This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article is the second in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. Need to catch up? Check out Part 1. Because games differ from series/films, its crucial to validate this estimation method for games.
You can now: Kickstart your creation journey using ready-made dashboards Accelerate your data exploration with seamless integration between apps Start from scratch with the new Explore interface Search for known metrics from anywhere Let’s look at each of these paths through an end-to-end use case focused on Kubernetes monitoring.
Thanks to the power of Grail, those details are available for all executions stored for the entire retention period during which synthetic results are kept. It now fully supports not only Network Availability Monitors but also HTTP synthetic monitors. Details of requests sent during each monitor execution are also available.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. While the SLO management web UI and API are already available, the dashboard tile will be released within the next weeks.
Back during Perform 2019, we introduced the next generation of the Dynatrace AI causation engine , also known as Davis. becomes the default causation engine and will replace the previous version as the default for all new environments. as the default AI engine. AI causation engine. All existing Davis 1.0
For busy site reliability engineers, ensuring system reliability, scalability, and overall health is an imperative that’s getting harder to achieve in ever-expanding, cloud-native, container-based environments. To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. What is Prometheus?
For quite some time already, Dynatrace has provided full observability into AWS services by ingesting CloudWatch metrics that are published by AWS services. Amazon CloudWatch gathers metric data from various services that run on AWS. Dynatrace ingests this data to perform root-cause analysis using the Dynatrace Davis® AI engine.
The release candidate of OpenTelemetry metrics was announced earlier this year at Kubecon in Valencia, Spain. Since then, organizations have embraced OTLP as an all-in-one protocol for observability signals, including metrics, traces, and logs, which will also gain Dynatrace support in early 2023.
Dynatrace, available as an Azure-native service , has a longstanding partnership with Microsoft, deeply rooted in a strong “build with” approach to deliver seamless user experience. The Davis AI engine automatically and continuously delivers actionable insights based on an environment’s current state.
From a cost perspective, internal customers waste valuable time sending tickets to operations teams asking for metrics, logs, and traces to be enabled. A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. This approach is costly and error prone.
This approach enhances key DORA metrics and enables early detection of failures in the release process, allowing SREs more time for innovation. This blog post explores the Reliability metric , which measures modern operational practices. It forms the cornerstone of chaos engineering experiments. Why reliability?
Dynatrace full stack observability for Red Hat OpenShift Dynatrace enhances software quality and operational efficiency, which drives innovation by unifying application, operation, and platform engineering teams on a single platform. You can automatically detect and analyze performance issues across your entire tech stack with Davis® AI.
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Our script, available on GitHub , provides details. into NAM test definitions.
In response to this shift, platform engineering is growing in popularity. The practice of platform engineering has evolved alongside the increasing complexity of cloud environments. Platform engineers design and implement these platforms, as well as ensure their security, scalability, and reliability.
For years, logs have been the dominant approach many observability vendors have taken to report business metrics on dashboards. Most of the use cases in these two broad categories benefit from the flexibility that comes from multiple available sources of business data.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of software engineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026.
Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. Even if infrastructure metrics aren’t your thing, you’re welcome to join us on this creative journey simply swap out the suggested metrics for ones that interest you.
A Dynatrace API token with the following permissions: Ingest OpenTelemetry traces ( openTelemetryTrace.ingest ) Ingest metrics ( metrics.ingest ) Ingest logs ( logs.ingest ) To set up the token, see Dynatrace API – Tokens and authentication in Dynatrace documentation. If you don’t have one, you can use a trial account.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. The pair showed how to track factors including developer velocity, platform adoption, DevOps research and assessment metrics, security, and operational costs.
Dynatrace industry-leading tracing, metrics, and log ingestion provide the level of high fidelity data that teams need to make accurate predictions about capacity. This is important because manual tracing is super costly and there is a lack of information available on this topic to assist developers.
In this blog, I will be going through a step-by-step guide on how to automate SRE-driven performance engineering. These tags will allow us to create dashboards, request attributes or calculate service metrics specifically for our application under test. This allows us to analyze metrics (SLIs) for each individual endpoint URL.
Dynatrace has recently extended its Kubernetes operator by adding a new feature, the Prometheus OpenMetrics Ingest , which enables you to import Prometheus metrics in Dynatrace and build SLO and anomaly detection dashboards with Prometheus data. Here we’ll explore how to collect Prometheus metrics and what you can achieve with them.
The end goal, of course, is to optimize the availability of organizations’ software. Dynatrace is widely recognized for its AI capabilities’ ability to predict and prevent issues, and automatically identify root causes, maximizing availability. Eventually, the goal is to arrive at self-healing through autonomous cloud operations.
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. But is five nines availability attainable? Downtime per year. 90% (one nine).
Stream processing enables software engineers to model their applications’ business logic as high-level representations in a directed acyclic graph without explicitly defining a physical execution plan. We designed experimental scenarios inspired by chaos engineering. Recovery time of the throughput metric.
Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. Davis topology-aware anomaly detection and alerting for your Micrometer metrics. Topology-related custom metrics for seamless reports and alerts. Micrometer uses a registry to export metrics to monitoring systems.
OpenTelemetry metrics are useful for augmenting the fully automatic observability that can be achieved with Dynatrace OneAgent. OpenTelemetry metrics add domain specific data such as business KPIs and license relevant consumption details. Enterprise-grade observability for custom OpenTelemetry metrics from AWS. Dynatrace news.
Now, Dynatrace has the ability to turn numerical values from logs into metrics, which unlocks AI-powered answers, context, and automation for your apps and infrastructure, at scale. The parameter Billed Duration is only available in logs , so it makes sense to extract it from your logs so that you can keep an eye on your cloud costs.
Chances are, youre a seasoned expert who visualizes meticulously identified key metrics across several sophisticated charts. Activate Davis AI to analyze charts within seconds Davis AI can help you expand your dashboards and dive deeper into your available data to extract additional information.
Welcome back to the blog series where we provide you with deeper dives into the latest observability awesomeness from Dynatrace , demonstrating how we bring scale, zero configuration, automatic AI-driven alerting, and root cause analysis to all your custom metrics, including open source observability frameworks like StatsD, Telegraf, and Prometheus.
A Kubernetes SLO that continuously evaluates CPU, memory usage, and capacity and compares these available resources to the requested and utilized memory of Kubernetes workloads makes potential resource waste visible, revealing opportunities for countermeasures.
Dynatrace Managed is intrinsically highly available as it stores three copies of all events, user sessions, and metrics across its cluster nodes. Our Premium High Availability comes with the following features: Active-active deployment model for optimum hardware utilization. Dynatrace news.
address these limitations and brings new monitoring and analytical capabilities that weren’t available to Extensions 1.0: Comprehensive metrics support Extensions 2.0 These bundles ensure the provisioning of pre-configured dashboards, alerts, unified analysis views, and a topology model that relates metrics and entities.
When it comes to platform engineering, not only does observability play a vital role in the success of organizations’ transformation journeys—it’s key to successful platform engineering initiatives. The various presenters in this session aligned platform engineering use cases with the software development lifecycle.
While Fluentd solves the challenges of collecting and normalizing Kubernetes events and logs, Kubernetes performance and availability problems can rarely be solved by investigating logs in isolation. All metrics, traces, and real user data are also surfaced in the context of specific events.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance Data Engineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. Our audits would detect this and alert the on-call data engineer (DE).
Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. This dual availability ensures immediate processing capabilities alongside comprehensive long-term data retention.
At the heart of Dynatrace Digital Experience Monitoring (DEM) is Davis, the state-of-the-art AI engine that accurately prioritizes the severity of each detected performance anomaly in terms of its potential impact on real users and business KPIs. Leverage AI assistance to deliver better customer experience. How to get started.
The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data. The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data.
The standard dictionary subscript notation is also available. Imagine a ML practitioner on the Netflix Content ML team, sourcing features from hundreds of columns in our data warehouse, and creating a multitude of models against a growing suite of metrics. You can access Configs of any past runs easily through the Client API.
By the summer of 2020, many UI engineers were ready to move to GraphQL. The GraphQL shim enabled client engineers to move quickly onto GraphQL, figure out client-side concerns like cache normalization, experiment with different GraphQL clients, and investigate client performance without being blocked by server-side migrations.
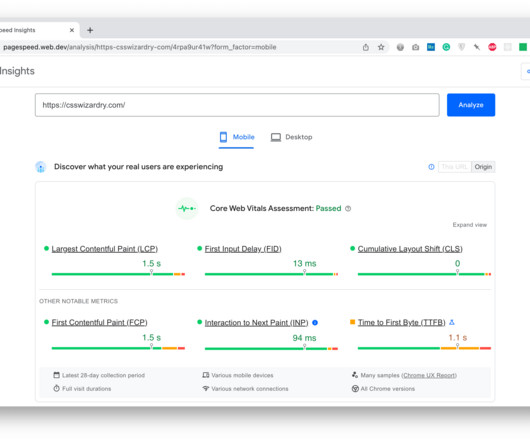
I am available to help you find and fix your site-speed issues through performance audits , training and workshops , consultancy , and more. Web Vitals I still feel that site owners who are serious about web performance should augment Core Web Vitals with their own custom metrics (e.g. You should get in touch.
Open-source metric sources automatically map to our Smartscape model for AI analytics. With this announcement, Dynatrace brings the value of its AI engine, the scale, security, and automation of Dynatrace OneAgent and the scale of our platform (which can handle 50,000 hosts) to open source technologies so that you get the best of both worlds.
Build an umbrella for Development and Operations In modern software engineering, the discipline of platform engineering delivers DevSecOps practices to developers to bridge the gaps between development, security, and operations and enhance the developer experience. However, other data formats, like logs, can also be employed.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content