This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Business events: Delivering the best data It’s been two years since we introduced business events , a special class of events designed to support even the most demanding business use cases. Business event ingestion and analysis with log files. OpenPipeline: Simplify access and unify business events from anywhere.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. Are you experiencing an increase or degradation in certain events that indicate a rising problem?
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. In this blog post, we will give an overview of the Rapid Event Notification System at Netflix and share some of the learnings we gained along the way.
Streamlining observability with Dynatrace OneAgent on AWS Image Builder In our ongoing collaboration with AWS, we’re excited to make the Dynatrace OneAgent available as a first-class integration on AWS Image Builder via the AWS Marketplace.
Dynatrace Simple Workflows make this process automatic and frictionlessthere is no additional cost for workflows. Why manual alerting falls short As your product and deployments scale horizontally and vertically, the sheer volume of data makes it impossible for teams to catch every error quickly using manual processes.
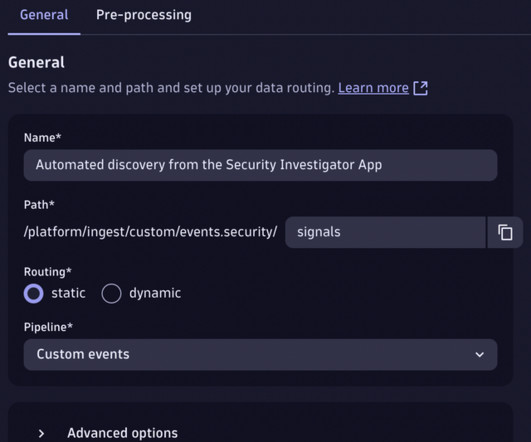
You now want to detect such events automatically by creating a custom Dynatrace security event. Ingest query results as security events The simplest way to do this is to use Dynatrace OpenPipeline. Set up a custom pipeline The best way to set up a security event ingestion to Dynatrace is via Dynatrace OpenPipeline.
The business process observability challenge Increasingly dynamic business conditions demand business agility; reacting to a supply chain disruption and optimizing order fulfillment are simple but illustrative examples. Most business processes are not monitored. First and foremost, it’s a data problem.
A Data Movement and Processing Platform @ Netflix By Bo Lei , Guilherme Pires , James Shao , Kasturi Chatterjee , Sujay Jain , Vlad Sydorenko Background Realtime processing technologies (A.K.A stream processing) is one of the key factors that enable Netflix to maintain its leading position in the competition of entertaining our users.
Unrealized optimization potential of business processes due to monitoring gaps Imagine a retail company facing gaps in its business process monitoring due to disparate data sources. Due to separated systems that handle different parts of the process, the view of the process is fragmented.
Business events powered by our new Grail™ data lakehouse and by other Dynatrace platform technologies ensures the real-time precision that business and IT teams need to make data-driven decisions and improve business outcomes. Business events deliver the industry’s broadest, deepest, and easiest access to your critical business data.
Managing High Availability (HA) in your PostgreSQL hosting is very important to ensuring your database deployment clusters maintain exceptional uptime and strong operational performance so your data is always available to your application. Effective management of failover and switchover operations is crucial for high availability.
There are three high-level steps to set up the database business-event stream. Step-by-step: Set up a custom MySQL database extension Now we’ll show you step-by-step how to create a custom MySQL database extension for querying and pushing business data to the Dynatrace business events endpoint. Don’t rename the file.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
Business events are a special class of events, new to Business Analytics; together with Grail, our data lakehouse, they provide the precision and advanced analytics capabilities required by your most important business use cases. What are business events? This diagram shows a few examples of business events.
Kickstart your creation journey using ready-made dashboards and notebooks Creating dashboards and notebooks from scratch can take time, particularly when figuring out available data and how to best use it. Kickstarting the dashboard creation process is, however, just one advantage of ready-made dashboards.
Even worse, if your service logs record critical events such as errors in a non-standard way, those errors might go unnoticed by your observability team. Whether a web server, mobile app, backend service, or other custom application, log data can provide you with deep insights into your software’s operations and events.
The application consists of several microservices that are available as pod-backed services. In addition to logs, and events, Dynatrace surfaces logs streamed from Fluentd so that you can analyze those logs in context with traces and services. Information about each of these topics will be available in upcoming announcements.
By Abhinaya Shetty , Bharath Mummadisetty In the inaugural blog post of this series, we introduced you to the state of our pipelines before Psyberg and the challenges with incremental processing that led us to create the Psyberg framework within Netflix’s Membership and Finance data engineering team.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. What is Apache Kafka?
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. But is five nines availability attainable? Downtime per year. 90% (one nine).
Sometimes, introducing new IT solutions is delayed or canceled because a single business unit can’t manage the operating costs alone, and per-department cost insights that could facilitate cost sharing aren’t available. Figure 4: Set up an anomaly detector for peak cost events.
Ensuring smooth operations is no small feat, whether you’re in charge of application performance, IT infrastructure, or business processes. Activate Davis AI to analyze charts within seconds Davis AI can help you expand your dashboards and dive deeper into your available data to extract additional information.
The volume of data and events grows in tandem with the rising complexity of IT infrastructure. SNMP provides access to availability and performance indicators. While SNMP allows you to query monitored devices for performance information, SNMP traps are used to proactively report certain types of events.
