This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Our script, available on GitHub , provides details. Are the corresponding services running on those hosts?
Onboarding teams using self-service Kubernetes selectors is one of the best examples of how Dynatrace embraces cloud native technologies to increase automation, reduce bureaucracy, and encourage agility. The following example drives the point home. Information about each of these topics will be available in upcoming announcements.
Thanks to the power of Grail, those details are available for all executions stored for the entire retention period during which synthetic results are kept. It now fully supports not only Network Availability Monitors but also HTTP synthetic monitors. Details of requests sent during each monitor execution are also available.
While selecting a Kubernetes segment, the selector provides a dynamic list of available resources. Segments can implement variables to dynamically provide, for example, a list of entities to users, such as available Kubernetes clusters, for unmatched flexibility and dynamic segmentation. What are Dynatrace Segments?
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. While the SLO management web UI and API are already available, the dashboard tile will be released within the next weeks.
It automates tasks such as provisioning and scaling Dynatrace monitoring components, updating configurations, and ensuring the health and availability of your monitoring infrastructure. The scope of automatic workload instrumentation is user-configurable, for example, by namespace. Sign up for a fully functional Dynatrace free trial.
Kickstart your creation journey using ready-made dashboards and notebooks Creating dashboards and notebooks from scratch can take time, particularly when figuring out available data and how to best use it. An example of this is shown in the video above, where we incorporated network-related metrics into the Kubernetes cluster dashboard.
For your reference, the complete working example is available on GitHub. By leveraging tools like Spring Boot Actuator , Micrometer with InfluxDB , and Grafana , you can gather meaningful insights easily and quickly. In this article, we'll walk through setting up this stack using a simple "Card-Playing" app/game as our use case.
Note that the developers of the respective services need to make these metrics available by exposing them via, for example, a Prometheus endpoint that can be used by the OpenTelemetry collector to ingest them and forward them to your Dynatrace tenant. You can even walk through the same example above.
Automatic data capture and display: More data, including span attributes, is available for out-of-the-box analysis, with no additional configuration necessary. As soon as the new Distributed Tracing Experience is available for your environment, you’ll see a teaser banner in your classic Distributed Traces app.
The log ingestion wizard offers support for all log ingestion methods available in Dynatrace Hub Get started with Logs: The OneAgent advantage For most scenarios, Dynatrace OneAgent is your best friend for getting started with Dynatrace log ingestion. Different log ingestion methods are available to address various needs.
Activate Davis AI to analyze charts within seconds Davis AI can help you expand your dashboards and dive deeper into your available data to extract additional information. For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline.
Access policies for Dynatrace Grail™ data lakehouse are still available as service-related policies; they allow you to control access to the monitoring data on a per-data-source level, for example, logs and metrics. All other default policies on the service level, for example, “AutomationEngine – User” access, are now marked as Legacy.
Most of the use cases in these two broad categories benefit from the flexibility that comes from multiple available sources of business data. Log data is then processed accordingly, stored in Dynatrace Grail™ causational data lakehouse, and available for your Business Analytics use cases.
For example, it supports string and numerical values, enabling a multitude of different use cases. To achieve the best visual outcome, we recommend experimenting with the available customization options. For example, set the value range for CPU consumption from 0% to 100%. Try different cell shapes. Min and max limits.
You can select any trigger thats available for standard workflows, including schedules, problem triggers, customer event triggers, or on-demand triggers. For this example, we go to Simple Workflows and select Trigger > Davis event trigger to find these out-of-memory errors. Go to Workflows and start creating a new workflow.
For a detailed explanation of this example and walkthrough, visit our blog post, Debug complex performance issues in production. Observability for Developers is generally available except for Traces powered by Grail and Live Debugger, which are currently in preview and will be generally available within the next 90 days.
A Kubernetes SLO that continuously evaluates CPU, memory usage, and capacity and compares these available resources to the requested and utilized memory of Kubernetes workloads makes potential resource waste visible, revealing opportunities for countermeasures.
In this example use case, we’re investigating a high CPU load issue in an application using OpenTelemetry. Dynatrace OpenPipeline is configured to ingest logs from our environment, including the AdService example service. Dynatrace Live Debugger will be generally available (GA) within the next 90 days.
The challenge along the path Well-understood within IT are the coarse reduction levers used to reduce emissions; shifting workloads to the cloud and choosing green energy sources are two prime examples. The certification results are now publicly available.
Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. For our example dashboard, we’ll only focus on some selected key infrastructure metrics. Also, explore additional dashboards available on the Dynatrace Playground.
Because it includes examples of 10 programming languages that OpenTelemetry supports with SDKs, the application makes a good reference for developers on how to use OpenTelemetry. In this example, we’ll use Dynatrace. This example illustrates how to pass the token most easily using the terminal. metrics from span data.
Grafana Loki is a horizontally scalable, highly available log aggregation system. Logs can also be transformed appropriately for presentation, for example, or further pipeline processing. It is designed for simplicity and cost-efficiency. Loki can provide a comprehensive log journey.
Both categories share common requirements, such as high throughput and high availability. Eventually Consistent Global Counter While some users may accept the limitations of a Best-Effort counter, others opt for precise counts, durability and global availability.
