This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the world of cloud computing, virtual machines (VMs) have revolutionized the way businesses operate by providing scalable and flexible computing resources. Among the multitude of VM options available, Azure B Series Virtual Machines stand out as a cost-effective and efficient choice for various workloads.
The certification results are now publicly available. The calculations and methodology used are in line with the best available scientific approach, as well as with relevant reporting requirements. Thermal design power (TDP) values are derived from AMD and Intel to calculate CPU power consumption.
are technologically very different, Python and JMX extensions designed for Extension Framework 1.0 Extensions can monitor virtually any type of technology in your environment. address these limitations and brings new monitoring and analytical capabilities that weren’t available to Extensions 1.0: to the Extension Framework 2.0,
Successfully coordinating messages among these services is a fundamental aspect of their design. There are two popular methodologies available to tackle this challenge. Can a central orchestrator virtually manage all the business problems, or are there scenarios where a different approach besides being preferable is also essential?
Amazon’s new general-purpose Linux for AWS is designed to provide a secure, stable, and high-performance execution environment to develop and run cloud applications. This is done by detecting availability and performance problems in real time across an entire technology stack while presenting teams with answers — not alert storms.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
Microsoft initially designed the OS for internal use to develop and manage Azure services. Today, it’s a generally available container host for AKS and AKS-HCI. Microsoft designed the kernel and other aspects of the OS with an emphasis on security due to its focused role in executing container workloads.
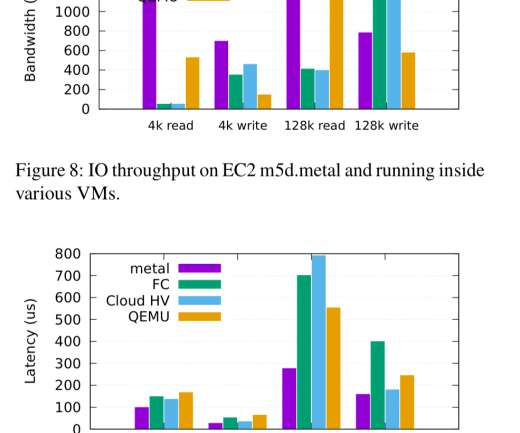
We looked at a couple of papers that had pre-prints available last week, today we’ll be looking at one of the most anticipated papers of this year’s crop: Amazon’s Firecracker. Firecracker is the virtual machine monitor (VMM) that powers AWS Lambda and AWS Fargate, and has been used in production at AWS since 2018.
Nevertheless, there are related components and processes, for example, virtualization infrastructure and storage systems (see image below), that can lead to problems in your Kubernetes infrastructure. When designing and running modern, scalable, and distributed applications, Kubernetes seems to be the solution for all your needs.
When it comes to access to their applications, users demand instant, reliable, and secure interactions — and that means databases must be highly available. With database high availability (HA), services are largely uninterrupted, and end users are largely satisfied. The obvious answer is this: To achieve high availability.
All of this convenient visibility is available with just a few clicks. This helps significantly in automatically answering complex questions such as “ Is the CPU saturation of my F5 device caused by any of the virtual servers running on it? Virtual servers. Start monitoring in minutes. Pool nodes. Interfaces.
Citrix is critical infrastructure For businesses operating in industries with strict regulations, such as healthcare, banking, or government, Citrix virtual apps and virtual desktops are essential for simplified infrastructure management, secure application delivery, and compliance requirements. Now, it’s available to all customers.
And because Dynatrace can consume CloudWatch metrics, almost all your AWS usage information is available to you within Dynatrace. Similarly, integrations for Azure and VMware are available to help you monitor your infrastructure both in the cloud and on-premises. Dynatrace VMware and virtualization documentation .
Dynatrace’s ability to ingest metrics from all 95 AWS services will be available within the next 60 days. Those in the left column are readily available now, with those in the right available soon. Available Now. Achieve full observability of all AWS services. Coming Soon. AWS AppSync. AWS CloudHSM. Amazon AppStream 2.0.
Getting precise root cause analysis when dealing with several layers of virtualization in a containerized world. The Azure Well-Architected Framework is a set of guiding tenets organizations can use to evaluate architecture and implement designs that will scale over time. Design applications to recover from errors gracefully.
This transition to public, private, and hybrid cloud is driving organizations to automate and virtualize IT operations to lower costs and optimize cloud processes and systems. Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure.
DevOps platform engineers are responsible for cloud platform availability and performance, as well as the efficiency of virtual bandwidth, routers, switches, virtual private networks, firewalls, and network management. DevOps engineer tools can help ease the pressure as environment complexity grows.
To keep infrastructure and bare metal servers running smoothly, a long list of additional devices are used, such as UPS devices, rack cases that provide their own cooling, power sources, and other measures that are designed to prevent failures. Some SNMP-enabled devices are designed to report events on their own with so-called SNMP traps.
As the demand for services grows and containerized applications deploy across multicloud environments, organizations need a more flexible, cohesive approach for designing and developing a distributed systems architecture. Experienced developers see microservice design patterns as more platform-agnostic.
Cloud providers then manage physical hardware, virtual machines, and web server software management. Increased availability. Because FaaS is a cloud-native approach, it makes great use of multisite cloud architecture to improve availability and reliability. Consider the challenges of function as a service.
With the average cost of unplanned downtime running from $300,000 to $500,000 per hour , businesses are increasingly using high availability (HA) technologies to maximize application uptime. Where a high availabilitydesign once worked well, it can no longer keep up with more complex requirements.