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. Data is then dynamically routed into pipelines for further processing. Understanding the context. Addressing security requirements.
By leveraging Dynatrace observability on Red Hat OpenShift running on Linux, you can accelerate modernization to hybrid cloud and increase operational efficiencies with greater visibility across the full stack from hardware through application processes. Dynatrace observability is available for Red Hat OpenShift on IBM Power.
Smartscape topology visualizes the relationships between applications, services, processes, hosts, and data centers, highlighting problems and vulnerabilities. Site Reliability Guardian provides an automated change impact analysis to validate service availability, performance, and capacity objectives across various systems.
The end goal, of course, is to optimize the availability of organizations’ software. Dynatrace is widely recognized for its AI capabilities’ ability to predict and prevent issues, and automatically identify root causes, maximizing availability.
Given our relatively frequent releases, this means that you can benefit from 11 to 12 OneAgent updates a year that are deployed as soon as they are available for your environment. Each maintenance window can be defined either as a one-off event or a recurring event. a one-off event). Just select Update ActiveGate.
Among the spectrum of methodologies available for this task, batch processing is often considered an old guard, especially with the advent of real-time and event-based processing technologies. However, it would be a mistake to dismiss batch processing as an antiquated approach.
We’re happy to announce the General Availability of cross-environment dashboarding capabilities (having released this functionality in an Early Adopter release with Dynatrace version 1.172 back in June 2019). Keep the token secret available for the second and final configuration step. Dynatrace news.
Dynatrace Managed is intrinsically highly available as it stores three copies of all events, user sessions, and metrics across its cluster nodes. Our Premium High Availability comes with the following features: Active-active deployment model for optimum hardware utilization. Dynatrace news.
The impetus for constructing a foundational recommendation model is based on the paradigm shift in natural language processing (NLP) to large language models (LLMs). To harness this data effectively, we employ a process of interaction tokenization, ensuring meaningful events are identified and redundancies are minimized.
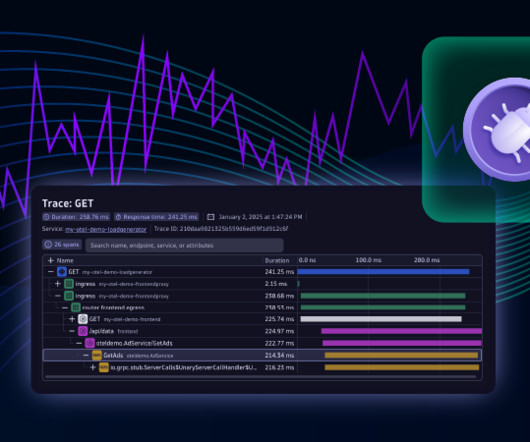
Upon detecting a high CPU load, Davis AI generates a problem event and populates it with a direct link to Live Debugger. Using this data, developers can inspect local variables, server-process details, thread information, and trace data to identify the root cause of issues.
This powerful tool can be leveraged across various environments, including production, to enhance development processes and ensure robust application performance. Many developers attempt to mitigate this challenge with logs, but thats a tedious and error-prone process. Distributed services involve multiple processes and runtimes.
Implementing clustering and quorum queues in RabbitMQ significantly improves load distribution and data redundancy, ensuring high availability and fault tolerance for messaging services. Classic queues can be used in clusters, emphasizing their behavior during node failures, particularly regarding durability and availability.
In order to allow for this mimicking, many systems implement an event handling, where they convert our request into a call to the real service with properties enabled to log when titles are filtered out of their response and why. As a result, requests are uniformly handled, and responses are processed cohesively.
A tight integration between Red Hat Ansible Automation Platform, Dynatrace Davis ® AI, and the Dynatrace observability and security platform enables closed-loop remediation to automate the process from: Detecting a problem. Managing incidents in corresponding tools. Identifying the root cause and proper countermeasures.
Define custom events that can either trigger deeper analysis or contribute additional contextual information to Davis. The improved configuration workflow for custom event alerting offers a lot of power in terms of defining additional metric-based events for your Dynatrace environment. We opened up the Davis 2.0
Today, development teams suffer from a lack of automation for time-consuming tasks, the absence of standardization due to an overabundance of tool options, and insufficiently mature DevSecOps processes. This process begins when the developer merges a code change and ends when it is running in a production environment.
Controller Manager: Runs controllers such as the node controller responsible for handling node availability. The post Keeping an eye on your control plane is critical to ensuring the high availability and health of your self-managed OpenShift Container Platform appeared first on Dynatrace blog.
One issue that often complicates this process is the "noisy neighbor" problem. The sched_wakeup and sched_wakeup_new hooks are invoked when a process changes state from 'sleeping' to 'runnable.' ' They let us identify when a process is ready to run and is waiting for CPU time.
A key learning from the outage caused by the faulty CrowdStrike “Rapid Response” update is how critical it is to understand your vendors’ quality control and release processes. A variety of events and circumstances can cause an outage. What is your testing process? Questions to ask a vendor: How frequently do you release?
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. When handling large amounts of complex data, or big data, chances are that your main machine might start getting crushed by all of the data it has to process in order to produce your analytics results. Query Optimization.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content