This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As modern multicloud environments become more distributed and complex, having real-time insights into applications and infrastructure while keeping data residency in local markets is crucial. As of October 2024, Dynatrace is available on Microsoft Azure Australia East region, enabling joint customers to maintain a local SaaS presence.
These innovations promise to streamline operations, boost efficiency, and offer deeper insights for enterprises using AWS services. This seamless integration accelerates cloud adoption, allowing enterprises to maximize the value of their AWS infrastructure and focus on innovation rather than managing observability configurations.
A good Kubernetes SLO strategy helps teams manage and make containerized workloads more efficient. Efficient coordination of resource usage, requests, and allocation is critical. As every container has defined requests for CPU and memory, these indicators are well-suited for efficiency monitoring.
However, this category requires near-immediate access to the current count at low latencies, all while keeping infrastructure costs to a minimum. Eventually Consistent : This category needs accurate and durable counts, and is willing to tolerate a slight delay in accuracy and a slightly higher infrastructure cost as a trade-off.
Boost your operational resilience: Combining availability and security is now essential. In dynamic and distributed cloud environments, the process of identifying incidents and understanding the material impact is beyond human ability to manage efficiently. Its time to adopt a unified observability and security approach.
By leveraging Dynatrace observability on Red Hat OpenShift running on Linux, you can accelerate modernization to hybrid cloud and increase operational efficiencies with greater visibility across the full stack from hardware through application processes. Dynatrace observability is available for Red Hat OpenShift on IBM Power.
Track business metrics, key performance indicators (KPIs), and service level objectives (SLOs) — automatically and in context with IT infrastructure and services — to promote collaboration between business and IT teams. Simplified and enhanced analytics efficiency. Business process monitoring and optimization.
To solve this problem , Dynatrace offers a fully automated approach to infrastructure and application observability including Kubernetes control plane, deployments, pods, nodes, and a wide array of cloud-native technologies. None of this complexity is exposed to application and infrastructure teams.
Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. With Dashboards , you can monitor business performance, user interactions, security vulnerabilities, IT infrastructure health, and so much more, all in real time.
Dynatrace, available as an Azure-native service , has a longstanding partnership with Microsoft, deeply rooted in a strong “build with” approach to deliver seamless user experience. This enables Dynatrace customers to achieve faster time-to-value and accelerate innovation. Click here to read our full press release.
This demand for rapid innovation is propelling organizations to adopt agile methodologies and DevOps principles to deliver software more efficiently and securely. And how do DevOps monitoring tools help teams achieve DevOps efficiency? Moreover, most organizations use a combination of cloud-based and on-premises infrastructure.
Today, the composable nature of code enables skilled IT teams to create and customize automated solutions capable of improving efficiency. ” While this methodology extends to every layer of the IT stack, infrastructure as code (IAC) is the most prominent example. What is infrastructure as code? Consistency. A lignment.
In today's digital landscape, businesses heavily rely on content delivery networks (CDNs) to ensure efficient and reliable delivery of their web content to users across the globe. However, the extended infrastructure of CDNs requires diligent monitoring to ensure optimal performance and identify potential issues.
Infrastructure monitoring is the process of collecting critical data about your IT environment, including information about availability, performance and resource efficiency. Many organizations respond by adding a proliferation of infrastructure monitoring tools, which in many cases, just adds to the noise.
IT infrastructure is the heart of your digital business and connects every area – physical and virtual servers, storage, databases, networks, cloud services. We’ve seen the IT infrastructure landscape evolve rapidly over the past few years. What is infrastructure monitoring? . Minimizes downtime and increases efficiency.
