This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
that offers security, scalability, and simplicity of use. Python code also carries limited scalability and the burden of governing its security in production environments and lifecycle management. address these limitations and brings new monitoring and analytical capabilities that weren’t available to Extensions 1.0:
As enterprises expand their software development practices and scale their DevOps pipelines, effective management of continuous integration (CI) and continuous deployment (CD) processes becomes increasingly important. GitHub, as one of the most widely used source control platforms, plays a central role in modern development workflows.
Scalable Annotation Service — Marken by Varun Sekhri , Meenakshi Jindal Introduction At Netflix, we have hundreds of micro services each with its own data models or entities. All data should be also available for offline analytics in Hive/Iceberg. All of these services at a later point want to annotate their objects or entities.
This blog post will explore these exciting developments and what they mean for organizations. Streamlining observability with Dynatrace OneAgent on AWS Image Builder In our ongoing collaboration with AWS, we’re excited to make the Dynatrace OneAgent available as a first-class integration on AWS Image Builder via the AWS Marketplace.
The end goal, of course, is to optimize the availability of organizations’ software. Dynatrace is widely recognized for its AI capabilities’ ability to predict and prevent issues, and automatically identify root causes, maximizing availability.
Because it’s critical that operations teams ensure that all internal resources are available for their users, synthetic monitoring of those resources is important. Some organizations need to weigh cost considerations due to technology and business scalability limitations whereas others need to adhere to company policies.
Effective application development requires speed and specificity. Applications must work as intended and make their way through development pipelines as quickly as possible. FaaS enables enterprises to deliver on the evolving expectations of fast and furious app development. But what is FaaS? What is FaaS?
Once you develop best practices and are confident with your consumption patterns, you can switch to usage-based pricing to maximize the value of your DPS investment. Disclaimer: This publication may include references to the planned testing, release, and/or availability of Dynatrace products and services.
Managing High Availability (HA) in your PostgreSQL hosting is very important to ensuring your database deployment clusters maintain exceptional uptime and strong operational performance so your data is always available to your application. Effective management of failover and switchover operations is crucial for high availability.
This decoupling simplifies system architecture and supports scalability in distributed environments. Kafka stores and distributes data through a partitioned log system, which spans multiple brokers to provide fault tolerance and scalability. It supports clustering to maintain message availability in fault-tolerant environments.
The log ingestion wizard offers support for all log ingestion methods available in Dynatrace Hub Get started with Logs: The OneAgent advantage For most scenarios, Dynatrace OneAgent is your best friend for getting started with Dynatrace log ingestion. Different log ingestion methods are available to address various needs.
Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges. Implementing clustering and quorum queues in RabbitMQ significantly improves load distribution and data redundancy, ensuring high availability and fault tolerance for messaging services.
This limitation has inspired us to develop a foundation model for recommendation. These insights have shaped the design of our foundation model, enabling a transition from maintaining numerous small, specialized models to building a scalable, efficient system. We see promising results from downstream integrations.
However, a more scalable approach would be to begin with a new foundation and begin a new building. The facilities are modern, spacious and scalable. What does this example have to do with software development and video encoding? We also describe how you can become a part of this development. What is SVT-AV1?
Standardization To standardize communication between our observability service and the personalization stacks observability endpoints, weve developed a stable proto request/response format. This endpoint efficiently reads from all available Hollow Feeds to obtain the current status, thanks to Hollows in-memory capabilities.
For the 2024 Dynatrace Partner App Competition, we invited all our partners to showcase their ingenuity in developing impactful apps that solve real-world customer use cases using Dynatrace AppEngine. These certified app developers have a strong track record of building exceptional Dynatrace Apps.
While both platforms share some similarities, they differ in architecture, scalability, high availability, container management, and learning curve. The question of which of these platforms wins the container war is a common one among developers, architects, and IT teams.
The development of internal platform teams has taken off in the last three years, primarily in response to the challenges inherent in scaling modern, containerized IT infrastructures. The old saying in the software development community, “You build it, you run it,” no longer works as a scalable approach in the modern cloud-native world.
This operational component places some cognitive load on our engineers, requiring them to develop deep understanding of telemetry and alerting systems, capacity provisioning process, security and reliability best practices, and a vast amount of informal knowledge about the cloud infrastructure.
PostgreSQL 17 provides faster processing, greater efficiency, and better scalability for modern database needs. Get automated backups, high availability, and seamless scalingso you can focus on your applications, not database maintenance. Simplify PostgreSQL management with ScaleGrids fully managed PostgreSQL service.
With growing multicloud complexity and the need for organization-wide scalability, self-service and automation capabilities have become increasingly essential for developer productivity. A platform encompasses a set of tools, services, and infrastructure that enables developers to build, test, and deploy software applications.
Enabling keyboard shortcuts and possessing visual appeal and transparency to minimize strain on wrists and eyesight to prevent Carpal Tunnel Syndrome and visual impairment from developing in users. To conclude, GUIs are a vital addition to ease the lives of database users and developers. Easy to use and highly customizable.
Scalability. Finally, there’s scalability. AWS AppSync: AppSync offers a fully managed approach to developing APIs with GraphQL — connecting to AWS DynamoLB or Lambda along with adding caches and client-side data. Serverless solutions are also more reliable than their traditional application counterparts. Data Store.
