This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article is the second in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. Need to catch up? Check out Part 1. Because games differ from series/films, its crucial to validate this estimation method for games.
The problems with degraded service availability along with revenue impact occur mainly because of Kubernetes pod crashes along with resource exhaustion and network disruptions that hit during peak shopping seasons.
Back during Perform 2019, we introduced the next generation of the Dynatrace AI causation engine , also known as Davis. becomes the default causation engine and will replace the previous version as the default for all new environments. as the default AI engine. AI causation engine. All existing Davis 1.0
In response to this shift, platform engineering is growing in popularity. The practice of platform engineering has evolved alongside the increasing complexity of cloud environments. Platform engineers design and implement these platforms, as well as ensure their security, scalability, and reliability.
Since most application releases depend on cloud infrastructure, having good continuous integration and continuous delivery (CI/CD) pipelines and end-to-end observability becomes essential for ensuring highly available systems.
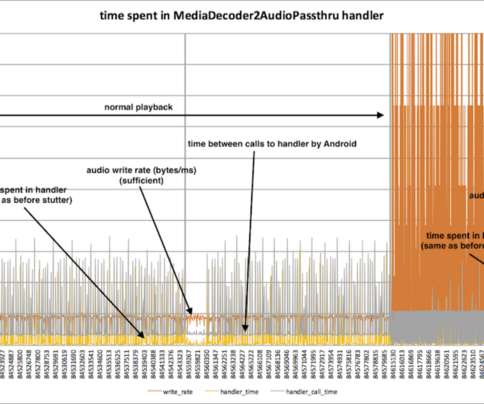
Life of a Netflix Partner Engineer?—?The The case of the extra 40 ms By: John Blair , Netflix Partner Engineering The Netflix application runs on hundreds of smart TVs, streaming sticks and pay TV set top boxes. The role of a Partner Engineer at Netflix is to help device manufacturers launch the Netflix application on their devices.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of software engineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026.
To enhance reliability, testing the software under these conditions is crucial to prepare for potential issues by leveraging chaos engineering or similar tools. Chaos engineering is a practice that extends beyond traditional failure testing by identifying unpredictable issues. It forms the cornerstone of chaos engineering experiments.
Meetings are a crucial aspect of software engineering , serving as a collaboration, communication, and decision-making platform. In this article, we will delve deeper into the issues associated with meetings in software engineering and explore the available data.
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Our script, available on GitHub , provides details. into NAM test definitions.
The application consists of several microservices that are available as pod-backed services. Only Dynatrace provides this level of depth and breadth across Kubernetes clusters , from infrastructure level information needed by operations teams, all the way down to code-level inefficiencies that are best handled by application engineers.
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. But is five nines availability attainable? Downtime per year. 90% (one nine).
Dynatrace full stack observability for Red Hat OpenShift Dynatrace enhances software quality and operational efficiency, which drives innovation by unifying application, operation, and platform engineering teams on a single platform. Learn more about the new Kubernetes Experience for Platform Engineering.
At Dynatrace, we understand your challenges when dealing with external packageswhether you’re hustling with reverse engineering, automatically fetching open source code, or playing the guessing game. Source code is loaded only on an engineers workstation, using the engineers privileges.
Site reliability engineering first emerged to address cloud computing’s new performance needs. Today, the platform engineer role is gaining speed as the newest byproduct of scaling DevOps in the emerging but complex cloud-native world. Understanding the platform engineer role DevOps is a constantly evolving discipline.
The end goal, of course, is to optimize the availability of organizations’ software. Dynatrace is widely recognized for its AI capabilities’ ability to predict and prevent issues, and automatically identify root causes, maximizing availability. Eventually, the goal is to arrive at self-healing through autonomous cloud operations.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. Platform engineering: Build for self-service Self-service deployment is a key attribute of platform engineering. “It makes them more productive.
Thanks to the power of Grail, those details are available for all executions stored for the entire retention period during which synthetic results are kept. It now fully supports not only Network Availability Monitors but also HTTP synthetic monitors. Details of requests sent during each monitor execution are also available.
Stream processing enables software engineers to model their applications’ business logic as high-level representations in a directed acyclic graph without explicitly defining a physical execution plan. We designed experimental scenarios inspired by chaos engineering. Chaos scenario: Random pods executing worker instances are deleted.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? .” What are DevOps engineer tools and platforms.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. While the SLO management web UI and API are already available, the dashboard tile will be released within the next weeks.
Kickstart your creation journey using ready-made dashboards and notebooks Creating dashboards and notebooks from scratch can take time, particularly when figuring out available data and how to best use it. This feature lets you explore any available metric and add it to Notebooks or Dashboards.
