This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Migrating Critical Traffic At Scale with No Downtime — Part 2 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Picture yourself enthralled by the latest episode of your beloved Netflix series, delighting in an uninterrupted, high-definition streaming experience. This is where large-scale system migrations come into play.
The certification results are now publicly available. The calculations and methodology used are in line with the best available scientific approach, as well as with relevant reporting requirements. We are updating product documentation to include underlying static assumptions. Public network traffic uses 1.0
To do this, we devised a novel way to simulate the projected traffic weeks ahead of launch by building upon the traffic migration framework described here. New content or national events may drive brief spikes, but, by and large, traffic is usually smoothly increasing or decreasing.
The F5 BIG-IP Local Traffic Manager (LTM) is an application delivery controller (ADC) that ensures the availability, security, and optimal performance of network traffic flows. Business-critical applications typically rely on F5 for availability and success. It serves as a crucial component between applications and users.
Take the example of Amazon Virtual Private Cloud (VPC) flow logs, which provide insights into the IP traffic of your network interfaces. With this out-of-the-box support for scalable data ingest, log data is immediately available to your teams for troubleshooting and observability, investigating security issues, or auditing.
The subject line said: “Success Story: Major Issue in single AWS Frankfurt Availability Zone!” Fact #1: AWS EC2 outage properly documented. The problem started at 1:24PM PDT, with the services starting to become available again about 3 hours later. Fact #4: Multi-node, multi-availability zone deployment architecture.
ActiveGate also optimizes traffic volume in your network and serves as a secure relay layer in protected networks and DMZs. What’s next See these related resources for complete details about Dynatrace syslog support: Syslog ingestion is available with Dynatrace Environment ActiveGate version 1.295.
While most government agencies and commercial enterprises have digital services in place, the current volume of usage — including traffic to critical employment, health and retail/eCommerce services — has reached levels that many organizations have never seen before or tested against. So how do you know what to prepare for?
Read Also: Best PostgreSQL GUI Incremental Backups PostgreSQL 17 introduces incremental backups , a game-changer for large and high-traffic databases. Get automated backups, high availability, and seamless scalingso you can focus on your applications, not database maintenance. JSON_VALUE retrieves individual values from JSON documents.
Therefore, it was unsurprising to see a huge spike in traffic for Family Visa enrollment via Metrash. Let’s start with the spike in load: The high demand on family visa enrollments resulted in a huge traffic and CPU spike. Reason : High memory consumption of XPath queries when parsing application documents.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
Keeping threats documented is a challenge: Engineers typically open numerous tabs to maintain context, which is tedious and can create error. Clair determined what log data was available to her. As part of that documentation, I can easily go back and forth to see what was executed.” Using Dynatrace Query Language in Grail , St.
Its design prioritizes high availability and efficient data transfer with minimal overhead, making it a practical choice for handling real-time data pipelines and distributed event processing. It follows a push-based approach, ensuring messages are distributed to consumers as soon as they become available.
These signals ( latency, traffic, errors, and saturation ) provide a solid means of proactively monitoring operative systems via SLOs and tracking business success. SLOs, as a measure of service quality, can track the related availability, reliability, and performance.
WAFs protect the network perimeter and monitor, filter, or block HTTP traffic. Compared to intrusion detection systems (IDS/IPS), WAFs are focused on the application traffic. RASP solutions sit in or near applications and analyze application behavior and traffic. How to get started.
In large organizations, it’s not uncommon to have hundreds of applications — each with its own specific infrastructure requirements based on architecture, function, traffic, and more. Minimize overall documentation. Over-documentation reintroduces this issue and can lead to environments and configuration data being out of sync.
When deploying in production, it’s highly recommended to setup in a MongoDB replica set configuration so your data is geographically distributed for high availability. It is also recommended that SSL connections be enabled to encrypt the client-database traffic. Testing Failover Behavior. Defaults to 30000 (30 seconds).
Whether tracking internal, workload-centric indicators such as errors, duration, or saturation or focusing on the golden signals and other user-centric views such as availability, latency, traffic, or engagement, SLOs-as-code enables coherent and consistent monitoring throughout the environment at scale.
Sometimes, you need information about your system or application that is only available in log data—for example, when logging relevant data points from your application during the development stage for debugging. You can also check out the documentation for creating metrics from logs based on attribute values and ingesting logs via API.
It’s a cross-platform document-oriented database that uses JSON-like documents with schema, and is leveraged broadly across startup apps up to enterprise-level businesses developing modern apps. MongoDB is the #3 open source database and the #1 NoSQL database in the world. MongoDB Replication Strategies.
From reacting to keywords that signal special offers, browsing the latest products, adding items to the shopping cart, checking out, and handling shipping, all the details of each user journey is available in logs. FortiGate traffic logs store data elements in key-value pairs while NGINX custom access logs store events in arrays.
Unlike other monitoring tools on the market, which don’t provide AI-driven anomaly detection and alerting, Dynatrace delivers real-time data to track the performance of your deployed apps and the characteristics of your client traffic. For full details, see the Azure documentation. . Monitor and compare performance after slot swaps.
Two algorithms are available: RSA- SHA256 and RSA-SHA1. Two algorithms are available: SHA-256 and SHA-1. Available options include: document , assertion , both , or none. No more need to disable OneAgent traffic beforehand. Digest algorithm – Validates the integrity of messages. Other changes.
More efficient SSL/TLS handling for OneAgent traffic. By default, all OneAgent traffic is now routed to your embedded ActiveGate via NGINX on port 443. As announced with the release of Dynatrace Managed version 1.150 , we now route all incoming traffic through NGINX in an effort to increase performance and ease configuration effort.
