This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This year’s AWS re:Invent will showcase a suite of new AWS and Dynatrace integrations designed to enhance cloud performance, security, and automation. This integration simplifies the process of embedding Dynatrace full-stack observability directly into custom Amazon Machine Images (AMIs).
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
The newly introduced step-by-step guidance streamlines the process, while quick data flow validation accelerates the onboarding experience even for power users. Step-by-step setup The log ingestion wizard guides you through the prerequisites and provides ready-to-use command examples to start the installation process.
Business events: Delivering the best data It’s been two years since we introduced business events , a special class of events designed to support even the most demanding business use cases. Dynatrace OpenPipeline is a new stream processing technology that ingests and contextualizes data from any source.
A production bug is the worst; besides impacting customer experience, you need special access privileges, making the process far more time-consuming. It also makes the process risky as production servers might be more exposed, leading to the need for real-time production data. This cumbersome process should not be the norm.
Managing High Availability (HA) in your PostgreSQL hosting is very important to ensuring your database deployment clusters maintain exceptional uptime and strong operational performance so your data is always available to your application. Effective management of failover and switchover operations is crucial for high availability.
A Data Movement and Processing Platform @ Netflix By Bo Lei , Guilherme Pires , James Shao , Kasturi Chatterjee , Sujay Jain , Vlad Sydorenko Background Realtime processing technologies (A.K.A stream processing) is one of the key factors that enable Netflix to maintain its leading position in the competition of entertaining our users.
By leveraging Dynatrace observability on Red Hat OpenShift running on Linux, you can accelerate modernization to hybrid cloud and increase operational efficiencies with greater visibility across the full stack from hardware through application processes. Dynatrace is designed to scale easily across the entire Kubernetes stack.
Implementing clustering and quorum queues in RabbitMQ significantly improves load distribution and data redundancy, ensuring high availability and fault tolerance for messaging services. Classic queues can be used in clusters, emphasizing their behavior during node failures, particularly regarding durability and availability.
They offer a comprehensive end-to-end solution to these challenges, providing functionalities designed to enhance compliance and resilience in IT environments. Smartscape topology visualizes the relationships between applications, services, processes, hosts, and data centers, highlighting problems and vulnerabilities.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is Apache Kafka?
Dynatrace Managed is intrinsically highly available as it stores three copies of all events, user sessions, and metrics across its cluster nodes. Our Premium High Availability comes with the following features: Active-active deployment model for optimum hardware utilization. Dynatrace news. Minimized cross-data center network traffic.
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. Data is then dynamically routed into pipelines for further processing.
The system demands significant effort to design, manage, and maintain, especially as an organization’s needs evolve. Access policies for Dynatrace Grail™ data lakehouse are still available as service-related policies; they allow you to control access to the monitoring data on a per-data-source level, for example, logs and metrics.
Creating an ecosystem that facilitates data security and data privacy by design can be difficult, but it’s critical to securing information. When organizations focus on data privacy by design, they build security considerations into cloud systems upfront rather than as a bolt-on consideration.
” As in the case of regular SaaS services, software updates happen as soon as possible and are designed to go relatively unnoticed in the background. Therefore, regardless if you are a SaaS or Managed customer, we designed the OneAgent update experience to be smooth and automated following the release of each new version.
Kickstart your creation journey using ready-made dashboards and notebooks Creating dashboards and notebooks from scratch can take time, particularly when figuring out available data and how to best use it. Kickstarting the dashboard creation process is, however, just one advantage of ready-made dashboards.
Integration with existing systems and processes : Integration with existing IT infrastructure, observability solutions, and workflows often requires significant investment and customization. The certification results are now publicly available.
Building the dream package Observability for Developers, the newly introduced offering from Dynatrace, is designed to cater to developers’ specific needs and challenges. As every developer knows, logs are crucial for uncovering insights and detecting fundamental flaws, such as process crashes or exceptions.
Grafana Loki is a horizontally scalable, highly available log aggregation system. It is designed for simplicity and cost-efficiency. Logs can also be transformed appropriately for presentation, for example, or further pipeline processing. Loki can provide a comprehensive log journey.
As a result, requests are uniformly handled, and responses are processed cohesively. This data is processed from a real-time impressions stream into a Kafka queue, which our title health system regularly polls. Many of the metadata and assets involved in title setup have specific timelines for when they become available to members.
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. It’s architecture was specially designed to manage large-scale data warehouses and business intelligence workloads by giving you the ability to spread your data out across a multitude of servers. At a glance – TLDR.
To better guide the design and budgeting of future campaigns, we are developing an Incremental Return on Investment model. Ideally, we would have causal estimates from an A/B test to use for validation, but since that is not available, we use another causal inference design as one of our ensemble of validation approaches.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
By leveraging the Dynatrace Operator and Dynatrace capabilities on Red Hat OpenShift on IBM Power, customers can accelerate their modernization to hybrid cloud and increase operational efficiencies with greater visibility across the full stack from hardware through application processes.
