This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A good Kubernetes SLO strategy helps teams manage and make containerized workloads more efficient. Efficient coordination of resource usage, requests, and allocation is critical. As every container has defined requests for CPU and memory, these indicators are well-suited for efficiency monitoring.
Sometimes, introducing new IT solutions is delayed or canceled because a single business unit can’t manage the operating costs alone, and per-department cost insights that could facilitate cost sharing aren’t available. Costs and their origin are transparent, and teams are fully accountable for the efficient usage of cloud resources.
Fast and efficient log analysis is critical in todays data-driven IT environments. For enterprises managing complex systems and vast datasets using traditional log management tools, finding specific log entries quickly and efficiently can feel like searching for a needle in a haystack. What are Dynatrace Segments?
Dynatrace released Cloud Native Full Stack injection with a short list of temporary limitations — referenced in our documentation — which don’t apply to Classic Full Stack injection. The application consists of several microservices that are available as pod-backed services. Monitoring such an application is easy.
A Dynatrace API token with the following permissions: Ingest OpenTelemetry traces ( openTelemetryTrace.ingest ) Ingest metrics ( metrics.ingest ) Ingest logs ( logs.ingest ) To set up the token, see Dynatrace API – Tokens and authentication in Dynatrace documentation. You can even walk through the same example above.
In this blog post, we will see how Dynatrace harnesses the power of observability and analytics to tailor a new experience to easily extend to the left, allowing developers to solve issues faster, build more efficient software, and ultimately improve developer experience!
By leveraging Dynatrace observability on Red Hat OpenShift running on Linux, you can accelerate modernization to hybrid cloud and increase operational efficiencies with greater visibility across the full stack from hardware through application processes. Dynatrace observability is available for Red Hat OpenShift on IBM Power.
We’re happy to announce the General Availability of cross-environment dashboarding capabilities (having released this functionality in an Early Adopter release with Dynatrace version 1.172 back in June 2019). This gives you a boost in efficiency when managing multiple environments. Dynatrace news. What you get with this update.
Both categories share common requirements, such as high throughput and high availability. It allows users to choose between different counting modes, such as Best-Effort or Eventually Consistent , while considering the documented trade-offs of each option. Let’s take a closer look at the structure and functionality of the API.
Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. As you went through these steps, you likely noticed some of the chart options available. For more information, you can always check our documentation.
The certification results are now publicly available. The calculations and methodology used are in line with the best available scientific approach, as well as with relevant reporting requirements. We are updating product documentation to include underlying static assumptions.
Incremental Backups: Speeds up recovery and makes data management more efficient for active databases. Performance Optimizations PostgreSQL 17 significantly improves performance, query handling, and database management, making it more efficient for high-demand systems. JSON_VALUE retrieves individual values from JSON documents.
Thanks to its structured and binary format, Journald is quick and efficient. Since you can ingest Journald logs using Dynatrace OneAgent, this feature is available to customers of both the latest Dynatrace SaaS and Dynatrace Managed. It offers structured logging, fast indexing for search, access controls, and signed messages.
Kafka scales efficiently for large data workloads, while RabbitMQ provides strong message durability and precise control over message delivery. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. This allows Kafka clusters to handle high-throughput workloads efficiently.
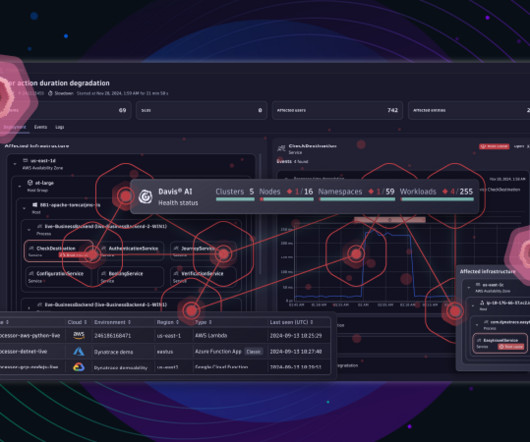
The complexity and numerous moving parts of Kubernetes multicloud clusters mean that when monitoring the health of these clusters—which is critical for ensuring reliable and efficient operation of the application—platform engineers often find themselves without an easy and efficient solution. Want to try it for yourself?