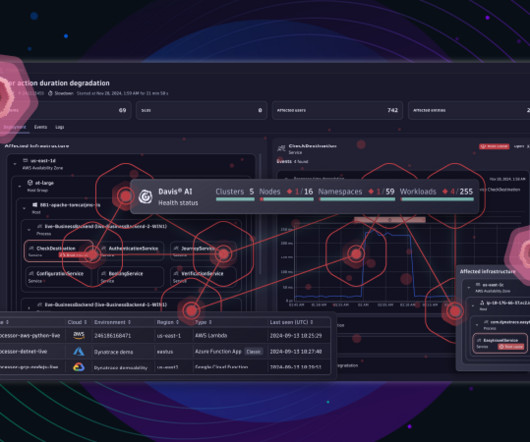
Infrastructure and operations teams must maintain infrastructure health for IT environments. With the Infrastructure & Operations app ITOps teams can quickly track down performance issues at their source, in the problematic infrastructure entities, by following items indicated in red. What’s next?
Ensuring smooth operations is no small feat, whether you’re in charge of application performance, IT infrastructure, or business processes. Activate Davis AI to analyze charts within seconds Davis AI can help you expand your dashboards and dive deeper into your available data to extract additional information.
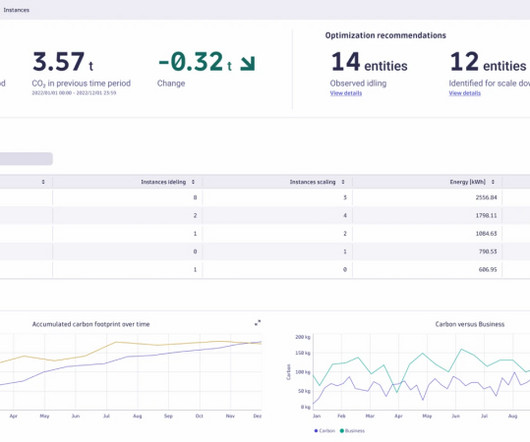
This is partly due to the complexity of instrumenting and analyzing emissions across diverse cloud and on-premises infrastructures. Integration with existing systems and processes : Integration with existing IT infrastructure, observability solutions, and workflows often requires significant investment and customization.
This allows teams to sidestep much of the cost and time associated with managing hardware, platforms, and operating systems on-premises, while also gaining the flexibility to scale rapidly and efficiently. In a serverless architecture, applications are distributed to meet demand and scale requirements efficiently.
This leads to a more efficient and streamlined experience for users. Lastly, monitoring and maintaining system health within a virtual environment, which includes efficient troubleshooting and issue resolution, can pose a significant challenge for IT teams. We’re always looking for feedback and opportunities to improve.
Kafka scales efficiently for large data workloads, while RabbitMQ provides strong message durability and precise control over message delivery. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. This allows Kafka clusters to handle high-throughput workloads efficiently.
Managing High Availability (HA) in your PostgreSQL hosting is very important to ensuring your database deployment clusters maintain exceptional uptime and strong operational performance so your data is always available to your application. Effective management of failover and switchover operations is crucial for high availability.
The end goal, of course, is to optimize the availability of organizations’ software. Dynatrace AI increases efficiency by magnitudes and prevents alert storms. Dynatrace is widely recognized for its AI capabilities’ ability to predict and prevent issues, and automatically identify root causes, maximizing availability.
These insights have shaped the design of our foundation model, enabling a transition from maintaining numerous small, specialized models to building a scalable, efficient system. At inference time, when multi-step decoding is needed, we can deploy KV caching to efficiently reuse past computations and maintain lowlatency.
This guide will cover how to distribute workloads across multiple nodes, set up efficient clustering, and implement robust load-balancing techniques. Implementing clustering and quorum queues in RabbitMQ significantly improves load distribution and data redundancy, ensuring high availability and fault tolerance for messaging services.
In this blog post, youll learn how Dynatrace OneAgent automatically identifies Journald and ingests structured logs into Dynatrace while enriching them with topology and infrastructure context. Thanks to its structured and binary format, Journald is quick and efficient.
