This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This year’s AWS re:Invent will showcase a suite of new AWS and Dynatrace integrations designed to enhance cloud performance, security, and automation. The rapid evolution of cloud technology continues to shape how businesses operate and compete.
As organizations increasingly migrate their applications to the cloud, efficient and scalable load balancing becomes pivotal for ensuring optimal performance and high availability. Each of these services addresses specific use cases, offering diverse functionalities to meet the demands of modern applications. What Is Load Balancing?
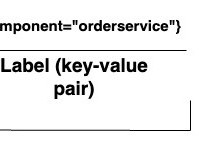
that offers security, scalability, and simplicity of use. are technologically very different, Python and JMX extensions designed for Extension Framework 1.0 Python code also carries limited scalability and the burden of governing its security in production environments and lifecycle management. Extensions 2.0 Extensions 2.0
Scalable Annotation Service — Marken by Varun Sekhri , Meenakshi Jindal Introduction At Netflix, we have hundreds of micro services each with its own data models or entities. All data should be also available for offline analytics in Hive/Iceberg. All of these services at a later point want to annotate their objects or entities.
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
It also supports scalability, making it suitable for organizations of all sizes. The system demands significant effort to design, manage, and maintain, especially as an organization’s needs evolve. High flexibility , adapting to dynamic environments and diverse user needs.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. This decoupling simplifies system architecture and supports scalability in distributed environments. Choosing between RabbitMQ and Kafka depends on your specific messaging needs.
The log ingestion wizard offers support for all log ingestion methods available in Dynatrace Hub Get started with Logs: The OneAgent advantage For most scenarios, Dynatrace OneAgent is your best friend for getting started with Dynatrace log ingestion. Different log ingestion methods are available to address various needs.
Managing High Availability (HA) in your PostgreSQL hosting is very important to ensuring your database deployment clusters maintain exceptional uptime and strong operational performance so your data is always available to your application. Effective management of failover and switchover operations is crucial for high availability.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
We’re therefore excited to announce that Dynatrace has received the Amazon RDS Service Ready designation. Achieving this designation differentiates Dynatrace as an AWS Advanced Technology Partner with a product that is integrated with Amazon RDS and is generally available and fully supported.
Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges. Implementing clustering and quorum queues in RabbitMQ significantly improves load distribution and data redundancy, ensuring high availability and fault tolerance for messaging services.
Grafana Loki is a horizontally scalable, highly available log aggregation system. It is designed for simplicity and cost-efficiency. Created by Grafana Labs in 2018, Loki has rapidly emerged as a compelling alternative to traditional logging systems, particularly for cloud-native and Kubernetes environments.
These insights have shaped the design of our foundation model, enabling a transition from maintaining numerous small, specialized models to building a scalable, efficient system. It enables large-scale semi-supervised learning using unlabeled data while also equipping the model with a surprisingly deep understanding of world knowledge.
This endpoint efficiently reads from all available Hollow Feeds to obtain the current status, thanks to Hollows in-memory capabilities. Many of the metadata and assets involved in title setup have specific timelines for when they become available to members.
Because of the emergence of cloud services, a broad range of storage choices are now easily available to fulfill the different demands of both organizations and people. These storage alternatives have been designed to meet a range of requirements, including performance, scalability, durability, and price.
Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Scalability. Finally, there’s scalability. The first benefit is simplicity. Let’s explore each in more detail. Compute services.
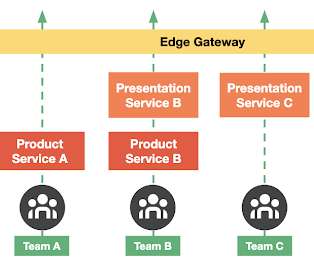
The making of Edge Gateway, the highly-available and scalable self-serve gateway to configure, manage, and monitor APIs of every business domain at Uber. Evolution of Uber’s API gateway.
It’s architecture was specially designed to manage large-scale data warehouses and business intelligence workloads by giving you the ability to spread your data out across a multitude of servers. Greenplum uses an MPP database design that can help you develop a scalable, high performance deployment. At a glance – TLDR.
While this architectural approach offers scalability, reusability, and adaptability, it also presents a unique challenge: effectively managing communication between these microservices. Successfully coordinating messages among these services is a fundamental aspect of their design.
Analytics Engineers deliver these insights by establishing deep business and product partnerships; translating business challenges into solutions that unblock critical decisions; and designing, building, and maintaining end-to-end analytical systems. DJ has a strong pedigreethere are several prior semantic layers in the industry (e.g.
Amazon’s new general-purpose Linux for AWS is designed to provide a secure, stable, and high-performance execution environment to develop and run cloud applications. This is done by detecting availability and performance problems in real time across an entire technology stack while presenting teams with answers — not alert storms.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
Regarding contemporary software architecture, distributed systems have been widely recognized for quite some time as the foundation for applications with high availability, scalability, and reliability goals. Spring Boot's default codes and annotation setup lessen the time it takes to design an application.