Kubernetes (aka K8s) is an open-source platform used to run and manage containerized applications and services on clusters of physical or virtual machines across on-premises, public, private, and hybrid clouds. This virtualization makes it possible to efficiently deploy and securely run a container independently of the hosting infrastructure.
Logs are immediately available for troubleshooting, security investigations, and auditing, becoming integral to the platform alongside traces and metrics. Dynatrace support for AWS Firehose includes Lambda logs, Amazon virtual private cloud (VPC) flow logs, S3 logs, and CloudWatch.
DEM provides an outside-in approach to user monitoring that measures user experience (UX) in real time to ensure applications and services are available, functional, and well-performing across all channels of the digital experience, including web, mobile, and IoT. PC, smartphone, server) or virtual (virtual machines, cloud gateways).
With so much at stake, database high availability and fault tolerance have become must-have items, but many companies just aren’t certain which one they must have. This blog article will examine shared attributes of high availability (HA) and fault tolerance (FT). What does high availability mean?
The Value Of Concept Testing As Part Of Product Design. The Value Of Concept Testing As Part Of Product Design. UX design teams are passionate about our approach to solving problems and providing users with experiences that lead to their desired outcomes. UX teams should consider it a mandatory step in designing a product.
One important choice you will still have to make is what type and size of Azure virtual machine you want to use for your existing SQL Server workload. Microsoft currently has eight main types of virtual machines designed for different types of workloads. Azure VM Types and Series.
Virtualization has revolutionized system administration by making it possible for software to manage systems, storage, and networks. Design, implement, and tune effective SLOs. Organizations should seek to standardize a single set of tools that everyone will use. This number will likely increase as the SRE discipline matures.
But to understand if your cloud-based applications, as well as environments they run in, are working as designed, you need to see how every single application component communicates and interacts with the others. Supporting services include every service that isn’t available with out-of-the-box Dynatrace monitoring. Configuration.
VPC Flow Logs is an Amazon service that enables IT pros to capture information about the IP traffic that traverses network interfaces in a virtual private cloud, or VPC. This support enables customers to define specific endpoint delivery of real-time streaming data to platforms such as Dynatrace. What is VPC Flow Logs?
For example, the number of threads of your process is already available in Dynatrace in most cases, so there is no need to spend the extra effort. Virtualization can be a key player in your process’ performance, and Dynatrace has built-in integrations to bring metrics about the Cloud Infrastructure into your Dynatrace environment.
DigitalOcean specialized in SSD-based virtual machines called Droplets that are broken down into four simple categories. If you’re running MongoDB on DigitalOcean in production, it’s best practices to deploy using a replica set to ensure high availability and data redundancy for your clusters. DigitalOcean Droplets.
In a sea of virtualized layers of abstraction, shared services, and dependencies, the cloud has become increasingly complex. Our platform needed a full-stack approach, including virtual network infrastructure, containers, applications, and users. The Gartner document is available upon request from Dynatrace LLC.
Many hospitals adopted telehealth and other virtual technology to deliver care and reduce the spread of disease. AIOps plays a critical role in this app’s availability. We achieved levels of availability we’ve never been able to hit before,” said the chief architect of the healthcare provider.
But to understand if your cloud-based applications, as well as environments they run in, are working as designed, you need to see how every single application component communicates and interacts with the others. Supporting services include every service that isn’t available with out-of-the-box Dynatrace monitoring. Configuration.
At Netflix, we periodically reevaluate our workloads to optimize utilization of available capacity. While we understand it’s virtually impossible to achieve a linear increase in throughput as the number of vCPUs grow, a near-linear increase is attainable. We decided to move one of our Java microservices?—?let’s let’s call it GS2?—?to
Today we have a wealth of tools, both OSS and commercial, all designed for cloud-native environments. Since there were no existing solutions available, we needed to build them ourselves. To improve availability, we designed systems where components could fail separately and avoid single points of failure.
O ne of the principles behind the design of Kubernetes is to always look at optimiz ing the utilization of compute resources by the workload. For example, a pod might be stuck in a “Pending” state if it cannot be scheduled to run on any node because there aren’t sufficient resources available. This does not happen magically.
Instead of diving in arguing about specific points (which I partly did in my earlier post – start from The Future of Performance Testing if you are interested), I decided to talk to people who monetize on these “myths” So here is a virtual interview with Guillaume Betaillouloux , co-founder and Performance Director of OctoPerf.
A new generation of automated solutions — designed to provide end-to-end observability of assets, applications, and performance across legacy and cloud systems — make that job easier, says Federal Chief Technology Officer Willie Hicks at Dynatrace. But these systems must always be on and highly available. What’s the root cause?
Unfortunately, container security is much more difficult to achieve than security for more traditional compute platforms, such as virtual machines or bare metal hosts. Consider using lightweight Linux distributions that are specifically designed for hosting containers, such as Red Hat Enterprise Linux Atomic Host or CoreOS.
In fact, once containerized, many of these services and the source code itself is virtually invisible in a standalone Kubernetes environment. Wait…isn’t Kubernetes specifically designed to automate tasks associated with deploying clustered services? Foundational root-cause that is the deployment or configuration change responsible.
During our virtual wine tasting event, there were three key themes that came to light about how attendees’ businesses had had to change to meet the new way of working. An eCommerce leader in designer menswear. With a shift to focusing on digital channels, availability and performance are key to business success. Dynatrace news.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content