In this hybrid world, IT and business processes often span across a blend of on-premises and SaaS systems, making standardization and automation necessary for efficiency. Enterprises seek solutions that enable these processes to interact across their entire system landscape without compromising security.
Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Using a low-code visual workflow approach, organizations can orchestrate key services, automate critical processes, and create new serverless applications.
Amazon’s new general-purpose Linux for AWS is designed to provide a secure, stable, and high-performance execution environment to develop and run cloud applications. This is done by detecting availability and performance problems in real time across an entire technology stack while presenting teams with answers — not alert storms.
DevOps is focused on optimizing software development and delivery, and SRE is focused on operations processes. DevOps is not a specific process, but rather a general collection of flexible software creation and delivery practices that looks to close the gap between software development and IT operations. DevOps as a philosophy.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data.
It should be open by design to accelerate innovation, enable powerful integration with other tools, and purposefully unify data and analytics. All innovations based on Grail are only available in Dynatrace SaaS environments. Grail-based innovations are, however, only available in Dynatrace SaaS environments.
Hence we built the data pipeline that can be used to extract the existing assets metadata and process it specifically to each new use case. This feature support required a significant update in the data table design (which includes new tables and updating existing table columns). N, first N rows are fetched from the table.
Event Prioritization Considering the use cases were wide ranging both in terms of their sources and their importance, we built segmentation into the event processing. We thus assigned a priority to each use case and sharded event traffic by routing to priority-specific queues and the corresponding event processing clusters.
In short, combining development and operations makes it possible for process to keep pace with progress. Consulting firm Deloitte notes that technology teams are now expected to deliver projects four times faster with the same budget, and most of that budget goes toward running the business — not process or software innovation.
Synthetic testing is an IT process that uses software to discover and diagnose performance issues with user journeys by simulating real-user activity. Types of synthetic testing There are three broad types of synthetic testing: availability, web performance, and transaction. First is a test of the home screen.
We must quickly surface the most stand-out highlights from the titles available on our service in the form of images and videos in the member experience. We implemented a batch processing system for users to submit their requests and wait for the system to generate the output. Processing took several hours to complete.
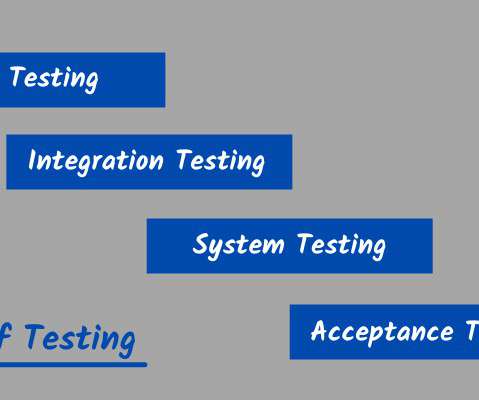
The goal of Levels of Testing is to make software testing more structured and efficient, as well as to make it easier to identify all available test cases and test scenarios at a given level. There are various steps in the SDLC paradigm, such as requirement gathering, analysis, coding, design, execution, testing, and deployment.
Flow Designer for more consistency in the delivery cycle. At this year’s Google Cloud Next conference, xMatters introduced Flow Designer , a visual designer that enables users to resolve issues without writing a single line of code. Flow Designer then connects the tools for you. How is this done? Slow microservices.
A data lakehouse addresses these limitations and introduces an entirely new architectural design. As a result, we created Grail with three different building blocks, each serving a special duty: Ingest and process. Ingest and process with Grail. It’s based on cloud-native architecture and built for the cloud. Retain data.
Flexible pricing models that offer discounts based on commitment or availability can greatly reduce cloud waste. This includes spot instances such as unused cloud capacity that’s available at a discounted price. Suboptimal architecture design. Poorly designed cloud solutions can become costly over time.
The whole experience is designed to fit into your individual data governance and compliance framework. With this three-layer design, you enjoy maximum flexibility in managing sensitive data points end-to-end. The selected rules can be configured for a whole environment or, more granularly, for specific process groups.
Dynatrace’s ability to ingest metrics from all 95 AWS services will be available within the next 60 days. Those in the left column are readily available now, with those in the right available soon. Available Now. Achieve full observability of all AWS services. Coming Soon. AWS AppSync. AWS CloudHSM. Amazon AppStream 2.0.
But there are other related components and processes (for example, cloud provider infrastructure) that can cause problems in applications running on Kubernetes. And because Dynatrace can consume CloudWatch metrics, almost all your AWS usage information is available to you within Dynatrace.
Across the globe, privacy laws grant individuals data subject rights, such as the right to access and delete personal data processed about them. 2] — Nader Henein, VP Analyst, Gartner The Privacy Rights app is designed to streamline this process in Dynatrace.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content