When it comes to platform engineering, not only does observability play a vital role in the success of organizations’ transformation journeys—it’s key to successful platform engineering initiatives. The various presenters in this session aligned platform engineering use cases with the software development lifecycle.
By Alex Hutter , Falguni Jhaveri and Senthil Sayeebaba Over the past few years Content Engineering at Netflix has been transitioning many of its services to use a federated GraphQL platform. it began to power a significant portion of the user experience for many applications within Content Engineering.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance Data Engineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. Our audits would detect this and alert the on-call data engineer (DE).
This standardization enhances adoption within the personalization stack, simplifies the system, and improves understanding and debuggability for engineers. They must also provide enough information for partner engineers to identify the problem with the underlying service in cases of system-level issues.
AV1 is one of the most efficient codecs available today. Title must be available in HDR10+format 3. We would like to extend our thanks to the following teams for their crucial roles in thislaunch: The various Client and Partner Engineering teams at Netflix that manage the Netflix experience across different device platforms.
Dynatrace, available as an Azure-native service , has a longstanding partnership with Microsoft, deeply rooted in a strong “build with” approach to deliver seamless user experience. The Davis AI engine automatically and continuously delivers actionable insights based on an environment’s current state.
Enterprise adoption with self-service: To facilitate enterprise adoption while minimizing tool sprawl and data silos, Dynatrace allows observability teams and platform engineers to implement a self-service model for developers.
Site reliability engineering (SRE) plays a vital role in ensuring Java applications' high availability, performance, and scalability. This discipline merges software engineering and operations, aiming to create a robust infrastructure that supports seamless user experiences.
For busy site reliability engineers, ensuring system reliability, scalability, and overall health is an imperative that’s getting harder to achieve in ever-expanding, cloud-native, container-based environments. Because of its adaptability, Prometheus has become an essential tool for observability engineering. Jolly good!
Automatic data capture and display: More data, including span attributes, is available for out-of-the-box analysis, with no additional configuration necessary. As soon as the new Distributed Tracing Experience is available for your environment, you’ll see a teaser banner in your classic Distributed Traces app.
address these limitations and brings new monitoring and analytical capabilities that weren’t available to Extensions 1.0: What’s available now and what’s coming later We’ve already started to migrate Dynatrace-developed Extensions 1.0 available, and more are in the pipeline. Extensions 2.0 to the Extension Framework 2.0.
Repetitive tasks in incident response waste time When investigating incidents in production, engineers typically start each investigation with similar queries to understand what happened and where to look next, though the specifics can vary. Case templates provide engineers with a boilerplate for their investigation.
Site Reliability Guardian provides an automated change impact analysis to validate service availability, performance, and capacity objectives across various systems. Leveraging code-level insights and transaction analysis, Dynatrace Runtime Application Protection automatically detects attacks on applications in your environment.
Following are some of the coolest things weve seen engineers do with Live Debugger. Performance benchmarking Performance benchmarking is one of the unresolved mysteries of software engineering. White box testing The nicest thing about deploying UI changes to production is that you can immediately see the changes in action.
Most of the use cases in these two broad categories benefit from the flexibility that comes from multiple available sources of business data. Log data is then processed accordingly, stored in Dynatrace Grail™ causational data lakehouse, and available for your Business Analytics use cases.
Note that the developers of the respective services need to make these metrics available by exposing them via, for example, a Prometheus endpoint that can be used by the OpenTelemetry collector to ingest them and forward them to your Dynatrace tenant.
I am available to help you find and fix your site-speed issues through performance audits , training and workshops , consultancy , and more. But for many queries, there is lots of helpful content available. I’m available for hire to help you out with workshops , consultancy , advice , and development. . You should get in touch.
Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. This dual availability ensures immediate processing capabilities alongside comprehensive long-term data retention.
The complexity and numerous moving parts of Kubernetes multicloud clusters mean that when monitoring the health of these clusters—which is critical for ensuring reliable and efficient operation of the application—platform engineers often find themselves without an easy and efficient solution.
A Kubernetes SLO that continuously evaluates CPU, memory usage, and capacity and compares these available resources to the requested and utilized memory of Kubernetes workloads makes potential resource waste visible, revealing opportunities for countermeasures.
Site reliability engineering (SRE) is a discipline in which automated software systems are built to manage the development operations (DevOps) of a product or service. In other words, SRE automates the functions of an operations team via software systems.
Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. As you went through these steps, you likely noticed some of the chart options available. Also, explore additional dashboards available on the Dynatrace Playground.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content