This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
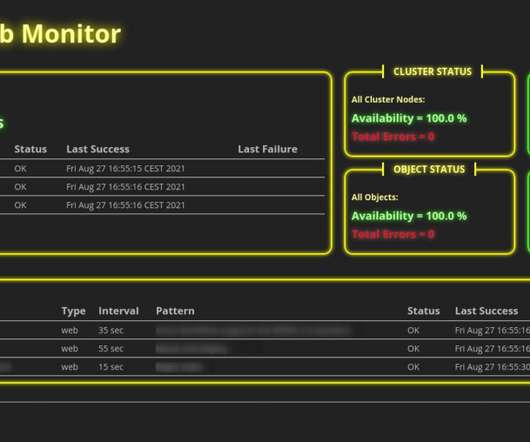
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Our script, available on GitHub , provides details. Are the corresponding services running on those hosts?
Onboarding teams using self-service Kubernetes selectors is one of the best examples of how Dynatrace embraces cloud native technologies to increase automation, reduce bureaucracy, and encourage agility. The following example drives the point home. Information about each of these topics will be available in upcoming announcements.
It automates tasks such as provisioning and scaling Dynatrace monitoring components, updating configurations, and ensuring the health and availability of your monitoring infrastructure. The scope of automatic workload instrumentation is user-configurable, for example, by namespace. Sign up for a fully functional Dynatrace free trial.
Thanks to the power of Grail, those details are available for all executions stored for the entire retention period during which synthetic results are kept. It now fully supports not only Network Availability Monitors but also HTTP synthetic monitors. Details of requests sent during each monitor execution are also available.
While selecting a Kubernetes segment, the selector provides a dynamic list of available resources. Segments can implement variables to dynamically provide, for example, a list of entities to users, such as available Kubernetes clusters, for unmatched flexibility and dynamic segmentation. What are Dynatrace Segments?
The automated extraction of ownership information, for example, from Kubernetes annotations, is therefore essential. Keeping ownership teams and their properties up to date is essential, as is having the right contact information available when needed. An example via Monaco can be found in this public GitHub repository.
In this article, we will explore the differences between monitoring and observability, provide examples to illustrate their applications and highlight their respective benefits. It typically involves setting up specific metrics, thresholds, and alerting mechanisms to track the performance and availability of various components.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. While the SLO management web UI and API are already available, the dashboard tile will be released within the next weeks.
As our customers adopt agile software development and continuous delivery to drive value faster, they face new risks that could impact availability, performance, and business KPIs. An SLI is a measurement of the performance or availability of an entity. Here is an example of a calculated metric for a service. Dynatrace news.
For example, optimizing resource utilization for greater scale and lower cost and driving insights to increase adoption of cloud-native serverless services. This is where unified observability and Dynatrace Automations can help by leveraging causal AI and analytics to drive intelligent automation across your multicloud ecosystem.
In this example, “Reverse proxy” and “Front-end server” are clearly in the critical path. In this example, “hipstershop.currency,” “hipstershop.checkout” and “hipstershop.cart” are also part of this critical path. In this example, we’re creating an SLO with a target of 98% of our requests without errors. Availability.
And there are a lot of monitoring tools available providing all kinds of features and concepts. For example, you can monitor the behavior of your applications, the hardware usage of your server nodes, or even the network traffic between servers. For that reason, we use monitoring tools.
After meeting the necessary requirements, we are excited to announce that the Dynatrace AI-powered platform as a SaaS on Microsoft Azure is now available in Switzerland. This represents the first observability solution available to Microsoft customers as a Switzerland-based SaaS deployment. Obligations to end users.
For example, the team must establish specific thresholds for desired service performance behavior. The Dynatrace data science team continuously improves the machine learning models used by Davis AI, for example, by adding new features to forecasting or refining mathematical calculations.
Since March 2024, the Dynatrace ® platform has been available on AWS in Tokyo, allowing customers to leverage the latest Dynatrace capabilities from Japan. Regulated sectors are making considerable effort to enable their organizations to use SaaS deployments (for example, ISMAP).
