This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. But is five nines availability attainable? What is always-on infrastructure?
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
Editor's Note: The following is an article written for and published in DZone's 2024 Trend Report, The Modern DevOps Lifecycle: Shifting CI/CD and Application Architectures. Forbes estimates that cloud budgets will break all previous records as businesses will spend over $1 trillion on cloud computing infrastructure in 2024.
DevOps automation can help to drive reliability across the SDLC and accelerate time-to-market for software applications and new releases. What is DevOps automation? DevOps automation is a set of tools and technologies that perform routine, repeatable tasks that engineers would otherwise do manually.
DevOps seeks to accomplish smooth and efficient software creation, delivery, monitoring, and improvement by prioritizing agility and adaptability over rigid, stage-by-stage development. What is DevOps? As DevOps pioneer Patrick Debois first described it in 2009, DevOps is not a specific technology, but a tactical approach. .”
The need for application and DevOps modernization to deliver on business outcomes has never been greater. Thats why Dynatrace will make its AI-powered, unified observability platform generally available on Google Cloud for all customers later this year. New customers will get the latest experience by default after general availability.
Cloud-native environments bring speed and agility to software development and operations (DevOps) practices. So which is it: SRE vs DevOps, or SRE and DevOps? DevOps is focused on optimizing software development and delivery, and SRE is focused on operations processes. DevOps as a philosophy. SRE vs DevOps?
As organizations accelerate innovation to keep pace with digital transformation, DevOps observability is becoming a critical key to success for DevOps and DevSecOps teams. DevOps and DevSecOps practices help organizations release software faster and more frequently, paving the way for digital transformation.
In response to the scale and complexity of modern cloud-native technology, organizations are increasingly reliant on automation to properly manage their infrastructure and workflows. DevOps automation eliminates extraneous manual processes, enabling DevOps teams to develop, test, deliver, deploy, and execute other key processes at scale.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? A DevOps platform engineer is a more recent term.
You have set up a DevOps practice. As we look at today’s applications, microservices, and DevOps teams, we see leaders are tasked with supporting complex distributed applications using new technologies spread across systems in multiple locations. DevOps metrics to help you meet your DevOps goals. Dynatrace news.
.” While this methodology extends to every layer of the IT stack, infrastructure as code (IAC) is the most prominent example. Here, we’ll tackle the basics, benefits, and best practices of IAC, as well as choosing infrastructure-as-code tools for your organization. What is infrastructure as code? Consistency.
As organizations mature on their digital transformation journey, they begin to realize that automation – specifically, DevOps automation – is critical for rapid software delivery and reliable applications. “In fact, this is one of the major things that [hold] people back from really adopting DevOps principles.”
More than 90% of enterprises now rely on a hybrid cloud infrastructure to deliver innovative digital services and capture new markets. That’s because cloud platforms offer flexibility and extensibility for an organization’s existing infrastructure. Dynatrace news. With public clouds, multiple organizations share resources.
Boost your operational resilience: Combining availability and security is now essential. Configuration and Compliance , adding the configuration layer security to both applications and infrastructure and connecting it to compliance. For example, for companies with over 1,000 DevOps engineers, the potential savings are between $3.4
DevOps and site reliability engineering (SRE) teams aim to deliver software faster and with higher quality. We refer to this culture and practice as observability-driven DevOps and SRE automation. The role of observability within DevOps. The results of observability-driven DevOps speak for themselves.
The end goal, of course, is to optimize the availability of organizations’ software. Dynatrace is widely recognized for its AI capabilities’ ability to predict and prevent issues, and automatically identify root causes, maximizing availability. Eventually, the goal is to arrive at self-healing through autonomous cloud operations.
Many organizations that have integrated their software development and operations into DevOps practices struggle with efficiency because they’re juggling disparate DevOps tools, or their tools aren’t meeting their needs. The status quo of the DevOps toolchain. How to approach transforming your DevOps processes.
Protecting IT infrastructure, applications, and data requires that you understand security weaknesses attackers can exploit. Cloud infrastructure analysis ensures the secure configuration of cloud infrastructure including virtual machines, containers, cloud-hosted databases, and serverless services. Dynatrace news.
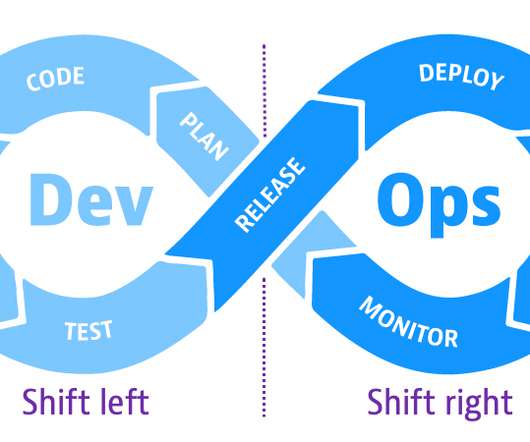
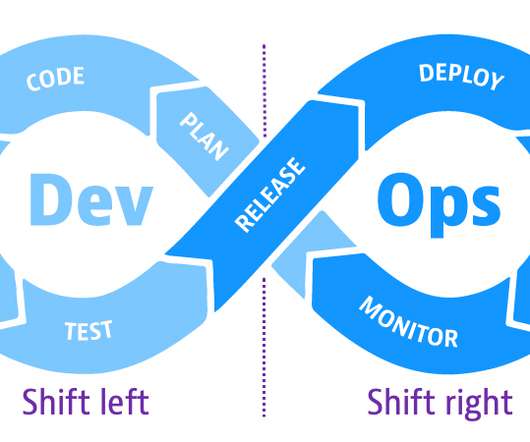
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
Service-level objectives (SLOs) are a great tool to align business goals with the technical goals that drive DevOps (Speed of Delivery) and Site Reliability Engineering (SRE) (Ensuring Production Resiliency). Availability. For availability, I always propose to use Dynatrace Synthetic vs looking at real user traffic.
