This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To achieve the best visual outcome, we recommend experimenting with the available customization options. Go to our documentation to learn more about implementing honeycomb visualizations on your dashboards or notebooks. The functionality is automatically available in all time-series charts in the Dashboards and Notebook apps.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
Its design prioritizes high availability and efficient data transfer with minimal overhead, making it a practical choice for handling real-time data pipelines and distributed event processing. It follows a push-based approach, ensuring messages are distributed to consumers as soon as they become available.
We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. The latency table shows that 99th percentile latency for Yugabyte is quite high compared to others (lower is better). Again Yugabyte latency is quite high. Conclusion.
What is the availability, configurability, and efficacy of each? ?️ Plotted on the same horizontal axis of 1.6s, the waterfalls speak for themselves: 201ms of cumulative latency; 109ms of cumulative download. 4,362ms of cumulative latency; 240ms of cumulative download. And do any of our previous decisions dictate our options?
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. To learn more, see our documentation.
A typical design pattern is the use of a semantic search over a domain-specific knowledge base, like internal documentation, to provide the required context in the prompt. With these latency, reliability, and cost measurements in place, your operations team can now define their own OpenAI dashboards and SLOs.
These signals ( latency, traffic, errors, and saturation ) provide a solid means of proactively monitoring operative systems via SLOs and tracking business success. SLOs, as a measure of service quality, can track the related availability, reliability, and performance. This is what Dynatrace captures as response time.
Resource consumption: Observing computational resource availability and saturation, whether deployed in cloud-native environments like Kubernetes or CPU-enabled servers. Data quality and drift: Monitoring the quality and characteristics of training and runtime data to detect significant changes that might impact model accuracy.
Whether tracking internal, workload-centric indicators such as errors, duration, or saturation or focusing on the golden signals and other user-centric views such as availability, latency, traffic, or engagement, SLOs-as-code enables coherent and consistent monitoring throughout the environment at scale.
It’s a cross-platform document-oriented database that uses JSON-like documents with schema, and is leveraged broadly across startup apps up to enterprise-level businesses developing modern apps. MongoDB is the #3 open source database and the #1 NoSQL database in the world. DigitalOcean Droplets. MongoDB Replication Strategies.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
But we cannot search or present low latency retrievals from files Etc. Marken Architecture Our goal was to help teams at Netflix to create data pipelines without thinking about how that data is available to the readers or the client teams. This API finds all Elasticsearch documents with ID1 and marks isAnnotationOperationActive=FALSE.
Model observability provides visibility into resource consumption and operation costs, aiding in optimization and ensuring the most efficient use of available resources. To leverage these integrations and embark on a journey toward optimized AI performance, explore our documentation for seamless onboarding.
The Clouds app provides a view of all available cloud-native services. Logs in context, along with other details, are instantly available after selecting a resource. The reasons are easy to find, looking at the latest improvements that went live along with the general availability of the Logs app.
As I have talked about before, one of the reasons why we built Amazon DynamoDB was that Amazon was pushing the limits of what was a leading commercial database at the time and we were unable to sustain the availability, scalability, and performance needs that our growing Amazon.com business demanded. The opposite is true.
After being available in an Early Adopter Release, we’re happy to announce that AWS supporting services are now Generally Available (GA). Supporting services include every service that isn’t available with out-of-the-box Dynatrace monitoring. Amazon ElastiCache (see AWS documentation for Memcached and Redis ). Amazon EMR.
By collecting and analyzing key performance metrics of the service over time, we can assess the impact of the new changes and determine if they meet the availability, latency, and performance requirements. One can perform this comparison live on the request path or offline based on the latency requirements of the particular use case.
Once the instance was available, the engineer would use a remote administration tool like RDP to login to the instance to install software and customize settings. The canary stage will determine a score based on metrics such as CPU, threads, latency, and GC pauses. Services are more reliable, testable, and documented.
ScyllaDB offers significantly lower latency which allows you to process a high volume of data with minimal delay. percentile latency is up to 11X better than Cassandra on AWS EC2 bare metal. Their managed service, Scylla Cloud, is currently only available on AWS, and you must use the ScyllaDB Enterprise version to leverage their DBaaS.
There was no appetite from them to do so, so I decided to make it all available for free anyway—a faster web benefits everyone. Although this response has a 0B filesize, we will always take the latency hit on every single page view (and this response is basically 100% latency). Next up, we get sent to fonts.[client].com
For each route we migrated, we wanted to make sure we were not introducing any regressions: either in the form of missing (or worse, wrong) data, or by increasing the latency of each endpoint. You can find a lot more details about how this works in the Spinnaker canaries documentation. This meant that data that was static (e.g.
After being available in an Early Adopter Release, we’re happy to announce that AWS supporting services are now Generally Available (GA). Supporting services include every service that isn’t available with out-of-the-box Dynatrace monitoring. Amazon ElastiCache (see AWS documentation for Memcached and Redis ). Amazon EMR.
Listening to Kafka events adds little latency, our fan out operations are really quick since we store foreign keys to identify the edges, and looking up data in an inverted index is fast as well. Once all documents have been indexed with no errors, we swap the alias from the currently active index to the newly built index.
