This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Editor's Note: The following is an article written for and published in DZone's 2024 Trend Report, The Modern DevOps Lifecycle: Shifting CI/CD and Application Architectures. By integrating observability tools in CI/CD pipelines, organizations can increase deployment frequency, minimize risks, and build highly available systems.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
Cloud-native environments bring speed and agility to software development and operations (DevOps) practices. So which is it: SRE vs DevOps, or SRE and DevOps? DevOps is focused on optimizing software development and delivery, and SRE is focused on operations processes. DevOps as a philosophy. SRE vs DevOps?
As enterprises expand their software development practices and scale their DevOps pipelines, effective management of continuous integration (CI) and continuous deployment (CD) processes becomes increasingly important. GitHub, as one of the most widely used source control platforms, plays a central role in modern development workflows.
As organizations accelerate innovation to keep pace with digital transformation, DevOps observability is becoming a critical key to success for DevOps and DevSecOps teams. DevOps and DevSecOps practices help organizations release software faster and more frequently, paving the way for digital transformation.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? A DevOps platform engineer is a more recent term.
As organizations mature on their digital transformation journey, they begin to realize that automation – specifically, DevOps automation – is critical for rapid software delivery and reliable applications. In turn, manual approaches to identifying code issues and troubleshooting are not scalable. This statistic is despite the $9.1
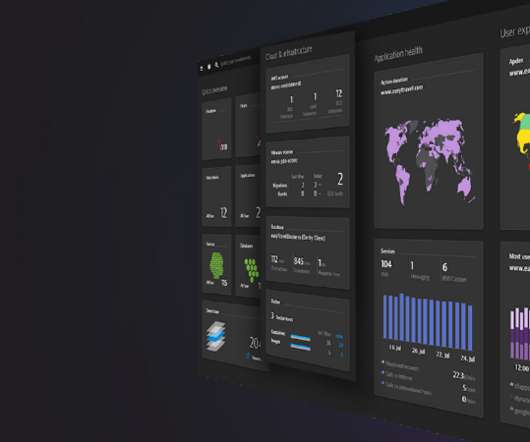
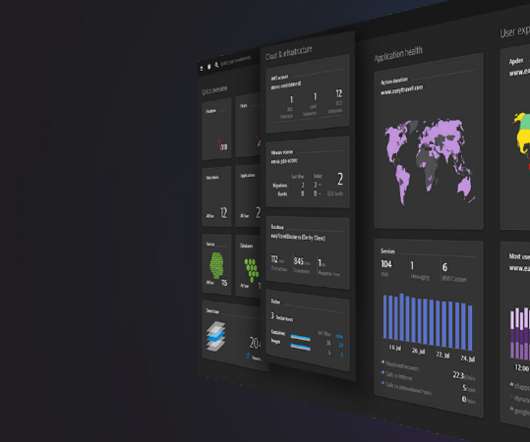
The end goal, of course, is to optimize the availability of organizations’ software. Dynatrace is widely recognized for its AI capabilities’ ability to predict and prevent issues, and automatically identify root causes, maximizing availability. Note that the work doesn’t get reduced.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. While the SLO management web UI and API are already available, the dashboard tile will be released within the next weeks.
The old saying in the software development community, “You build it, you run it,” no longer works as a scalable approach in the modern cloud-native world. Platform engineering best practices for delivering a highly available, secure, and resilient Internal Development Platform: Centralize and standardize.
With growing multicloud complexity and the need for organization-wide scalability, self-service and automation capabilities have become increasingly essential for developer productivity. Platform engineers design and implement these platforms, as well as ensure their security, scalability, and reliability.
The time and effort saved with testing and deployment are a game-changer for DevOps. This opens the door to auto-scalable applications, which effortlessly matches the demands of rapidly growing and varying user traffic. In production, containers are easy to replicate. What is Docker?
