This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dynatrace Simple Workflows make this process automatic and frictionlessthere is no additional cost for workflows. Why manual alerting falls short As your product and deployments scale horizontally and vertically, the sheer volume of data makes it impossible for teams to catch every error quickly using manual processes.
Dynatrace released Cloud Native Full Stack injection with a short list of temporary limitations — referenced in our documentation — which don’t apply to Classic Full Stack injection. The application consists of several microservices that are available as pod-backed services. Monitoring such an application is easy.
Sometimes, introducing new IT solutions is delayed or canceled because a single business unit can’t manage the operating costs alone, and per-department cost insights that could facilitate cost sharing aren’t available. Head over to Dynatrace Documentation to learn more about how to set up cost allocation in your environment.
A Dynatrace API token with the following permissions: Ingest OpenTelemetry traces ( openTelemetryTrace.ingest ) Ingest metrics ( metrics.ingest ) Ingest logs ( logs.ingest ) To set up the token, see Dynatrace API – Tokens and authentication in Dynatrace documentation. You can even walk through the same example above.
Access policies for Dynatrace Grail™ data lakehouse are still available as service-related policies; they allow you to control access to the monitoring data on a per-data-source level, for example, logs and metrics. For more information, go to our IAM policy boundaries documentation.
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Our script, available on GitHub , provides details. Are the corresponding services running on those hosts?
The business process observability challenge Increasingly dynamic business conditions demand business agility; reacting to a supply chain disruption and optimizing order fulfillment are simple but illustrative examples. Most business processes are not monitored. First and foremost, it’s a data problem.
As every developer knows, logs are crucial for uncovering insights and detecting fundamental flaws, such as process crashes or exceptions. Using Live Debugger, we immediately get insights into the running code, including variable values, process and thread information, and even a trace ID for the captured transaction.
Unrealized optimization potential of business processes due to monitoring gaps Imagine a retail company facing gaps in its business process monitoring due to disparate data sources. Due to separated systems that handle different parts of the process, the view of the process is fragmented.
By leveraging Dynatrace observability on Red Hat OpenShift running on Linux, you can accelerate modernization to hybrid cloud and increase operational efficiencies with greater visibility across the full stack from hardware through application processes. Dynatrace observability is available for Red Hat OpenShift on IBM Power.
However, due to the fact that they boil down selected indicators to single values and track error budget levels, they also offer a suitable way to monitor optimization processes while aligning on single values to meet overall goals. By recognizing the insights provided, you can optimize processes and improve overall efficiency.
Both categories share common requirements, such as high throughput and high availability. It allows users to choose between different counting modes, such as Best-Effort or Eventually Consistent , while considering the documented trade-offs of each option. Let’s take a closer look at the structure and functionality of the API.
Integration with existing systems and processes : Integration with existing IT infrastructure, observability solutions, and workflows often requires significant investment and customization. The certification results are now publicly available. We are updating product documentation to include underlying static assumptions.
We’re happy to announce the General Availability of cross-environment dashboarding capabilities (having released this functionality in an Early Adopter release with Dynatrace version 1.172 back in June 2019). Keep the token secret available for the second and final configuration step. Dynatrace news. What you get with this update.
From reacting to keywords that signal special offers, browsing the latest products, adding items to the shopping cart, checking out, and handling shipping, all the details of each user journey is available in logs. Advanced processing on your observability platform unlocks the full value of log data.
The standard dictionary subscript notation is also available. Consider these examples from the updated documentation: You can choose the right level of runtime configurability versus fixed deployments by mixing Parameters and Configs. Take a look at two interesting examples of this pattern in the documentation.
This means high-frequency streamed logs from Firehose can be captured in your Dynatrace environment, automatically processed, stored in Grail for the retention period of your choice, and included in the full observability automation suite of the Dynatrace® platform, apps, and Davis ® AI problem detection.
You can find additional deployment options in the OpenTelemetry demo documentation. All the needed components are available out of the box in the OpenTelemetry collector contrib distribution, which is included in the demo application. For details, see Dynatrace API – Tokens and authentication in theDynatrace documentation.
A simple and automated approach can help you stay on top of things and ensure your systems are available and secure. These include links to documentation, a list of similar technologies, customer stories, and further reading materials. Of course, seeing is believing.
Heres what stands out: Key Takeaways Better Performance: Faster write operations and improved vacuum processes help handle high-concurrency workloads more smoothly. Improved Vacuuming: A redesigned memory structure lowers resource use and speeds up the vacuum process. JSON_VALUE retrieves individual values from JSON documents.
But there are other related components and processes (for example, cloud provider infrastructure) that can cause problems in applications running on Kubernetes. And because Dynatrace can consume CloudWatch metrics, almost all your AWS usage information is available to you within Dynatrace. Dynatrace Kubernetes documentation .
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is Apache Kafka?
Well, the MySQL documentation provides a straightforward answer to this, quoting: InnoDB processes SELECT COUNT(*) statements by traversing the smallest available secondary index unless an index or optimizer hint directs the optimizer to use a different index. What index will be used when you count all rows in a table?
All innovations based on Grail are only available in Dynatrace SaaS environments. Grail-based innovations are, however, only available in Dynatrace SaaS environments. Tracking the upgrade process, which can take weeks, is daunting and requires automation to ensure nothing is missed. Are you ready to upgrade to SaaS?
Track changes via our change management process. The full list of secure development controls, along with many more details, are documented at Dynatrace secure development controls. The signatures are automatically verified during the update process on the customer infrastructure. Automatically run thousands of automated tests.
The adoption process takes time and consideration. What used to take a lot of valuable time, resources, and tools is now available in one central place. By using the available ownership information, teams can quickly and immediately begin to collaborate on optimizing these workloads. Want to try it for yourself?
