This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. Hence, having a dedicated dashboard tile visualizing the key parameters of each SLO simplifies the process of evaluating them.
The newly introduced step-by-step guidance streamlines the process, while quick data flow validation accelerates the onboarding experience even for power users. Step-by-step setup The log ingestion wizard guides you through the prerequisites and provides ready-to-use command examples to start the installation process.
Dynatrace OpenPipeline is a new stream processing technology that ingests and contextualizes data from any source. Business process monitoring and optimization. Most of the use cases in these two broad categories benefit from the flexibility that comes from multiple available sources of business data.
Onboarding teams using self-service Kubernetes selectors is one of the best examples of how Dynatrace embraces cloud native technologies to increase automation, reduce bureaucracy, and encourage agility. The following example drives the point home. Embracing cloud native best practices to increase automation. Putting it all together.
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Our script, available on GitHub , provides details. Are the corresponding services running on those hosts?
Ensuring smooth operations is no small feat, whether you’re in charge of application performance, IT infrastructure, or business processes. Activate Davis AI to analyze charts within seconds Davis AI can help you expand your dashboards and dive deeper into your available data to extract additional information.
The business process observability challenge Increasingly dynamic business conditions demand business agility; reacting to a supply chain disruption and optimizing order fulfillment are simple but illustrative examples. Most business processes are not monitored. First and foremost, it’s a data problem.
A Data Movement and Processing Platform @ Netflix By Bo Lei , Guilherme Pires , James Shao , Kasturi Chatterjee , Sujay Jain , Vlad Sydorenko Background Realtime processing technologies (A.K.A stream processing) is one of the key factors that enable Netflix to maintain its leading position in the competition of entertaining our users.
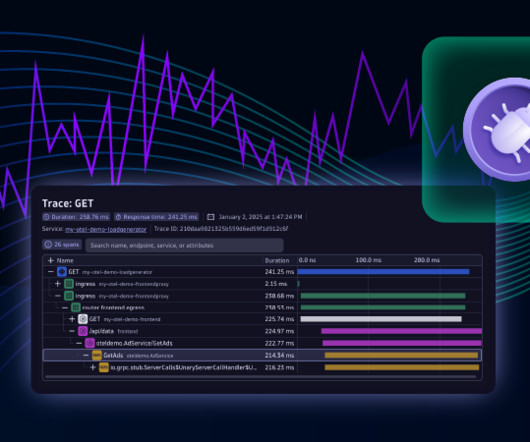
Automatic data capture and display: More data, including span attributes, is available for out-of-the-box analysis, with no additional configuration necessary. As soon as the new Distributed Tracing Experience is available for your environment, you’ll see a teaser banner in your classic Distributed Traces app.
Dynatrace Simple Workflows make this process automatic and frictionlessthere is no additional cost for workflows. Why manual alerting falls short As your product and deployments scale horizontally and vertically, the sheer volume of data makes it impossible for teams to catch every error quickly using manual processes.
Unrealized optimization potential of business processes due to monitoring gaps Imagine a retail company facing gaps in its business process monitoring due to disparate data sources. Due to separated systems that handle different parts of the process, the view of the process is fragmented.
Kickstart your creation journey using ready-made dashboards and notebooks Creating dashboards and notebooks from scratch can take time, particularly when figuring out available data and how to best use it. Kickstarting the dashboard creation process is, however, just one advantage of ready-made dashboards.
In addition to service-level monitoring, certain services within the OpenTelemetry demo application expose process-level metrics, such as CPU and memory consumption, number of threads, or heap size for services written in different languages. You can even walk through the same example above.
By leveraging Dynatrace observability on Red Hat OpenShift running on Linux, you can accelerate modernization to hybrid cloud and increase operational efficiencies with greater visibility across the full stack from hardware through application processes. Dynatrace observability is available for Red Hat OpenShift on IBM Power.
For example: Infrastructure services might provide data about request timings that can give you a precise overview of system health, but the data is logged in a custom format. For example, Dynatrace recently introduced the extraction of log-based metrics for JSON logs.
As every developer knows, logs are crucial for uncovering insights and detecting fundamental flaws, such as process crashes or exceptions. Using Live Debugger, we immediately get insights into the running code, including variable values, process and thread information, and even a trace ID for the captured transaction.
Access policies for Dynatrace Grail™ data lakehouse are still available as service-related policies; they allow you to control access to the monitoring data on a per-data-source level, for example, logs and metrics. All other default policies on the service level, for example, “AutomationEngine – User” access, are now marked as Legacy.
Both categories share common requirements, such as high throughput and high availability. Eventually Consistent Global Counter While some users may accept the limitations of a Best-Effort counter, others opt for precise counts, durability and global availability.
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. Data is then dynamically routed into pipelines for further processing.
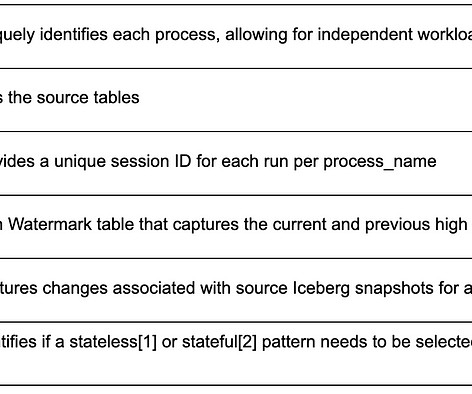
By Abhinaya Shetty , Bharath Mummadisetty In the inaugural blog post of this series, we introduced you to the state of our pipelines before Psyberg and the challenges with incremental processing that led us to create the Psyberg framework within Netflix’s Membership and Finance data engineering team.