Nonetheless, we found a number of limitations that could not satisfy our requirements e.g. stalling the processing of log events until a dump is complete, missing ability to trigger dumps on demand, or implementations that block write traffic by using table locks. Designed with High Availability in mind. Writing events to any output.
After a set amount of time, the flag is disabled – the offer is no longer available. Documentation for new features or “internal only” knowledge is placed behind a feature flag. When logged in, staff have access to documentation that no one else can see. The special offer is placed behind a feature flag.
Resource consumption & traffic analysis. What is the network traffic going to be between services we migrate and those that have to stay in the current data center? How much traffic is sent between two processes hosting a certain service? All available in Dynatrace in the UI or through the API!
Exploratory data analytics is an analysis method that uses visualizations, including graphs and charts, to help IT teams investigate emerging data trends and circumvent issues, such as unexpected traffic spikes or performance degradations. Type > to see a list of all available search categories.
With the average cost of unplanned downtime running from $300,000 to $500,000 per hour , businesses are increasingly using high availability (HA) technologies to maximize application uptime. Where a high availability design once worked well, it can no longer keep up with more complex requirements. there cannot be high availability.
Nonetheless, we found a number of limitations that could not satisfy our requirements e.g. stalling the processing of log events until a dump is complete, missing ability to trigger dumps on demand, or implementations that block write traffic by using table locks. Designed with High Availability in mind. Writing events to any output.
As I have talked about before, one of the reasons why we built Amazon DynamoDB was that Amazon was pushing the limits of what was a leading commercial database at the time and we were unable to sustain the availability, scalability, and performance needs that our growing Amazon.com business demanded. The opposite is true.
For example, when running tests, the state of the device will change from “available for testing” to “in test.” As such, we can see that the traffic load on the Device Management Platform’s control plane is very dynamic over time. Over the lifecycle of a device connected to the RAE, the device can change attributes at any time.
However, storing and querying such data presents a unique set of challenges: High Throughput : Managing up to 10 million writes per second while maintaining high availability. Handling Bursty Traffic : Managing significant traffic spikes during high-demand events, such as new content launches or regional failovers.
When it comes to enterprise-level databases, there are several options available in the market, but PostgreSQL stands out as one of the most popular and reliable choices. PostgreSQL is backed by a large community of developers contributing to its development, support, and documentation.
Once Dynatrace sees the incoming traffic it will also show up in Dynatrace, under Transaction & Services. For other tools either check out our documentation for Neoload , LoadRunner or JMeter. For more information please consult the Dynatrace documentation. SimpleNodeJsService.
This was a custom built, 3-step pipeline: Capture the production traffic for the desired path(s) Replay the traffic against the two services in the TEST environment Compare and assert for differences It was a self-contained flow that, by design, captured entire requests, and not just the one path we requested.
client is now generally available. Garden container and BOSH Process Manager (BPM) container monitoring have been released to General Availability. release includes automatic configuration of Istio for enabling egress traffic to Dynatrace clusters. Consult the documentation for upgrading to the new OneAgent Operator release.
With the Percona Operators, businesses can manage multi-cloud or hybrid-cloud PostgreSQL deployments with ease, ensuring that critical data is always available and secure, no matter what happens. Configure main site Use your favorite method to deploy the Operator from our documentation. Try Percona Operator for PostgreSQL today!
If you’re new to Conductor, this earlier blogpost and the documentation should help you get started and acclimatized to Conductor. Developer Labs, Logging and Metrics We have been continually improving logging and metrics, and revamped the documentation to reflect the latest state of Conductor.
As for FDE, there are multiple options available for PostgreSQL. parameters: type: pd-standard disk-encryption-kms-key: KMS_KEY_ID Get KMS_KEY_ID by following the instructions in this document. v1beta1 kind: StorageClass metadata: name: my-enc-sc provisioner: pd.csi.storage.gke.io apiVersion: storage.k8s.io/v1
Let’s take a look at how to get the benefits you need while spending less, based on the recommendations presented by Dani Guzmán Burgos, our Percona Monitoring and Management (PMM) Tech Lead, on this webinar (now available on demand) hosted in November last year. These color-coded states on panels are available in PMM 2.32.0
The following major features are available in this v2 REST API: One single endpoint to fetch information about any exported entity type. More entity types available for export. By having full control over the resulting payloads and information, you can minimize network traffic at your data centers when fetching Dynatrace data.
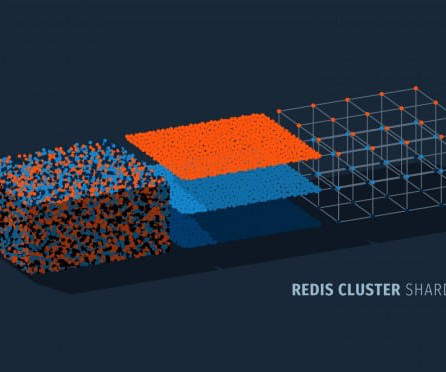
It enhances scalability and manages traffic surges, though it requires specific client support and limits multi-key operations to a single hash slot. It offers automatic data sharding, master-replica configurations for high availability, and a scalable and flexible architecture to maintain consistent performance.
OS: CentOS Linux 7 I’ve used mgenerate command to insert a sample document. s Time taken to import 120000000 document: 7412 seconds We can see from the above comparison that we can save almost 3GB of disk space without impacting the CPU or memory. Host config: 4vCPU, 14 GB RAM DB version: PSMDB 6.0.4
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content