The following figure depicts imaginary “evolution” of the major NoSQL system families, namely, Key-Value stores, BigTable-style databases, Document databases, Full Text Search Engines, and Graph databases: NoSQL Data Models. Document databases advance the BigTable model offering two significant improvements.
Scale with confidence: Leverage AI for instant insights and preventive operations Using Dynatrace, Operations, SRE, and DevOps teams can scale efficiently while maintaining software quality and ensuring security and reliability.
EdgeConnect facilitates seamless interaction, ensuring data security and operational efficiency. In this hybrid world, IT and business processes often span across a blend of on-premises and SaaS systems, making standardization and automation necessary for efficiency.
Their job is to find out the root cause of any SLO violations, ensure visibility into the application landscape to fix problems efficiently and minimize production costs by reducing errors. Follow the instructions available in Dynatrace documentation to allow proper access and configure Firehose settings.
Rising consumer expectations for transparency and control over their data, combined with increasing data volumes, contribute to the importance of swift and efficient management of privacy rights requests. How can this services administrator meet this request in a quick, compliant, and efficient way?
Stay ahead of the curve with the OS Services extension for monitored hosts The new Dynatrace OS Services monitoring capability for Windows and Linux hosts (Systemd is required) ensures that your systems run efficiently and potential problems are addressed as soon as they arise. For full details, see Dynatrace Documentation.
The combination of our broad platform with powerful, explainable AI-assistance and automation helps our customers reduce wasted motions and accelerate better business outcomes – whether that’s speed and quality of innovation for IT, automation, and efficiency for DevOps, or optimization and consistency of user experiences.
Whether it’s the speed and quality of innovation for IT, automation and efficiency for DevOps, or enhancement and consistency of user experiences, Dynatrace makes it easy. as part of a larger research document and should be evaluated in the context of the entire document. Gartner Disclaimers.
In this article, we’ll explore these challenges in detail and introduce Keptn, an open source project that addresses these issues, enhancing Kubernetes observability for smoother and more efficient deployments. Infrastructure health The underlying infrastructure’s health directly impacts application availability and performance.
Incorporating synthetic monitoring and observability-driven automation can greatly streamline the workflow for DevOps teams, allowing for continuous improvements in system reliability and efficiency. For full details regarding Synthetic Monitoring for Workflows, go to Dynatrace Documentation.
Several pain points have made it difficult for organizations to manage their data efficiently and create actual value. Limited data availability constrains value creation. This approach is cumbersome and challenging to operate efficiently at scale. Even in cases where all data is available, new challenges can arise.
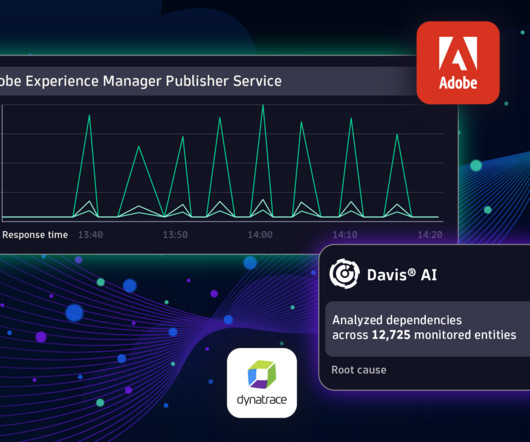
As a result, it is difficult to ensure application efficiency and ensure accurate delivery across touchpoints. Furthermore, by integrating with Adobe Experience Manager, you get quick visibility, ensuring application efficiency across all channels and the ability to scale in support of even the largest Adobe Experience Manager instances.