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
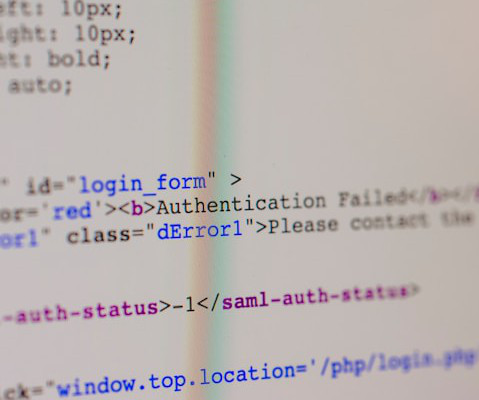
Without the ability to see the logs that are relevant to your service, infrastructure, or cloud function—at exactly the right time and in exactly the right format—your cloud or DevOps engineers lose the ability to find the root causes of the issues they troubleshoot. Now, you can set up your Firehose stream.
Dynatrace scored highest across 4 of 5 use cases, DevOps/AppDev, SRE/CloudOps, IT Operations, and Digital Experience Monitoring, and second highest in the Application Owner/Line of Business use case. We anticipated the industry’s move to dynamic multicloud environments and DevOps processes. Gartner Disclaimers.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
Messaging systems can significantly improve the reliability, performance, and scalability of the communication processes between applications and services. To know which services are impacted, DevOps teams need to know what’s happening with their messaging systems. – DevOps Engineer, large healthcare company.
Certified for Red Hat OpenShift, Dynatrace is now available on the Red Hat Marketplace for customers to try, buy, and deploy, to manage their enterprise applications and infrastructure across their dynamic multi-cloud environments. Accelerating DevOps processes and innovations via intelligent observability . Dynatrace news.
While there isn’t an authoritative definition for the term, it shares its ethos with its predecessor, the DevOps movement in software engineering: by adopting well-defined processes, modern tooling, and automated workflows, we can streamline the process of moving from development to robust production deployments.
Our Fulfillment Centers have migrated 92% of DBs from Oracle to Aurora with better avail, less bugs and patches, less troubleshooting, less hw cost. More: @swardley : I occasionally hear companies announcing they are kicking off a "DevOps" program and I can't but feel sympathy for them. it's a bit sad really. .
Behind the scenes working to meet this demand are DevOps teams, spinning up multicloud IT environments to accelerate digital transformation so their organizations can sustain growth at this new pace. Although these environments use fewer resources, they enable DevOps teams to deliver greater capabilities on a wider scale.
In short, log management is how DevOps professionals and other concerned parties interact with and manage the entire log lifecycle. Two major benefits of properly managed logs are their availability and searchability. Optimally stored logs enable DevOps, SecOps, and other IT teams to access them easily.
Redis Cluster is the native sharding implementation available within Redis, an open-source in-memory data structure project, that allows you to automatically shard across multiple Redis nodes without having to rely on external tools and utilities. Some of the advanced benefits of Redis Clusters include: High Availability.
Now, customers can use streamed responses to build more responsive applications by sending partial responses to clients as the response becomes available. Streaming raises the default 6 MB hard limit to a 20 MB soft limit, adding greater scalability and flexibility to their applications. What is a Lambda serverless function?
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
Cloud environments—including multicloud, hybrid, and cloud-native ecosystems—offer unmatched agility, scalability, and cost-effectiveness, though they also present new challenges and complexities that are impossible to manage manually. Example workflow for event-driven vulnerability reporting and escalation. What’s next?
We’re excited to announce our verified HashiCorp Terraform integration is now available for Dynatrace customers. When it comes to DevOps best practices, practitioners need ways to automate processes and make their day-to-day tasks more efficient. Dynatrace news. Terraform codifies cloud APIs into declarative configuration files.
The Dynatrace Software Intelligence Platform accelerates cloud operations, helping users achieve service-level objectives (SLOs) with automated intelligence and unmatched scalability. Automatic observability and root-cause analysis for DevOps, cloud, and apps teams. Built for enterprise scalability.