Artisan Crafted Images In the Netflix full cycle DevOps culture the team responsible for building a service is also responsible for deploying, testing, infrastructure, and operation of that service. Now each change in the infrastructure is tested, canaried, and deployed like any other code change.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. While the SLO management web UI and API are already available, the dashboard tile will be released within the next weeks.
Navigate digital infrastructure complexity In today’s rapidly evolving digital environment, organizations face increasing pressure from customers and competitors to deliver faster, more secure innovations. The effectiveness of this automation relies on the quality of the underlying data.
The development of internal platform teams has taken off in the last three years, primarily in response to the challenges inherent in scaling modern, containerized IT infrastructures. Platform engineering best practices for delivering a highly available, secure, and resilient Internal Development Platform: Centralize and standardize.
In those cases, what should you do if you want to be proactive and ensure that your infrastructure is always up and running? Heading up the Platform Extension Services team at Dynatrace, we’re the go-to team for anything that isn’t available out of the box. Easy and flexible infrastructure monitoring. Platform extensions.
A platform encompasses a set of tools, services, and infrastructure that enables developers to build, test, and deploy software applications. These components are specific, predefined resources, such as libraries and templates, that are made available to all developers using the platform.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. The goal is to abstract away the underlying infrastructure’s complexities while providing a streamlined and standardized environment for development teams.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
This modular microservices-based approach to computing decouples applications from the underlying infrastructure to provide greater flexibility and durability, while enabling developers to build and update these applications faster and with less risk. A service mesh can solve these problems, but it can also introduce its own issues.
They handle complex infrastructure, maintain service availability, and respond swiftly to incidents. Predictive AI empowers site reliability engineers (SREs) and DevOps engineers to detect anomalies and irregular patterns in their systems long before they escalate into critical incidents. Proactive resource allocation.
Without the ability to see the logs that are relevant to your service, infrastructure, or cloud function—at exactly the right time and in exactly the right format—your cloud or DevOps engineers lose the ability to find the root causes of the issues they troubleshoot. Managing this change is difficult.
As organizations become cloud-native and their environments more complex, DevOps teams are adapting to new challenges. Today, the platform engineer role is gaining speed as the newest byproduct of scaling DevOps in the emerging but complex cloud-native world. What is this new discipline, and is it a game-changer or just hype?
Think of containers as the packaging for microservices that separate the content from its environment – the underlying operating system and infrastructure. The time and effort saved with testing and deployment are a game-changer for DevOps. In production, containers are easy to replicate.
SLOs can be a great way for DevOps and infrastructure teams to use data and performance expectations to make decisions, such as whether to release and where engineers should focus their time. SLOs enable DevOps teams to predict problems before they occur and especially before they affect customer experience. Availability.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
To accomplish this, organizations have widely adopted DevOps , which encompasses significant changes to team culture, operations, and the tools used throughout the continuous development lifecycle. Key components of GitOps are declarative infrastructure as code, orchestration, and observability. How to get started.
Dynatrace scored highest across 4 of 5 use cases, DevOps/AppDev, SRE/CloudOps, IT Operations, and Digital Experience Monitoring, and second highest in the Application Owner/Line of Business use case. We anticipated the industry’s move to dynamic multicloud environments and DevOps processes. Gartner Disclaimers.
Problem remediation is too time-consuming According to the DevOps Automation Pulse Survey 2023 , on average, a software engineer takes nine hours to remediate a problem within a production application. With that, Software engineers, SREs, and DevOps can define a broad automation and remediation mapping. Are you a managed customer?
ITOps is an IT discipline involving actions and decisions made by the operations team responsible for an organization’s IT infrastructure. Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure. ITOps vs. DevOps and DevSecOps.
Infrastructure health The underlying infrastructure’s health directly impacts application availability and performance. With these, you can implement checks that ensure your infrastructure is in a healthy state before a new version of a deployment is rolled out.
It will let you focus on where you want to be – building and running apps perhaps – while GKE Autopilot ‘self-flies’ the rest of the infrastructure for you. Just as GKE Autopilot is running your Kubernetes infrastructure, by deploying the Dynatrace Operator, the ? GKE Autopilot and beyond.
DevOps teams often use a log monitoring solution to ingest application, service, and system logs so they can detect issues at any phase of the software delivery life cycle (SDLC). Log analytics also help identify ways to make infrastructure environments more predictable, efficient, and resilient.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content