For example, a separate bucket could be used for detailed logs from Dynatrace Synthetic nodes. In conjunction with the previous example of keeping high-volume and short-lived logs separate, you might also need to keep your application data longer. Now, let’s take a look at a query example that puts this all into use.
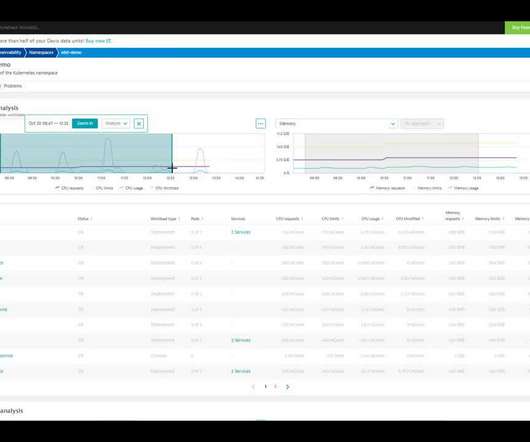
Kickstart your creation journey using ready-made dashboards and notebooks Creating dashboards and notebooks from scratch can take time, particularly when figuring out available data and how to best use it. An example of this is shown in the video above, where we incorporated network-related metrics into the Kubernetes cluster dashboard.
Take the example of Amazon Virtual Private Cloud (VPC) flow logs, which provide insights into the IP traffic of your network interfaces. With this out-of-the-box support for scalable data ingest, log data is immediately available to your teams for troubleshooting and observability, investigating security issues, or auditing.
For your reference, the complete working example is available on GitHub. By leveraging tools like Spring Boot Actuator , Micrometer with InfluxDB , and Grafana , you can gather meaningful insights easily and quickly. In this article, we'll walk through setting up this stack using a simple "Card-Playing" app/game as our use case.
The Clouds app provides a view of all available cloud-native services. Logs in context, along with other details, are instantly available after selecting a resource. The reasons are easy to find, looking at the latest improvements that went live along with the general availability of the Logs app.
However, in the time series example below, we must determine whether the number of access attempts to our example Travel Mobile app is normal or abnormal. Three anomaly detection analyzers are available, each equipped with unique mechanisms to detect anomalies in your data that significantly deviate from the norm.
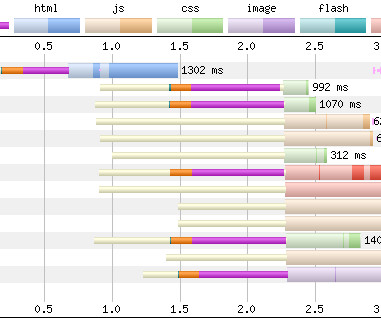
A trivial performance optimisation to help speed up third-party or other-origin requests is to preconnect them: hint that the browser should preemptively open a full connection ( DNS , TCP , TLS ) to the origin in question, for example: In the right circumstances, this simple, single line of HTML can make pages hundreds of milliseconds faster !
But how do you get started, and what are some service level objective examples? In this post, I’ll lay out five foundational service level objective examples that every DevOps and SRE team should consider. These organizations rely heavily on performance, availability, and user satisfaction to drive sales and retain customers.
OpenTelemetry SDKs are available for most contemporary programming languages, such as C++, Go, Java, JavaScript, and Python (see [link] for the full list). This example is a good starting point for exploratory analysis with context-aware Dynatrace Davis insights. order fulfillment, as well as a drop in fulfillment.
An application example is a session store recording recent actions. Application example: photo tagging; add a tag is an update, but most operations are to read tags. Application example: user profile cache, where profiles are constructed elsewhere (e.g., Application example: user status updates; people want to read the latest.
Note that the developers of the respective services need to make these metrics available by exposing them via, for example, a Prometheus endpoint that can be used by the OpenTelemetry collector to ingest them and forward them to your Dynatrace tenant. You can even walk through the same example above.
Dynatrace Flexible Identity Federation extends the currently available configuration options to include federation at the Dynatrace account or environment level. Take, for example, a fictitious enterprise customer, ACME Inc., Returning to our example above, ACME Inc. This configuration applies globally.