The F5 BIG-IP Local Traffic Manager (LTM) is an application delivery controller (ADC) that ensures the availability, security, and optimal performance of network traffic flows. Business-critical applications typically rely on F5 for availability and success. A list of all collected metrics can be found in Dynatrace Documentation.
Keeping ownership teams and their properties up to date is essential, as is having the right contact information available when needed. How to efficiently introduce team ownerships Dynatrace provides different ways of associating team ownership with entities and adding desired team metadata, such as contact details, to your environments.
This will allow for more efficient troubleshooting and seamless handoffs to subject matter experts. Behind the scenes, the Dynatrace experts managing your issues have a single and intelligent workbench to efficiently access the tools and information they need to triage your tickets more effectively and resolve them faster.
Communicating security insights efficiently across teams in your organization isn’t easy Security management is a complex and challenging task; effectively communicating security insights is even more so. Is the right data available in these critical moments? Sample dashboard Next, you want to prepare an efficient plan for remediation.
Today, the composable nature of code enables skilled IT teams to create and customize automated solutions capable of improving efficiency. Minimize overall documentation. Over-documentation reintroduces this issue and can lead to environments and configuration data being out of sync. Address monitoring at scale.
In the past five years, delivering innovation more efficiently has remained at the forefront of customer demand. Keeping threats documented is a challenge: Engineers typically open numerous tabs to maintain context, which is tedious and can create error. Clair determined what log data was available to her. Finally, St.
Using a FaaS model makes it possible to scale up individual application functions as needed rather than increase total resource allocation for your entire application, which helps reduce total resource costs and improve overall app efficiency. AWS serverless offerings. AWS offers four serverless offerings for storage.
Kubernetes is an open-source orchestration engine for containerized applications that help to automate processes such as scaling, deployments, and management with greater efficiency. . Create web applications that are highly available across multiple availability zones and scales to meet your demanding consumption footprints .
However, scaling up software development requires more tools along the software product lifecycle, which must be configured promptly and efficiently. Efficient environment configuration at scale One of software engineers’ most significant challenges is managing the numerous tools and technologies required for the software product lifecycle.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
As batch jobs run without user interactions, failure or delays in processing them can result in disruptions to critical operations, missed deadlines, and an accumulation of unprocessed tasks, significantly impacting overall system efficiency and business outcomes. Apply basic filtering to ensure the availability of batch job-related logs.
We optimized our Micrometer Registry to export data in memory-efficient chunks. Auto-enrichment is also available in cases where OneAgent is unavailable or unnecessary. The fastest way is via QuickStart, which is explained in our documentation. Fortunately, back in our Slack message, we have relevant links available.
This way, disruptions are minimized, MTTR is significantly decreased, and DevSecOps and SREs collaborate efficiently to boost productivity. Remediation details are linked to the problem in Dynatrace and documented in ServiceNow. Executing corrective actions. Keeping relevant stakeholders in the loop.
General Availability (Build 1.241.153). General Availability (Build 1.241.153). Enhanced API documentation for the latest OneAngent endpoint of the Deployment API. (APM-365055). This change requires a migration which will update the last modified date for all dashboards. Dynatrace API. Resolved issues. Resolved issues.
Here’s a simple rough sketch of RAG: Start with a collection of documents about a domain. Split each document into chunks. This latter approach with node embeddings can be more robust and potentially more efficient. One more embellishment is to use a graph neural network (GNN) trained on the documents.
With the AI-powered Dynatrace platform now generally available on Azure, Azure Native Dynatrace Service customers can now leverage the full AI power of the Dynatrace platform directly from Azure. An overview of how to upgrade to Dynatrace is available in our guide, Upgrade to Dynatrace SaaS.
Reason : High memory consumption of XPath queries when parsing application documents. Solution : Use optimized methods to access / query for specific data, e.g.: getNodeByType resulted in 98% reduction of CPU usage, better performance, returned high availability and reduced operational costs.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content