As an example, you can specify a Config that reads a pleasantly human-readable configuration file, formatted as TOML. The standard dictionary subscript notation is also available. Take a look at two interesting examples of this pattern in the documentation. Configs can of course also be used within yourflow.
Analyzing impression history, for example, might help determine how well a specific row on the home page is functioning or assess the effectiveness of a merchandising strategy. This dual availability ensures immediate processing capabilities alongside comprehensive long-term data retention.
This endpoint efficiently reads from all available Hollow Feeds to obtain the current status, thanks to Hollows in-memory capabilities. Many of the metadata and assets involved in title setup have specific timelines for when they become available to members. An example request with a future timestamp.
Familiarity with the production environment’s artifacts (for example, environment names and deployment labels) is crucial, but gathering this information can be time-consuming, creating overhead before the actual investigation begins.
Were excited to announce that Davis CoPilot Chat is now available across the Dynatrace platform. To help you navigate this and boost your efficiency, we’re excited to announce that Davis CoPilot Chat is now generally available (GA). Davis CoPilot Chat will be available with the release of Dynatrace SaaS version 1.307.
The automated extraction of ownership information, for example, from Kubernetes annotations, is therefore essential. Keeping ownership teams and their properties up to date is essential, as is having the right contact information available when needed. An example via Monaco can be found in this public GitHub repository.
In this article, we will explore the differences between monitoring and observability, provide examples to illustrate their applications and highlight their respective benefits. It typically involves setting up specific metrics, thresholds, and alerting mechanisms to track the performance and availability of various components.
As our customers adopt agile software development and continuous delivery to drive value faster, they face new risks that could impact availability, performance, and business KPIs. An SLI is a measurement of the performance or availability of an entity. Here is an example of a calculated metric for a service. Dynatrace news.
For example, optimizing resource utilization for greater scale and lower cost and driving insights to increase adoption of cloud-native serverless services. This is where unified observability and Dynatrace Automations can help by leveraging causal AI and analytics to drive intelligent automation across your multicloud ecosystem.
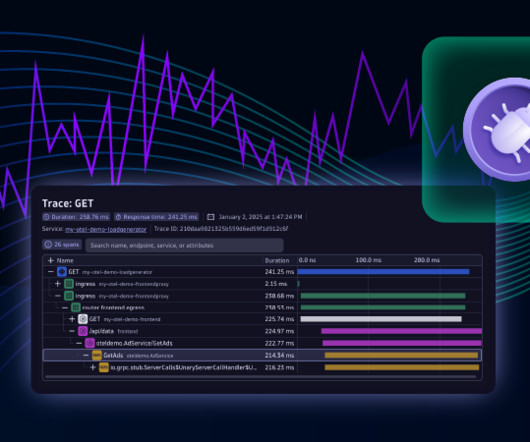
In this example, “Reverse proxy” and “Front-end server” are clearly in the critical path. In this example, “hipstershop.currency,” “hipstershop.checkout” and “hipstershop.cart” are also part of this critical path. In this example, we’re creating an SLO with a target of 98% of our requests without errors. Availability.
And there are a lot of monitoring tools available providing all kinds of features and concepts. For example, you can monitor the behavior of your applications, the hardware usage of your server nodes, or even the network traffic between servers. For that reason, we use monitoring tools.
Insights into MS Teams performance data for helpdesk and operations team provided by Phenisys This is a great example of how partners can customize and extend the Dynatrace platform for business-critical use cases using the same tools as Dynatrace developers.
After meeting the necessary requirements, we are excited to announce that the Dynatrace AI-powered platform as a SaaS on Microsoft Azure is now available in Switzerland. This represents the first observability solution available to Microsoft customers as a Switzerland-based SaaS deployment. Obligations to end users.
For example, the team must establish specific thresholds for desired service performance behavior. The Dynatrace data science team continuously improves the machine learning models used by Davis AI, for example, by adding new features to forecasting or refining mathematical calculations.
Its design prioritizes high availability and efficient data transfer with minimal overhead, making it a practical choice for handling real-time data pipelines and distributed event processing. It follows a push-based approach, ensuring messages are distributed to consumers as soon as they become available.
Since March 2024, the Dynatrace ® platform has been available on AWS in Tokyo, allowing customers to leverage the latest Dynatrace capabilities from Japan. Regulated sectors are making considerable effort to enable their organizations to use SaaS deployments (for example, ISMAP).
For example, a separate bucket could be used for detailed logs from Dynatrace Synthetic nodes. In conjunction with the previous example of keeping high-volume and short-lived logs separate, you might also need to keep your application data longer. Now, let’s take a look at a query example that puts this all into use.
Take the example of Amazon Virtual Private Cloud (VPC) flow logs, which provide insights into the IP traffic of your network interfaces. With this out-of-the-box support for scalable data ingest, log data is immediately available to your teams for troubleshooting and observability, investigating security issues, or auditing.
The Clouds app provides a view of all available cloud-native services. Logs in context, along with other details, are instantly available after selecting a resource. The reasons are easy to find, looking at the latest improvements that went live along with the general availability of the Logs app.
However, in the time series example below, we must determine whether the number of access attempts to our example Travel Mobile app is normal or abnormal. Three anomaly detection analyzers are available, each equipped with unique mechanisms to detect anomalies in your data that significantly deviate from the norm.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content