfer between Amazon EC2 instances within the same region. Flexible pricing models that offer discounts based on commitment or availability can greatly reduce cloud waste. This includes spot instances such as unused cloud capacity that’s available at a discounted price.
ReactDOM, for example, ends up 27% smaller when compressed with maximum-level Brotli compression (11) as opposed to with maximum-level Gzip (9). Taking a very reductive and simplistic view of how files are transmitted from server to client, we need to look at TCP. Using Paul Calvano’s Gzip and Brotli Compression Level Estimator!
In my last blog , I’ve provided an example of this happening, whereby the traffic spiked and quadrupled the usual incoming traffic. As Dynatrace is an all in one solution, you have multiple options to capture the needed data; you can use Real User Monitoring (RUM) properties , Server-side request attribute , and Log metrics.
When it comes to access to their applications, users demand instant, reliable, and secure interactions — and that means databases must be highly available. With database high availability (HA), services are largely uninterrupted, and end users are largely satisfied. The obvious answer is this: To achieve high availability.
Recently I covered some of the T-SQL improvements in SQL Server 2022 here , and Aaron Bertrand covered additional improvements here. Microsoft just announced the release of SQL Server 2022 CTP 2.1. I’ll be using the sample database TSQLV6 in the examples in this article. Those improvements were introduced in CTP 2.0.
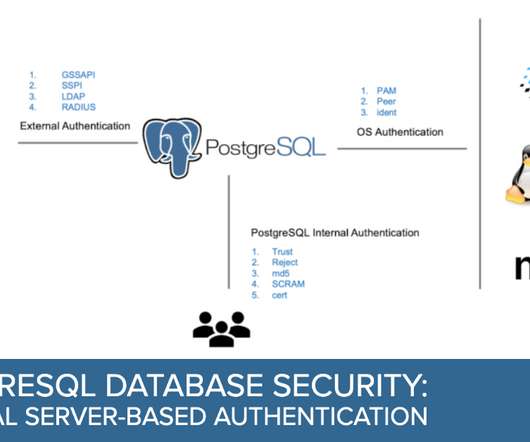
PostgreSQL server authentication refers to verifying the identity of a user trying to connect to the PostgreSQL server. The pg_hba.conf file is used to configure the authentication methods the PostgreSQL server uses and can specify different methods for different types of connections.
With more organizations taking the multicloud plunge, monitoring cloud infrastructure is critical to ensure all components of the cloud computing stack are available, high-performing, and secure. For example, uptime detection can identify database instability and help to improve mean time to restoration. Cloud-server monitoring.
But there are other related components and processes (for example, cloud provider infrastructure) that can cause problems in applications running on Kubernetes. And because Dynatrace can consume CloudWatch metrics, almost all your AWS usage information is available to you within Dynatrace. Dynatrace OneAgent documentation .
It provides a good read on the availability and latency ranges under different production conditions. These include options where replay traffic generation is orchestrated on the device, on the server, and via a dedicated service. Also, since this logic resides on the server side, we can iterate on any required changes faster.
The F5 BIG-IP Local Traffic Manager (LTM) is an application delivery controller (ADC) that ensures the availability, security, and optimal performance of network traffic flows. Business-critical applications typically rely on F5 for availability and success. Example of an automatically generated dashboard for F5 instances.
Microsoft recently released the first public preview of SQL Server 2022. I’ll be using the sample database TSQLV6 in the examples in this article. This clause is now available in Azure SQL Database and SQL Server 2022, provided you use database compatibility level 160 or higher.
It offers all the functionality we need to deploy our application in production, with a hybrid system with static pages and server-side rendered (SSR) pages. Isomorphic: Works on both server and client (browser). Static export: Compile static files to be able to upload to the server. SSR Benefits (Next.js). Performance.