Automatic data capture and display: More data, including span attributes, is available for out-of-the-box analysis, with no additional configuration necessary. As soon as the new Distributed Tracing Experience is available for your environment, you’ll see a teaser banner in your classic Distributed Traces app.
A significant feature of Chronicle Queue Enterprise is support for TCP replication across multiple servers to ensure the high availability of application infrastructure. This is the first time I have benchmarked it with a realistic example. Little’s Law and Why Latency Matters.
And by “sample” we mean “an example”, like food samples in your local grocery store. The example business logic we use in our template computes the top hundred movies/shows in every country where Netflix operates on a daily basis. " ) COMMENT "Example dataset brought to you by Dataflow. test_sparksql_write.py
Every organization’s goal is to keep its systems available and resilient to support business demands. Example 1: Architecture boundaries. This view shows the availability SLO for key application functions, like login and vehicle list, as well as a large set of timeframes, like last 30 minutes, last hour, today, and last six days.
the newly released mobile app available on Android and iOS , uses Davis AIOps to push alert notifications directly to your phone and significantly reduce the incident response times. Let’s take a look at a typical SRE dashboard that shows all the essential SLOs of an example payment service software stack. Dynatrace 3.0,
Is my database cluster still highly available? All of our high availability options are offered in DigitalOcean, including 2 Replicas + 1 Arbiter, 3 Replicas and custom replica set setups. DigitalOcean does not have the concept of availability zones (AZ), so we distribute the nodes across different regions.
The log ingestion wizard offers support for all log ingestion methods available in Dynatrace Hub Get started with Logs: The OneAgent advantage For most scenarios, Dynatrace OneAgent is your best friend for getting started with Dynatrace log ingestion. Different log ingestion methods are available to address various needs.
While SSO has been available for Dynatrace Cloud Automation since day one, the latest update enables Dynatrace user management for RBAC in the Cloud Automation module—it’s now possible to define, for example, an admin with full permissions, a user with elevated permissions, or a user with basic view permissions.
Infrastructure health The underlying infrastructure’s health directly impacts application availability and performance. If the tools before Keptn begin generating OpenTelemetry data (for example, spans and traces), it would be beneficial to see Keptn’s portion of the work in the correct context as part of the same distributed trace.
To ensure continuous availability, it‘s essential to proactively analyze potential problems and optimize the environment in advance to minimize the negative impact on users and improve user experience. The proper focus and best optimization level must be chosen wisely to get the most out of the available time.
Syslog is the go-to protocol that delivers infrastructure administrators, network engineers, and security team logs that tell them all they need to know about their systems’ delivery, performance, availability, and security. Take a look at this example for configuration. Point your syslog sources to the collector and you’re done!
Especially when new security vulnerabilities are detected, collaboration with the right people—for example, the team responsible for a vulnerable service—is vital to keeping negative impact low and MTTR at a minimum. Creation of ITSM tickets (for example, Jira and ServiceNow) and assignment to the right teams.
You won’t know, for example, whether your 75th-percentile value for Largest contentful paint (LCP) is the result of some users experiencing slow resources because of a CDN issue or a poorly performing service in your back end. Core Web Vitals are available for synthetic monitors out of the box, without any additional configuration.
With the AI-powered Dynatrace platform now generally available on Azure, Azure Native Dynatrace Service customers can now leverage the full AI power of the Dynatrace platform directly from Azure. For example, Dynatrace uses automatic tagging to mark the user who created an Azure resource.
Lack of data: In many cases, available data may not be enough to make informed decisions due to data silos, distribution, or negligence. Example workflow for event-driven vulnerability reporting and escalation. Example for an app-provided workflow action. What’s next? Interested and want to learn more?
Example implementation scenario #1 The diagram below illustrates configuration-event-based remediation with Dynatrace and Red Hat Ansible Automation Controller for a failing canary release. Within Red Hat Ansible Automation Controller, the corresponding job template remediates the problem: in this example, the canary weighting is reset.
This way, it‘s possible to flexibly select what confidential or sensitive information (for example, PII) is hashed or completely removed before it leaves the enterprise premises. If a more granular rule is present on the host level, that rule will precede any blanket rule on, for example, the tenant level.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content