Regarding contemporary software architecture, distributed systems have been widely recognized for quite some time as the foundation for applications with high availability, scalability, and reliability goals. It seeks to make Java EE programming easier and increase developers' productivity in the workplace.
In this article, we compare Oracle vs. PostgreSQL, outlining the differences in these SQL database costs, features, and ease of use for both developers and database administrators (DBA’s) alike. Oracle functionality across available tools, capabilities and services. Not available. Not available. Not available.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
Amazon’s new general-purpose Linux for AWS is designed to provide a secure, stable, and high-performance execution environment to develop and run cloud applications. This is done by detecting availability and performance problems in real time across an entire technology stack while presenting teams with answers — not alert storms.
Greenplum Database is an open-source , hardware-agnostic MPP database for analytics, based on PostgreSQL and developed by Pivotal who was later acquired by VMware. Greenplum uses an MPP database design that can help you develop a scalable, high performance deployment. What Exactly is Greenplum? At a glance – TLDR.
As our customers continue to embrace digital transformation, the need for scalable and flexible identity federation within our platform is apparent. Dynatrace Flexible Identity Federation extends the currently available configuration options to include federation at the Dynatrace account or environment level.
With more organizations taking the multicloud plunge, monitoring cloud infrastructure is critical to ensure all components of the cloud computing stack are available, high-performing, and secure. Website monitoring examines a cloud-hosted website’s processes, traffic, availability, and resource use. Database monitoring.
By Alok Tiagi , Hariharan Ananthakrishnan , Ivan Porto Carrero and Keerti Lakshminarayan Netflix has developed a network observability sidecar called Flow Exporter that uses eBPF tracepoints to capture TCP flows at near real time. Without having network visibility, it’s difficult to improve our reliability, security and capacity posture.
Container technology is very powerful as small teams can develop and package their application on laptops and then deploy it anywhere into staging or production environments without having to worry about dependencies, configurations, OS, hardware, and so on. The time and effort saved with testing and deployment are a game-changer for DevOps.
Even if you are not considering all the interesting improvements that have been added by the development team from MongoDB, this new version is already very important from the database supportability and lifecycle planning perspective. We also want to focus more on the security aspects not available outside of MongoDB Enterprise.
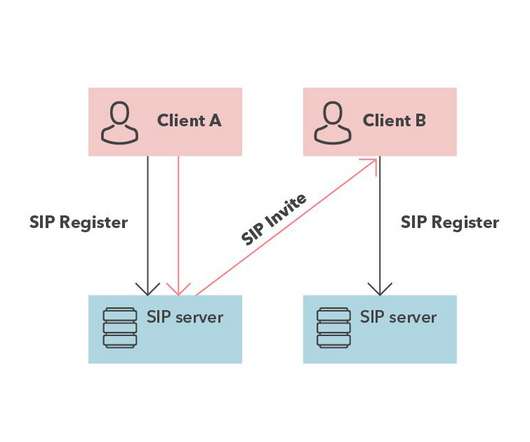
This is not to say, however, that any mid-level developer will have much difficulty finding and handling one of many available open-source servers. You may also like: Application Scalability — How To Do Efficient Scaling. VoIP technologies have a reputation for being rather complex and not without good reason.
As someone who has worked deep in the coding trenches with developers my whole life, I’ve hand-picked the top three mistakes you can make when moving to Kubernetes. A single pod may consume all the CPU or memory available on the node, causing its neighbors to be starved of CPU or hit Out of Memory errors. Easy scalability.
Cloud-native environments bring speed and agility to software development and operations (DevOps) practices. DevOps is focused on optimizing software development and delivery, and SRE is focused on operations processes. Organizations often need to do some team building to synthesize the objectives of developers and operations.
This means we need to distinguish between availability of SKUs and eligibility for SKUs. You can think of eligibility as something that is applied at the user level, while availability is at the country level. The SKU Platform contains the global set of SKUs and as a result, is said to control the availability of SKUs.
As our customers adopt agile software development and continuous delivery to drive value faster, they face new risks that could impact availability, performance, and business KPIs. However, adding more stakeholders can also run the risk of silos developing between internal organizations. Availability. Dynatrace news.
Move towards BizDevOps : Cover all automation and integration use cases across your organization, not just in the Development department. Many use cases in your software development, delivery, and operations depend on the real-time data that your Dynatrace monitoring environment collects. Automate your business with Dynatrace.
We’re excited to announce our verified HashiCorp Terraform integration is now available for Dynatrace customers. To streamline the observability of these complex environments, monitoring as code provides a way for developers to configure the dashboards and reports they need at the code level. Dynatrace news. Step 3: Apply.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
Dynatrace analytics capabilities, powered by hypermodal AI , enable executives to drive improved availability , strengthened security compliance , and heightened confidence in AI initiatives. Executives are shifting to proactive risk management, aiming to prevent availability issues and expedite remediation.
SREs and DevOps engineers need cloud logs in an integrated observability platform to monitor the whole software development lifecycle. With this out-of-the-box support for scalable data ingest, log data is immediately available to your teams for troubleshooting and observability, investigating security issues, or auditing.
Many organizations also adopt an observability solution to help them detect and analyze the significance of events to their operations, software development life cycles, application security, and end-user experiences. The architects and developers who create the software must design it to be observed.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content