Syslog is the go-to protocol that delivers infrastructure administrators, network engineers, and security team logs that tell them all they need to know about their systems’ delivery, performance, availability, and security. Syslog is a protocol with clear specifications that require a dedicated syslog server.
As the expected behavior of spot instances is that they are shut down within 5 minutes of their creation, the traditional strategy of availability alerting isn’t viable. To avoid false-positive alerts, Dynatrace availability alerting for servers automatically detects the planned downscaling of AWS spot instances.
Before GraphQL: Monolithic Falcor API implemented and maintained by the API Team Before moving to GraphQL, our API layer consisted of a monolithic server built with Falcor. A single API team maintained both the Java implementation of the Falcor framework and the API Server. To launch Phase 1 safely, we used AB Testing.
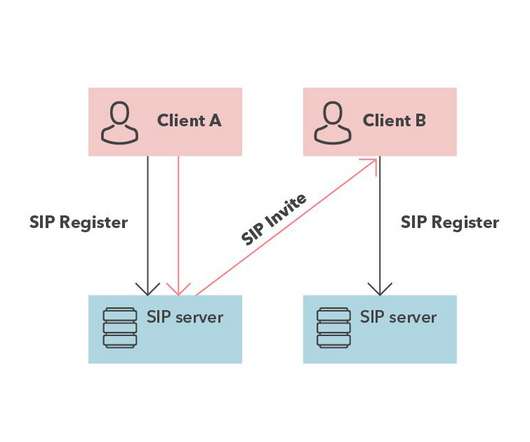
This is not to say, however, that any mid-level developer will have much difficulty finding and handling one of many available open-source servers. VoIP technologies have a reputation for being rather complex and not without good reason.
If your teams are using OpenTelemetry custom instrumentation to enrich monitoring data with project-specific details (for example, to add business data or capture developer-specific diagnostics points) and you want to retain their instrumentation invest. TL;DR summary.
Its design prioritizes high availability and efficient data transfer with minimal overhead, making it a practical choice for handling real-time data pipelines and distributed event processing. It follows a push-based approach, ensuring messages are distributed to consumers as soon as they become available.
Collector Custom Resource A custom resource (CR) represents a customization of a specific Kubernetes installation that isnt necessarily available in a default Kubernetes installation; CRs help make Kubernetes more modular. There are two versions available: v1alpha1 : apiVersion: opentelemetry.io/v1alpha1 spec.containers[*].name}'
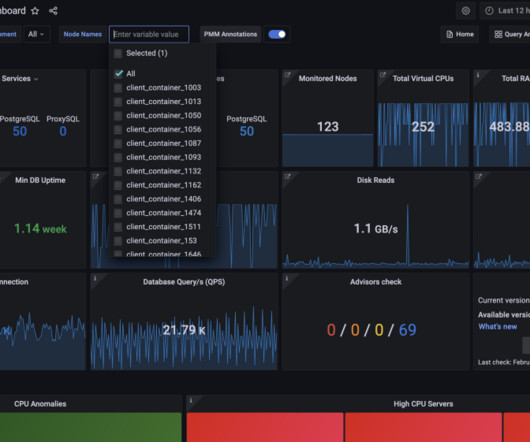
Being software composed of different, multiple technologies can add complexity to a well-known concept: High Availability (HA). As you can see, stats are available via the port 8404. And here is the not-so-easy part: One has to deploy at least two PMM instances on at least two different servers AND set up replicas. How to do it?
The Qualys Threat Research Unit (TRU) has discovered a Remote Unauthenticated Code Execution (RCE) vulnerability in OpenSSH server (sshd) in glibc-based Linux systems. For example, some Proof-of-concept attacks have failed, and these failures write various error messages to the victims’ sshd logs.
So, you have dozens of teams with hundreds of engineers who are responsible for ensuring high availability and reliability, including employing fault-tolerant systems, and implementing rigorous testing and monitoring procedures. What options regarding access control are currently available in PMM? to monitor and diagnose. +50
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content