This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A Dynatrace API token with the following permissions: Ingest OpenTelemetry traces ( openTelemetryTrace.ingest ) Ingest metrics ( metrics.ingest ) Ingest logs ( logs.ingest ) To set up the token, see Dynatrace API – Tokens and authentication in Dynatrace documentation. You can even walk through the same example above.
From a cost perspective, internal customers waste valuable time sending tickets to operations teams asking for metrics, logs, and traces to be enabled. A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. This approach is costly and error prone.
Access policies for Dynatrace Grail™ data lakehouse are still available as service-related policies; they allow you to control access to the monitoring data on a per-data-source level, for example, logs and metrics. For more information, go to our IAM policy boundaries documentation.
To achieve the best visual outcome, we recommend experimenting with the available customization options. Go to our documentation to learn more about implementing honeycomb visualizations on your dashboards or notebooks. The functionality is automatically available in all time-series charts in the Dashboards and Notebook apps.
For quite some time already, Dynatrace has provided full observability into AWS services by ingesting CloudWatch metrics that are published by AWS services. Amazon CloudWatch gathers metric data from various services that run on AWS. We’re happy to announce that Dynatrace is now a launch partner for Amazon CloudWatch Metric Streams.
Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. Even if infrastructure metrics aren’t your thing, you’re welcome to join us on this creative journey simply swap out the suggested metrics for ones that interest you.
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Our script, available on GitHub , provides details. into NAM test definitions.
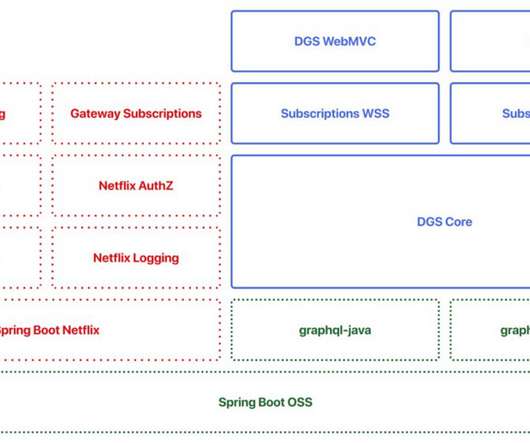
DataJunction: Unifying Experimentation and Analytics Yian Shang , AnhLe At Netflix, like in many organizations, creating and using metrics is often more complex than it should be. DJ acts as a central store where metric definitions can live and evolve. As an example, imagine an analyst wanting to create a Total Streaming Hours metric.
Your teams want to iterate rapidly but face multiple hurdles: Increased complexity: Microservices and container-based apps generate massive logs and metrics. You can select any trigger thats available for standard workflows, including schedules, problem triggers, customer event triggers, or on-demand triggers.
Dynatrace collects a huge number of metrics for each OneAgent-monitored host in your environment. Depending on the types of technologies you’re running on individual hosts, the average number of metrics is about 500 per computational node. Running metric queries on a subset of entities for live monitoring and system overviews.
Telemetry data, such as traces and metrics, allow you to analyze the end-to-end performance of your deployed applications. It automates tasks such as provisioning and scaling Dynatrace monitoring components, updating configurations, and ensuring the health and availability of your monitoring infrastructure.
A Kubernetes SLO that continuously evaluates CPU, memory usage, and capacity and compares these available resources to the requested and utilized memory of Kubernetes workloads makes potential resource waste visible, revealing opportunities for countermeasures.
Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. Davis topology-aware anomaly detection and alerting for your Micrometer metrics. Topology-related custom metrics for seamless reports and alerts. Micrometer uses a registry to export metrics to monitoring systems.
The Carbon Impact app directly supports our customers sustainability efforts through granular real-time emissions reporting and analytics, translating host utilization metrics into their CO2 equivalent (CO2e). The certification results are now publicly available. Today, Carbon Impact has a new name: Cost & Carbon Optimization.
Dynatrace has recently extended its Kubernetes operator by adding a new feature, the Prometheus OpenMetrics Ingest , which enables you to import Prometheus metrics in Dynatrace and build SLO and anomaly detection dashboards with Prometheus data. Here we’ll explore how to collect Prometheus metrics and what you can achieve with them.
With the advent and ingestion of thousands of custom metrics into Dynatrace, we’ve once again pushed the boundaries of automatic, AI-based root cause analysis with the introduction of auto-adaptive baselines as a foundational concept for Dynatrace topology-driven timeseries measurements. In many cases, metric behavior changes over time.
Now, Dynatrace has the ability to turn numerical values from logs into metrics, which unlocks AI-powered answers, context, and automation for your apps and infrastructure, at scale. The parameter Billed Duration is only available in logs , so it makes sense to extract it from your logs so that you can keep an eye on your cloud costs.
We’re happy to announce the General Availability of cross-environment dashboarding capabilities (having released this functionality in an Early Adopter release with Dynatrace version 1.172 back in June 2019). Keep the token secret available for the second and final configuration step. Dynatrace news. What you get with this update.
Metrics matter. But without complex analytics to make sense of them in context, metrics are often too raw to be useful on their own. To achieve relevant insights, raw metrics typically need to be processed through filtering, aggregation, or arithmetic operations. Examples of metric calculations. Dynatrace news.
Dynatrace provides tooling and documentation to help you migrate your Extensions 1.0 address these limitations and brings new monitoring and analytical capabilities that weren’t available to Extensions 1.0: Comprehensive metrics support Extensions 2.0 available, and more are in the pipeline. We’re here to help.