By leveraging the Dynatrace Operator and Dynatrace capabilities on Red Hat OpenShift on IBM Power, customers can accelerate their modernization to hybrid cloud and increase operational efficiencies with greater visibility across the full stack from hardware through application processes.
You can either continue with the custom infrastructure metrics dashboard you created in Part I or use the dashboard we prepared here (Dynatrace login required). exploring your data when you know your desired outcome but are unfamiliar with the available data.
With more organizations taking the multicloud plunge, monitoring cloud infrastructure is critical to ensure all components of the cloud computing stack are available, high-performing, and secure. Website monitoring examines a cloud-hosted website’s processes, traffic, availability, and resource use. Website monitoring.
The development of internal platform teams has taken off in the last three years, primarily in response to the challenges inherent in scaling modern, containerized IT infrastructures. Platform engineering best practices for delivering a highly available, secure, and resilient Internal Development Platform: Centralize and standardize.
Challenges The cloud network infrastructure that Netflix utilizes today consists of AWS services such as VPC, DirectConnect, VPC Peering, Transit Gateways, NAT Gateways, etc and Netflix owned devices. These metrics are visualized using Lumen , a self-service dashboarding infrastructure.
These developments open up new use cases, allowing Dynatrace customers to harness even more data for comprehensive AI-driven insights, faster troubleshooting, and improved operational efficiency. Native support for syslog messages extends our infrastructure log support to all Linux/Unix systems and network devices.
This necessitates a comprehensive platform that empowers enterprises to understand IT and software within the broader context of their business operations, giving them confidence that their software and IT infrastructure are reliable.
For IT infrastructure managers and site reliability engineers, or SREs , logs provide a treasure trove of data. These traditional approaches to log monitoring and log analytics thwart IT teams’ goal to address infrastructure performance problems, security threats, and user experience issues. where an error occurred at the code level.
EdgeConnect facilitates seamless interaction, ensuring data security and operational efficiency. In this hybrid world, IT and business processes often span across a blend of on-premises and SaaS systems, making standardization and automation necessary for efficiency.
In this article, we’ll explore these challenges in detail and introduce Keptn, an open source project that addresses these issues, enhancing Kubernetes observability for smoother and more efficient deployments. Infrastructure health The underlying infrastructure’s health directly impacts application availability and performance.
Navigate digital infrastructure complexity In today’s rapidly evolving digital environment, organizations face increasing pressure from customers and competitors to deliver faster, more secure innovations. Use case: Digital infrastructure change The problem is not always in the application.
Kubernetes is an open-source orchestration engine for containerized applications that help to automate processes such as scaling, deployments, and management with greater efficiency. . Create web applications that are highly available across multiple availability zones and scales to meet your demanding consumption footprints .
Log management and analytics is an essential part of any organization’s infrastructure, and it’s no secret the industry has suffered from a shortage of innovation for several years. Several pain points have made it difficult for organizations to manage their data efficiently and create actual value.
Having released this functionality in an Preview Release back in September 2019, we’re now happy to announce the General Availability of our Citrix monitoring extension. Citrix is a sophisticated, efficient, and highly scalable application delivery platform that is itself comprised of anywhere from hundreds to thousands of servers.
As global warming advances, growing IT carbon footprints are pushing energy-efficient computing to the top of many organizations’ priority lists. Energy efficiency is a key reason why organizations are migrating workloads from energy-intensive on-premises environments to more efficient cloud platforms.
Efficient coordination among resource usage, requests, and allocation is critical. By gaining insights into how your Kubernetes workloads utilize computing and memory resources, you can make informed decisions about how to size and plan your infrastructure, leading to reduced costs.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. The goal is to abstract away the underlying infrastructure’s complexities while providing a streamlined and standardized environment for development teams.
The resulting vast increase in data volume highlights the need for more efficient data handling solutions. Application performance monitoring (APM) , infrastructure monitoring, log management, and artificial intelligence for IT operations (AIOps) can all converge into a single, integrated approach.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content