This enables the Dynatrace extension to perform activities like processing telemetry data and sending data to the Dynatrace Cluster following the return of Lambda function responses. For details on monitoring such containers, see Deploy OneAgent to container-image packaged functions in Dynatrace Documentation.
Across the globe, privacy laws grant individuals data subject rights, such as the right to access and delete personal data processed about them. 2] — Nader Henein, VP Analyst, Gartner The Privacy Rights app is designed to streamline this process in Dynatrace. Check out the documentation for the Privacy Rights app.
In this hybrid world, IT and business processes often span across a blend of on-premises and SaaS systems, making standardization and automation necessary for efficiency. Enterprises seek solutions that enable these processes to interact across their entire system landscape without compromising security.
Amazon compute solutions are designed to streamline resource provisioning and container management with two services: AWS Lambda : Lambda provides serverless compute infrastructure that lets you run code in response to predetermined events or conditions and automatically manage all compute resources required for these processes.
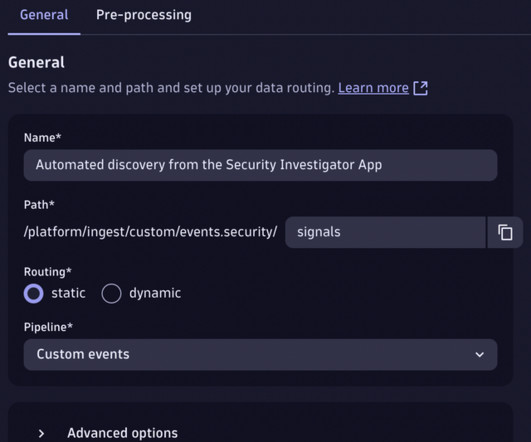
You can read more about workflow triggers in Workflow schedule trigger documentation. OpenPipeline allows you to create custom endpoints for data ingestion and process the events in the pipeline (for example, adding custom pipe-dependent fields to simplify data analysis in a later phase).
Today, development teams suffer from a lack of automation for time-consuming tasks, the absence of standardization due to an overabundance of tool options, and insufficiently mature DevSecOps processes. This process begins when the developer merges a code change and ends when it is running in a production environment.
This includes digging through each monitored data source and adding tags to the sensitive data points; this process is usually expensive, exhausting, error-prone, and unscalable. Read more about these options in Log Monitoring documentation. Open the available tabs to explore and easily tailor your data privacy settings.
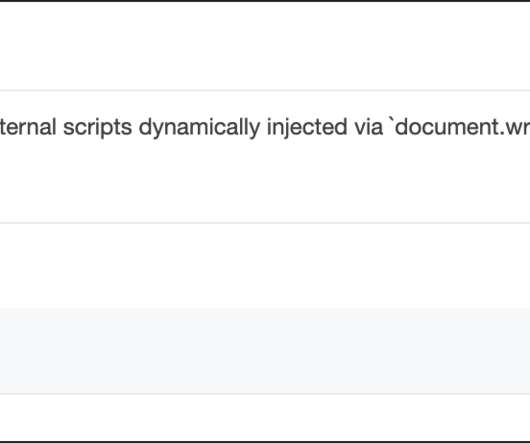
The Preload Scanner is a secondary, inert, download-only parser that’s responsible for running down the HTML and asynchronously requesting any available subresources it might find, chiefly anything contained in src or href attributes, including images, scripts, stylesheets, etc. src = ' file.js ' ; document. var script = document.
Here’s a simple rough sketch of RAG: Start with a collection of documents about a domain. Split each document into chunks. While the overall process may be more complicated in practice, this is the gist. One more embellishment is to use a graph neural network (GNN) trained on the documents. at Facebook—both from 2020.
Log Monitoring documentation. Starting with Dynatrace version 1.239, we have restructured and enhanced our Log Monitoring documentation to better focus on concepts and information that you, the user, look for and need. Legacy Log Monitoring v1 Documentation. General Availability (Build 1.239.178). Log Monitoring.
We anticipated the industry’s move to dynamic multicloud environments and DevOps processes. as part of a larger research document and should be evaluated in the context of the entire document. The Gartner document is available upon request from Dynatrace. Gartner Disclaimers.
Sample GraphQL Schema Once entities like the above are available in the graph, it’s very common for folks to want to query for a particular entity based on attributes of related entities, e.g. give me all movies that are currently in photography with Ryan Reynolds as an actor. Our solution to this is a reverse lookup?
A tight integration between Red Hat Ansible Automation Platform, Dynatrace Davis ® AI, and the Dynatrace observability and security platform enables closed-loop remediation to automate the process from: Detecting a problem. Remediation details are linked to the problem in Dynatrace and documented in ServiceNow.
Threat hunting expectations vs. reality In a perfect world, threat hunting and incident resolution would be a linear, straightforward process. Keeping threats documented is a challenge: Engineers typically open numerous tabs to maintain context, which is tedious and can create error. Clair determined what log data was available to her.
Dynatrace’s ability to ingest metrics from all 95 AWS services will be available within the next 60 days. Those in the left column are readily available now, with those in the right available soon. Available Now. You can refer to Dynatrace documentation for detailed information and requirements. Coming Soon.
It makes them available for a log analytics platform to gain automated, contextual, and actionable insights into the services and underlying platforms. More detailed information about the included metadata can be found in Dynatrace Documentation. You can filter logs based on their content, source, or process technology.
WebKit have recently announced their intent to implement the blocking=render attribute for and elements, bringing them in line with support already available in Blink and generally positive sentiment in Firefox. The resource is fetched and processed asynchronously while the browser is free to work on whatever other tasks there may be.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content