It is very gratifying to see all of our learning and experience become available to our customers in the form of an easy-to-use managed service. Amazon DynamoDB offers low, predictable latencies at any scale. It provides multi-data center replication, high availability, and offers rock-solid durability. Consistency. SimpleDBâ??s
A cluster is just a pool of compute resources available to a customer’s applications. The agent is written in Go, has a minimal footprint, and is available on GitHub under an Apache license. This architecture affords Amazon ECS high availability, low latency, and high throughput because the data store is never pessimistically locked.
For example, when running tests, the state of the device will change from “available for testing” to “in test.” Build a Spring @Configuration class that autowires the KafkaProperties bean injected by the Netflix Spring runtime and, using the Kafka settings available from that bean, construct an Alpakka-Kafka ConsumerSettings bean.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. To learn more, see our documentation.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. To learn more, see our documentation.
The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. However, it is limited by the available free memory amount, and all data is lost when the server stops. It features document-level locking, prefix compression, and collection-level configuration options.
For example, the number of threads of your process is already available in Dynatrace in most cases, so there is no need to spend the extra effort. With insights from Dynatrace into network latency and utilization of your cloud resources, you can design your scaling mechanisms and save on costly CPU hours. Extending Dynatrace is easy!
This enables us to use our scale to increase throughput and reduce latencies. Here, based on the video length, the throughput and latency requirements, available scale etc., The quality results are now available to the caller via the getQuality endpoint. The workflow is initiated. Assembly for two of the metrics (e.g.
OS: CentOS Linux 7 I’ve used mgenerate command to insert a sample document. s Time taken to import 120000000 document: 7412 seconds We can see from the above comparison that we can save almost 3GB of disk space without impacting the CPU or memory. Host config: 4vCPU, 14 GB RAM DB version: PSMDB 6.0.4
Were experiencing high latency in responses. Chunking Breaking long texts into smaller parts Splitting documents helps search them better. Distillation Making a smaller, faster model from a big one It lets you use cheaper, faster models with less delay (latency). Consider utilizing transfer learning techniques.
In short, each cluster is, in reality, a single database with high availability and other functionalities built in. For documentation, the sysbench commands are: Test1 sysbench./src/lua/windmills/oltp_read.lua Let us take a look also the latency: Here the situation starts to be a little bit more complicated. and ProxySQL 6.6k.
Compared to the most recent master version of libaom (AV1 reference software), SVT-AV1 is similar in compression efficiency and at the same time achieves significantly lower encoding latency on multi-core platforms when using its inherent parallelization capabilities.
In order to be supported, a database is required to fulfill a set of features that are commonly available in systems like MySQL, PostgreSQL, MariaDB, and others. Designed with High Availability in mind. Providing high availability for real-time events. Some of DBLog’s features are: Processes captured log events in-order.
In this blog, we’ll show you how to connect to a MongoDB server configured with self-signed certificates for SSL using both the Ruby MongoDB driver and the popular Object-Document-Mapper (ODM) mongoid. The connection options available for the driver are documented here , and the options we will need are: :ssl. ssl_verify.
Lots can go wrong: a network request fails, a third-party library breaks, a JavaScript feature is unsupported (assuming JavaScript is even available), a CDN goes down, a user behaves unexpectedly (they double-click a submit button), the list goes on. Both examples check something is available before using it. More after jump!
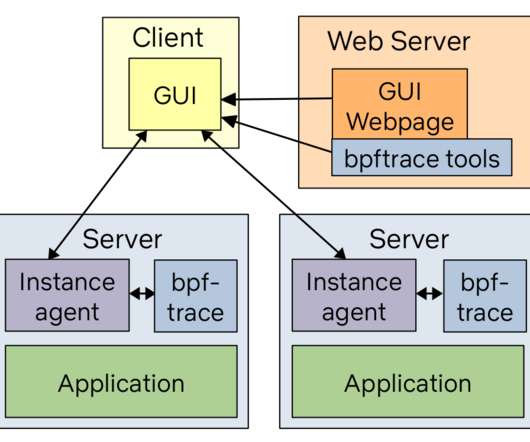
biolatency Disk I/O latency histogram heat map. runqlat CPU scheduler latency heat map. There is already documentation as man pages and example files in the bcc and bpftrace repositories that you can link to, to help your customers understand the tool output. execsnoop New processes (via exec(2)) table. at the time.
In order to be supported, a database is required to fulfill a set of features that are commonly available in systems like MySQL, PostgreSQL, MariaDB, and others. Designed with High Availability in mind. Providing high availability for real-time events. High Availability DBLog uses active-passive architecture. Figure 3?—?DBLog
This data is available both in the Dynatrace UI as well as through the Dynatrace Smartscape and Timeseries API : Dynatrace Smartscape answers all dependency questions in a cloud migration project. All available in Dynatrace in the UI or through the API! Also accessible through the Smartscape API. These examples include e.g:
Since your dataset is 100 GB and you have 500 GB of RAM, you can allocate a significant portion of the available memory to the InnoDB buffer pool. A commonly recommended value for the buffer pool size is between 50% to 75% of the available memory. So the actual answer is highly dependent on the workload (i.e.
In such cases, rollback becomes necessary to reconcile divergent data among all members of replicas ensuring consistent information throughout multi-document transactions without any inconsistencies arising due to differences between replicated sets. Consequences of Rollbacks After a rollback occurs, the consequences can be quite severe.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content