Scalability and cloud-native support: Dynatrace is designed to scale effortlessly in dynamic Kubernetes environments. It automates tasks such as provisioning and scaling Dynatrace monitoring components, updating configurations, and ensuring the health and availability of the monitoring infrastructure.
Performances testing helps establish the scalability, stability, and speed of the software application. Confirming scalability, dependability, stability, and speed of the app is crucial. Therefore, designing and implementing such tests are crucial to ensure the stability of the website.
Learning Resources: Are there tutorials, guides, and comprehensive documentation available for the tool? Cross-Platform Compatibility: Is the tool available on multiple operating systems (Windows, macOS, Linux)? Lacks some advanced coding and debugging tools available in other products. Pricing: Free: Only 14-day trial.
In the world of cloud computing, virtual machines (VMs) have revolutionized the way businesses operate by providing scalable and flexible computing resources. Among the multitude of VM options available, Azure B Series Virtual Machines stand out as a cost-effective and efficient choice for various workloads.
When it comes to access to their applications, users demand instant, reliable, and secure interactions — and that means databases must be highly available. With database high availability (HA), services are largely uninterrupted, and end users are largely satisfied. The obvious answer is this: To achieve high availability.
With growing multicloud complexity and the need for organization-wide scalability, self-service and automation capabilities have become increasingly essential for developer productivity. Platform engineers design and implement these platforms, as well as ensure their security, scalability, and reliability.
The old saying in the software development community, “You build it, you run it,” no longer works as a scalable approach in the modern cloud-native world. Platform engineering best practices for delivering a highly available, secure, and resilient Internal Development Platform: Centralize and standardize.
In particular, it’s our job to design and build the systems and protocols that enable customers from all over the world to sign up for Netflix with the plan features and incentives that best suit their needs. This was a perfectly sufficient design for many years. To name a few: Updating XML files is error-prone and manual in nature.
Before an organization moves to function as a service, it’s important to understand how it works, its benefits and challenges, its effect on scalability, and why cloud-native observability is essential for attaining peak performance. Increased availability. How does function as a service affect scalability? What is FaaS?
.” [1] –Gartner ® These drivers and the growing complexity of data privacy regulations make manual handling of these requests unsustainable, necessitating automated and scalable solutions. 2] — Nader Henein, VP Analyst, Gartner The Privacy Rights app is designed to streamline this process in Dynatrace.
Level up your analytics game: Enhanced team collaboration and advanced data insights With traces now stored in Dynatrace Grail, our scalable data lakehouse, you can unlock powerful new analytics capabilities, handle massive volumes of data, and run complex queries seamlessly.
These environments offer improved agility and scalability, and they also increase complexity, often making it more challenging for organizations to monitor and manage their applications. Complimentary copies of the 2024 Gartner Magic Quadrant for Observability Platforms are available on the Dynatrace website.
SRE is the transformation of traditional operations practices by using software engineering and DevOps principles to improve the availability, performance, and scalability of releases by building resiliency into apps and infrastructure. Designating and managing Service Level Objectives (SLOs) as availability targets for a service.
Anticipating the evolution of our market, we designed the Dynatrace Software Intelligence Platform to: Provide the broadest multicloud observability , spanning applications, infrastructure, user experience, AIOps, automation, and application security in a single platform, to provide a single source of truth across the full stack.
Introducing Metrics on Grail Despite their many advantages, modern cloud-native architectures can result in scalability and fragmentation challenges. Grail solves this scalability issue! These principles all align with a single, overarching goal: making data and insights derived from analytics available to a wider audience.
You are designing a learning system to forecast Service Level Agreement (SLA) violations and would want to factor in all upstream dependencies and corresponding historical states. Design a flexible data model ? —?Represent Therefore, the ingestion approach for data lineage is designed to work with many disparate data sources.
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. This is not an easy task, considering the wide variety of supported devices and the sheer volume of actions our members perform.
The exponential growth of data volume—including observability, security, software lifecycle, and business data—forces organizations to deal with cost increases while providing flexible, robust, and scalable ingest. Figure 2: Configuration and ingest throughput for each source, grouped by type Protect your sensitive data Privacy by design.
Cloud migration is the process of transferring some or all your data, software, and operations to a cloud-based computing environment that offers unlimited scale and high availability. Increased scalability. Improved performance and availability. The third big advantage of cloud migration is performance and availability.
Following FinOps practices, engineering, finance, and business teams take responsibility for their cloud usage, making data-driven spending decisions in a scalable and sustainable manner. Flexible pricing models that offer discounts based on commitment or availability can greatly reduce cloud waste. Suboptimal architecture design.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content