This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOpsengineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? .”
In response to this shift, platform engineering is growing in popularity. The practice of platform engineering has evolved alongside the increasing complexity of cloud environments. Platform engineers design and implement these platforms, as well as ensure their security, scalability, and reliability.
Cloud-native environments bring speed and agility to software development and operations (DevOps) practices. So which is it: SRE vs DevOps, or SRE and DevOps? DevOps is focused on optimizing software development and delivery, and SRE is focused on operations processes. DevOps as a philosophy. SRE vs DevOps?
As organizations accelerate innovation to keep pace with digital transformation, DevOps observability is becoming a critical key to success for DevOps and DevSecOps teams. DevOps and DevSecOps practices help organizations release software faster and more frequently, paving the way for digital transformation.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
As organizations become cloud-native and their environments more complex, DevOps teams are adapting to new challenges. Site reliability engineering first emerged to address cloud computing’s new performance needs. Understanding the platform engineer role DevOps is a constantly evolving discipline.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of software engineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026.
Editor's Note: The following is an article written for and published in DZone's 2024 Trend Report, The Modern DevOps Lifecycle: Shifting CI/CD and Application Architectures. By integrating observability tools in CI/CD pipelines, organizations can increase deployment frequency, minimize risks, and build highly available systems.
DevOps automation can help to drive reliability across the SDLC and accelerate time-to-market for software applications and new releases. What is DevOps automation? DevOps automation is a set of tools and technologies that perform routine, repeatable tasks that engineers would otherwise do manually.
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE bridges the gap between Dev and Ops teams. SRE focuses on automation.
Whether it means jumping between multiple windows, sifting through extensive logs to track down bugs, trying to reproduce locally, or requesting additional redeployments from DevOps, debugging poses significant challenges and a resource drain. Source code is loaded only on an engineers workstation, using the engineers privileges.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. The pair showed how to track factors including developer velocity, platform adoption, DevOps research and assessment metrics, security, and operational costs.
DevOps and site reliability engineering (SRE) teams aim to deliver software faster and with higher quality. We refer to this culture and practice as observability-driven DevOps and SRE automation. The role of observability within DevOps. The results of observability-driven DevOps speak for themselves.
DevOps automation eliminates extraneous manual processes, enabling DevOps teams to develop, test, deliver, deploy, and execute other key processes at scale. Automation can be particularly powerful when applied to DevOps workflows. Automation thus contributes to accelerated productivity and innovation across the organization.
As organizations mature on their digital transformation journey, they begin to realize that automation – specifically, DevOps automation – is critical for rapid software delivery and reliable applications. “In fact, this is one of the major things that [hold] people back from really adopting DevOps principles.”
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Too many SLOs create complexity for DevOps. With many pipelines to maintain, DevOps teams need automated orchestration. Dynatrace news.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
The end goal, of course, is to optimize the availability of organizations’ software. Dynatrace is widely recognized for its AI capabilities’ ability to predict and prevent issues, and automatically identify root causes, maximizing availability. Eventually, the goal is to arrive at self-healing through autonomous cloud operations.
Many organizations that have integrated their software development and operations into DevOps practices struggle with efficiency because they’re juggling disparate DevOps tools, or their tools aren’t meeting their needs. The status quo of the DevOps toolchain. How to approach transforming your DevOps processes.
So how do development and operations (DevOps) teams and site reliability engineers (SREs) distinguish among good, great, and suboptimal SLOs? The state of service-level objectives While SLOs play a critical role in helping DevOps and SRE teams align technical objectives with business goals, they’re not always easy to define.
The need for application and DevOps modernization to deliver on business outcomes has never been greater. Thats why Dynatrace will make its AI-powered, unified observability platform generally available on Google Cloud for all customers later this year. New customers will get the latest experience by default after general availability.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). Here’s what these metrics mean and how they relate to other DevOps metrics such as MTTA, MTTF, and MTBF. Mean time to respond (MTTR) is the average time it takes DevOps teams to respond after receiving an alert.
Boost your operational resilience: Combining availability and security is now essential. For example, for companies with over 1,000 DevOpsengineers, the potential savings are between $3.4 Its time to adopt a unified observability and security approach.
Site Reliability Guardian provides an automated change impact analysis to validate service availability, performance, and capacity objectives across various systems. Leveraging code-level insights and transaction analysis, Dynatrace Runtime Application Protection automatically detects attacks on applications in your environment.