However, due to the fact that they boil down selected indicators to single values and track error budget levels, they also offer a suitable way to monitor optimization processes while aligning on single values to meet overall goals. By recognizing the insights provided, you can optimize processes and improve overall efficiency.
In this example use case, we’re investigating a high CPU load issue in an application using OpenTelemetry. Dynatrace OpenPipeline is configured to ingest logs from our environment, including the AdService example service. Dynatrace Live Debugger will be generally available (GA) within the next 90 days.
The challenge along the path Well-understood within IT are the coarse reduction levers used to reduce emissions; shifting workloads to the cloud and choosing green energy sources are two prime examples. The certification results are now publicly available.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
Grafana Loki is a horizontally scalable, highly available log aggregation system. Logs can also be transformed appropriately for presentation, for example, or further pipeline processing. It is designed for simplicity and cost-efficiency. Loki can provide a comprehensive log journey.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is Apache Kafka?
Various test tools are available for different types of testing, including unit testing, integration testing, and more. Some test tools are intended for developers during the development process, while others are designed for quality assurance teams or end users.
As a result, requests are uniformly handled, and responses are processed cohesively. This data is processed from a real-time impressions stream into a Kafka queue, which our title health system regularly polls. Many of the metadata and assets involved in title setup have specific timelines for when they become available to members.
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. When handling large amounts of complex data, or big data, chances are that your main machine might start getting crushed by all of the data it has to process in order to produce your analytics results. Query Optimization.
Because it includes examples of 10 programming languages that OpenTelemetry supports with SDKs, the application makes a good reference for developers on how to use OpenTelemetry. In this example, we’ll use Dynatrace. This example illustrates how to pass the token most easily using the terminal. metrics from span data.
As an example, you can specify a Config that reads a pleasantly human-readable configuration file, formatted as TOML. The standard dictionary subscript notation is also available. Take a look at two interesting examples of this pattern in the documentation. Configs can of course also be used within yourflow.
Monitoring and observability are two key concepts that facilitate this process, offering valuable visibility into the health and performance of systems. In this article, we will explore the differences between monitoring and observability, provide examples to illustrate their applications and highlight their respective benefits.
By leveraging the Dynatrace Operator and Dynatrace capabilities on Red Hat OpenShift on IBM Power, customers can accelerate their modernization to hybrid cloud and increase operational efficiencies with greater visibility across the full stack from hardware through application processes.
When organizations implement SLOs, they can improve software development processes and application performance. Stable, well-calibrated SLOs pave the way for teams to automate additional processes and testing throughout the software delivery lifecycle. Instead, they can ensure that services comport with the pre-established benchmarks.
The Clouds app provides a view of all available cloud-native services. Logs in context, along with other details, are instantly available after selecting a resource. The reasons are easy to find, looking at the latest improvements that went live along with the general availability of the Logs app.
But there are other related components and processes (for example, cloud provider infrastructure) that can cause problems in applications running on Kubernetes. And because Dynatrace can consume CloudWatch metrics, almost all your AWS usage information is available to you within Dynatrace. Dynatrace OneAgent documentation .
For example, optimizing resource utilization for greater scale and lower cost and driving insights to increase adoption of cloud-native serverless services. This process enables you to continuously evaluate software against predefined quality criteria and service level objectives (SLOs) in pre-production environments.
Ideally, we would have causal estimates from an A/B test to use for validation, but since that is not available, we use another causal inference design as one of our ensemble of validation approaches. Each format has a different production process and different patterns of cash spend, called our Content Forecast.
The automated extraction of ownership information, for example, from Kubernetes annotations, is therefore essential. Secondly, knowing who is responsible is essential but not sufficient, especially if you want to automate your triage process. An example via Monaco can be found in this public GitHub repository.
And by “sample” we mean “an example”, like food samples in your local grocery store. Obviously not all tools are made with the same use case in mind, so we are planning to add more code samples for other (than classical batch ETL) data processing purposes, e.g. Machine Learning model building and scoring. test_sparksql_write.py
Were excited to announce that Davis CoPilot Chat is now available across the Dynatrace platform. To help you navigate this and boost your efficiency, we’re excited to announce that Davis CoPilot Chat is now generally available (GA). Davis CoPilot Chat will be available with the release of Dynatrace SaaS version 1.307.
This process, known as auto-adaptive thresholding, eliminates the need to define a static threshold upfront. For example, the team must establish specific thresholds for desired service performance behavior. For instance, if an objective is violated, they’re immediately notified, for example, through a Slack channel.
Deploying software in Kubernetes is often viewed as a straightforward process—just use kubectl or a GitOps solution like ArgoCD to deploy a YAML file, and you’re all set, right? Infrastructure health The underlying infrastructure’s health directly impacts application availability and performance.
But how do you get started, and what are some service level objective examples? In this post, I’ll lay out five foundational service level objective examples that every DevOps and SRE team should consider. These organizations rely heavily on performance, availability, and user satisfaction to drive sales and retain customers.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content