Part 1 of this series starts will cover the key ingredients needed for successful DevOps use to deliver better software faster, followed by a short overview of GitHub Actions and example use cases related to deployment and release monitoring. Key ingredients required to deliver better software faster. GitHub and GitHub Actions.
At the same time, metrics on a dashboard are showing resource exhaustion issues, such as lack of available memory. DevOps practitioners struggle to maintain highly available and scalable applications. For example, log messages might indicate a large percentage of errors in a particular API function.
In this three-part blog series, we introduced a High Availability (HA) Framework for MySQL hosting in Part I, and discussed the details of MySQL semisynchronous replication in Part II. Now in Part III, we review how the framework handles some of the important MySQL failure scenarios and recovers to ensure high availability.
As a result, IT operations, DevOps , and SRE teams are all looking for greater observability into these increasingly diverse and complex computing environments. Making observability actionable and scalable for IT teams. Here are some ways you can make observability actionable and scalable. But what is observability?
From load testing to DevOps. It is great that the book is not limited by the core JMeter functionality and discusses available components and integrations when appropriate. And while we are not fully there yet, the Integration of JMeter in the DevOps tool chain chapter directly dives into what can be done right now.
In recent years, function-as-a-service (FaaS) platforms such as Google Cloud Functions (GCF) have gained popularity as an easy way to run code in a highly available, fault-tolerant serverless environment. Although GCF adds needed flexibility to serverless application development, it can also pose observability challenges for DevOps teams.
Unlike traditional service s engagements that focus on moment-in-time projects, the Dynatrace Platform Extensions team worked with us from day one to develop a scalable, long-term strategy for integrating the Dynatrace Platform into our technology ecosystem. Build a foundation that scales. Faster time to resolution. Faster time to value.
It also enables DevOps teams to connect to any number of AWS services or run their own functions. Lambda’s toolbox of automated processes helps developers streamline to build fast, robust, and scalable applications on accelerated timelines. As The New Stack reports, developers spend only 32% of their time at work actually coding.
How observability, application security, and AI enhance DevOps and platform engineering maturity – blog Observability and AI can help ensure the reliability, security, and efficiency of DevOps and platform engineering. The following resources explore the ways in which AI makes DevSecOps more effective. Learn more in this blog.
Due to the complexity of these environments, developers and DevOps teams are increasingly spending more time instrumenting serverless apps and services, which limits their ability to focus on building and shipping new services. available for quite some time?already. applications,?mobile mobile apps,?or?APIs configuration. analyzed in?context
‘Composite’ AI, platform engineering, AI data analysis through custom apps This focus on data reliability and data quality also highlights the need for organizations to bring a “ composite AI ” approach to IT operations, security, and DevOps. Causal AI is critical to feed quality data inputs to the algorithms that underpin generative AI.
This approach supports innovation, ambitious SLOs, DevOpsscalability, and competitiveness. Dynatrace’s Site Reliability Guardian provides a platform for in-depth analysis and validation of service availability, performance, and capacity objectives throughout your entire digital environment. But how do they function in practice?
Our goal is to make this process simple, scalable, and enjoyable. Our enterprise-grade platform takes care of scalability and manageability including load balancing, routing, and central management. The extension framework covers the entire lifecycle of extensions including deployment and maintenance.
Upgrades and modifications, if available, are complex and expensive, so it isn’t easy to keep them secure and functional. Enable DevOps teams to modernize legacy apps Too many HHS IT organizations have an inventory of outdated applications with duplicative functionality, questionable states of health, and security vulnerabilities.
This is why I’m excited to announce the availability of a new Professional level certification from AWS that has been high on the list of our customers. Today, I am pleased to announce that we have released this exam publicly, as well as awarded our first DevOps Engineer certifications to those who successfully completed the beta exam.
Gaining a complete picture of app health in hybrid environments As a starting point, teams should know if ArcGIS and other critical apps are available. While uptime is essential, availability doesn’t ensure optimal performance. This is why application performance monitoring (APM) is essential.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content