The standard dictionary subscript notation is also available. Consider these examples from the updated documentation: You can choose the right level of runtime configurability versus fixed deployments by mixing Parameters and Configs. Take a look at two interesting examples of this pattern in the documentation.
You can find additional deployment options in the OpenTelemetry demo documentation. The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data. metrics from span data. Select + then select Metrics from the drop-down.
After being available in an Early Adopter Release, we’re happy to announce that AWS supporting services are now Generally Available (GA). Supporting services include every service that isn’t available with out-of-the-box Dynatrace monitoring. Get up to 300 new AWS metrics out of the box. Everything is customizable.
To make this possible, the application code should be instrumented with telemetry data for deep insights, including: Metrics to find out how the behavior of a system has changed over time. And because Dynatrace can consume CloudWatch metrics, almost all your AWS usage information is available to you within Dynatrace.
Log data—the most verbose form of observability data, complementing other standardized signals like metrics and traces—is especially critical. With this out-of-the-box support for scalable data ingest, log data is immediately available to your teams for troubleshooting and observability, investigating security issues, or auditing.
A simple and automated approach can help you stay on top of things and ensure your systems are available and secure. Search the Hub to find Extensions for effortlessly importing technology-specific metrics. These include links to documentation, a list of similar technologies, customer stories, and further reading materials.
After being available in an Early Adopter Release, we’re happy to announce that AWS supporting services are now Generally Available (GA). Supporting services include every service that isn’t available with out-of-the-box Dynatrace monitoring. Get up to 300 new AWS metrics out of the box. Everything is customizable.
It provides unified observability by automatically correlating logs and placing them in the context of traces and metrics. Since you can ingest Journald logs using Dynatrace OneAgent, this feature is available to customers of both the latest Dynatrace SaaS and Dynatrace Managed.
To set up the token, see Dynatrace APITokens and authentication in Dynatrace documentation. If you dont have one, you can use a trial account. A Dynatrace API token with the following permissions. It also showed the power of DQL to pinpoint the root cause of an unexpected problem.
Spring also introduced Micrometer, a vendor-agnostic metric API with rich instrumentation options. Soon after, Dynatrace built a registry for exporting Micrometer metrics. Our data APIs, which ingest millions of metrics, traces, and logs per second, are reconciled using Micrometer-based metrics.
The F5 BIG-IP Local Traffic Manager (LTM) is an application delivery controller (ADC) that ensures the availability, security, and optimal performance of network traffic flows. Business-critical applications typically rely on F5 for availability and success. You can customize the metrics shown to suit your individual needs.
Optimizing cloud services can prove quite challenging because logs, metrics, and traces are not always put together in context, and you don’t have access to the underlying hosts. Even so, logs are normally available in cloud consoles, though effective analysis can’t be performed using logs alone. One place to rule them all.
The training times and other quality metrics, such as the RMSE (Root Mean Squared Error), SMAPE (Scaled Mean Absolute Percentage Error), and coverage probability, are monitored using Dynatrace. Our data scientists utilize metrics and events to store these quality metrics. For full details, see Dynatrace Documentation.
Log Monitoring documentation. Starting with Dynatrace version 1.239, we have restructured and enhanced our Log Monitoring documentation to better focus on concepts and information that you, the user, look for and need. Legacy Log Monitoring v1 Documentation. The display name is now required in metric metadata. Dashboards.
Resource consumption: Observing computational resource availability and saturation, whether deployed in cloud-native environments like Kubernetes or CPU-enabled servers. OpenTelemetry has become a standard for collecting traces, metrics, and logs. Maintained under the Apache 2.0
We can establish these SLOs by setting availability and performance targets, such as a target uptime percentage or a target response time. We can build the availability SLO using the Dynatrace SLO wizard. We already know how to build the availability SLO. You can use the status metric as a reference for the global SLO.
Dynatrace’s ability to ingest metrics from all 95 AWS services will be available within the next 60 days. Those in the left column are readily available now, with those in the right available soon. Available Now. AWS SDK Metrics for Enterprise Support. Achieve full observability of all AWS services.
With the AI-powered Dynatrace platform now generally available on Azure, Azure Native Dynatrace Service customers can now leverage the full AI power of the Dynatrace platform directly from Azure. Clouds provides resource properties, metrics, problems, and events in a single view, as shown below.
Without seeing syslog data in the context of your infrastructure, metrics, and transaction traces, you’re slowed down by manual work with siloed data. What’s next See these related resources for complete details about Dynatrace syslog support: Syslog ingestion is available with Dynatrace Environment ActiveGate version 1.295.
Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. Davis topology-aware anomaly detection and alerting for your Micrometer metrics. Topology-related custom metrics for seamless reports and alerts. Micrometer uses a registry to export metrics to monitoring systems.
Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. Davis topology-aware anomaly detection and alerting for your Micrometer metrics. Topology-related custom metrics for seamless reports and alerts. Micrometer uses a registry to export metrics to monitoring systems.
Define monitoring goals and user experience metrics Next, define what aspects of a digital experience you want to monitor and improve — such as website performance, application responsiveness, or user engagement — and prioritize what to measure for each application. The time it takes to begin the page’s load event. Load event end.
This framework was initially intended to be internal only, focusing on integration with the Netflix ecosystem for tracing, logging, metrics, etc. Comprehensive documentation is available on the website but let’s walk through an example to show you how easy it is to use this framework. Let’s start with a simple schema.
In addition to APM , th is platform offers our customers infrastructure monitoring spanning logs and metrics, digital business analytics, digital experience monitoring, and AIOps capabilities. as part of a larger research document and should be evaluated in the context of the entire document.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content