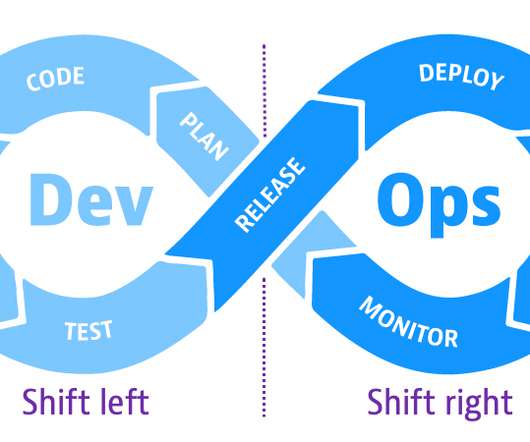
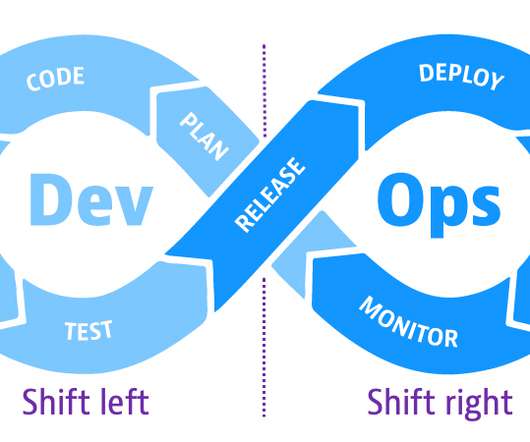
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
This is important because manual tracing is super costly and there is a lack of information available on this topic to assist developers. We’ll look at lifecycle management and then move on to tracing, while sharing some exciting announcements about Google Kubernetes Engine along the way.
Service-level objectives (SLOs) are a great tool to align business goals with the technical goals that drive DevOps (Speed of Delivery) and Site Reliability Engineering (SRE) (Ensuring Production Resiliency). Availability. For availability, I always propose to use Dynatrace Synthetic vs looking at real user traffic.
Site reliability engineering (SRE) continues to gain popularity as organizations embrace hybrid cloud strategies and IT automation at scale. By applying software engineering principles to operations and infrastructure practices, SRE enables organizations to streamline and automate IT processes. Dynatrace news.
Artisan Crafted Images In the Netflix full cycle DevOps culture the team responsible for building a service is also responsible for deploying, testing, infrastructure, and operation of that service. A key responsibility of Netflix engineers is identifying gaps and pain points in the development and operation of services.
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. But is five nines availability attainable? Downtime per year. 90% (one nine).
When it comes to platform engineering, not only does observability play a vital role in the success of organizations’ transformation journeys—it’s key to successful platform engineering initiatives. The various presenters in this session aligned platform engineering use cases with the software development lifecycle.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. While the SLO management web UI and API are already available, the dashboard tile will be released within the next weeks.
Site reliability engineering (SRE) is a discipline in which automated software systems are built to manage the development operations (DevOps) of a product or service. In other words, SRE automates the functions of an operations team via software systems.
Wondering which high availability framework to use for your PostgreSQL deployments ? We compared the top 3 frameworks, PostgreSQL Automatic Failover (PAF) vs. Replication Manager (repmgr) vs. Patroni , in our Managing High Availability in PostgreSQL series. PostgreSQL High Availability Framework Infographic.
In this blog, I will be going through a step-by-step guide on how to automate SRE-driven performance engineering. Instead of getting these answers in the multi-dimensional analysis view, we can define Calculated Service Metrics to have these data points available as metrics (SLIs). Dynatrace news.
For example, it can help DevOps and platform engineering teams write code snippets by drawing on information from software libraries. It relies on the accuracy and quality of the publicly available information and input it draws from, which may be untrustworthy or biased.
They handle complex infrastructure, maintain service availability, and respond swiftly to incidents. Predictive AI empowers site reliability engineers (SREs) and DevOpsengineers to detect anomalies and irregular patterns in their systems long before they escalate into critical incidents. Capacity planning.
Over the past years, the adoption of Agile and DevOps grew, and together with it, we have also observed the rise of DevSecOps. Such practice recommends shifting left security testing and remediation of security vulnerabilities as early as possible within the SDLC.
Without the ability to see the logs that are relevant to your service, infrastructure, or cloud function—at exactly the right time and in exactly the right format—your cloud or DevOpsengineers lose the ability to find the root causes of the issues they troubleshoot. Now, you can set up your Firehose stream.
To keep up with current demands, DevOps and platform engineering teams need a solution that can fully embrace and understand complexity, delivering precise answers that enable the creation of trustworthy automation. The effectiveness of this automation relies on the quality of the underlying data.
The time and effort saved with testing and deployment are a game-changer for DevOps. Running containers : Docker Engine is a container runtime that runs in almost any environment: Mac and Windows PCs, Linux and Windows servers, the cloud, and on edge devices. In production, containers are easy to replicate. What is Kubernetes?
Keeping pace with modern digital transformation requires ensuring that applications are responsive, resilient, and always available amid increased complexity. Site reliability engineering (SRE) has recently become a critical discipline in recent years as the world has shifted in favor of web-based interactions.
Powered by Grail and the Dynatrace AutomationEngine , Site Reliability Guardian helps DevOps platform teams make better-informed release decisions by utilizing all the contextual observability and application security insights of the Dynatrace platform. This is where Site Reliability Engineering (SRE) practices are applied.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content