This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As a Software Engineer, the mind is trained to seek optimizations in every aspect of development and ooze out every bit of available CPU Resource to deliver a performing application. This begins not only in designing the algorithm or coming out with efficient and robust architecture but right onto the choice of programming language.
The log ingestion wizard offers support for all log ingestion methods available in Dynatrace Hub Get started with Logs: The OneAgent advantage For most scenarios, Dynatrace OneAgent is your best friend for getting started with Dynatrace log ingestion. Different log ingestion methods are available to address various needs.
Managing High Availability (HA) in your PostgreSQL hosting is very important to ensuring your database deployment clusters maintain exceptional uptime and strong operational performance so your data is always available to your application. Effective management of failover and switchover operations is crucial for high availability.
Creating an ecosystem that facilitates data security and data privacy by design can be difficult, but it’s critical to securing information. When organizations focus on data privacy by design, they build security considerations into cloud systems upfront rather than as a bolt-on consideration. API access management.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Its design prioritizes high availability and efficient data transfer with minimal overhead, making it a practical choice for handling real-time data pipelines and distributed event processing.
Data storage and distribution through HollowFeeds Netflix Hollow is an Open Source java library and toolset for disseminating in-memory datasets from a single producer to many consumers for high performance read-only access. Given the shape of our data, hollow feeds are an excellent strategy to distribute the data across our serviceboxes.
are technologically very different, Python and JMX extensions designed for Extension Framework 1.0 focused on technology coverage, building on the flexibility of JMX for Java and Python-based coded extensions for everything else. available, and more are in the pipeline. We’ve added Python support to Extensions 2.0, Extensions 2.0
Regarding contemporary software architecture, distributed systems have been widely recognized for quite some time as the foundation for applications with high availability, scalability, and reliability goals. Spring Boot Overview One of the most popular Java EE frameworks for creating apps is Spring.
Making Google’s CalDAV and CardDAV APIs available for everyone ( Google Developers Blog). Pandora launches new HTML5 site for TVs and gaming consoles, available now on PS3 and Xbox 360 ( The Next Web). Simpler UI Testing with CasperJS ( Architects Zone – Architectural Design Patterns & Best Practices). Java EE 7 is Final.
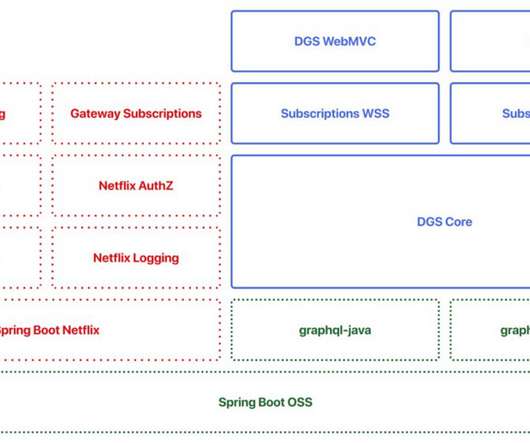
By open-sourcing the project, we hope to contribute to the Java and GraphQL communities and learn from and collaborate with everyone who will be using the framework to make it even better in the future. The transition to the new federated architecture meant that many of our backend teams needed to adopt GraphQL in our Java ecosystem.
Code-level vulnerability detection provides deep insight into each detected vulnerability: Location of the vulnerability in your code Affected processes Context and details based on the vulnerability type Potential impact assessment based on your environment topology Code-level vulnerability detection is currently available for Java processes.
Learning Resources: Are there tutorials, guides, and comprehensive documentation available for the tool? Cross-Platform Compatibility: Is the tool available on multiple operating systems (Windows, macOS, Linux)? Lacks some advanced coding and debugging tools available in other products. Pricing: Free: Only 14-day trial.
For years, the debate has raged on regarding which programming language is better, Java or Scala. While some argue that just because Java is older it is better, others believe Scala is better for a variety of reasons. In essence, Java is classified as an object oriented programming language. The Size and Quality of the Code.
Java was initially designed as a safe, managed environment. Nevertheless, Java HotSpot VM contains a “backdoor” that provides a number of low-level operations to manipulate memory and threads directly. In general, such functionality is safely available via NIO’s off-heap bufferes. sizeof() Function.
Automation testing tools are designed to execute automated test scripts to validate software requirements, both functional and non-functional. Consider your company's goals, available resources, and growth potential to select the tool that best suits your needs. Ten Different Testing Tools for 2024 1.
Do you provide support for application technologies from ABAP through Java to HANA ? The Dynatrace software intelligence platform is designed to address all enterprise application technologies and delivery models. Dynatrace is available for SAP Commerce Cloud (C/4HANA ) and for SAP Cloud Platform (SCP).
” Meaning, you don’t need to worry about OneAgent updates because they’re performed automatically, safely, and promptly as soon as new versions are available (no manual effort required). Please note that the OneAgent update process may require that the injected OneAgent modules (for Java,Net, Apache, etc.)
At Netflix, we periodically reevaluate our workloads to optimize utilization of available capacity. We decided to move one of our Java microservices?—?let’s In this blogpost we describe one such problem and the tools we used to solve it. The problem It started off as a routine migration. let’s call it GS2?—?to
Listen, learn, improve, and repeat The latest update to the Citrix monitoring extension is now available. This update improves the ability to observe Citrix users and delivery agents within a Citrix environment using the Citrix SDK, which is designed specifically for Citrix admins. Now, it’s available to all customers.
This gives us access to Netflix’s Java ecosystem, while also giving us the robust language features such as coroutines for efficient parallel fetches, and an expressive type system with null safety. Our goal was to design a GraphQL schema that was reflective of the domain itself, not the database model.
Due to the widespread adoption and rich ecosystem of available PHP libraries, all types of security vulnerabilities can be found in PHP applications. Many application security products were designed before the rise of DevSecOps, containers, Kubernetes, and multicloud environments and so can’t keep up with rapid changes in these environments.
Advent Calendars For Web Designers And Developers (December 2021 Edition). Advent Calendars For Web Designers And Developers (December 2021 Edition). It doesn’t really matter if you’re a front-end dev, UX designer or content strategist, we’re certain you’ll find at least something to inspire you for the upcoming year.
This was all a spare time project, as my day job at Netflix at that time was as a director level manager of a team working on personalization code in Java, and it wasnt my job to write the codemyself. One of the Java engineers on my teamJian Wujoined me to help figure out the API. The code is still up on github.
For example, the number of threads of your process is already available in Dynatrace in most cases, so there is no need to spend the extra effort. With insights from Dynatrace into network latency and utilization of your cloud resources, you can design your scaling mechanisms and save on costly CPU hours.
Today we’re proud to announce the new Dynatrace Operator, designed from the ground up to handle the lifecycle of OneAgent, Kubernetes API monitoring, OneAgent traffic routing, and all future containerized componentry such as the forthcoming extension framework. Other Dynatrace components, like ActiveGate, are deployed separately.
Our first version is available to customers in the Intel Tiber AI Cloud as a preview for the Intel Data Center GPU Max Series (previously called Ponte Vecchio). It's designed to be easy and low-overhead , just like a CPU profiler. Here is an example: Simple example: SYCL matrix multiply microbenchmark (Click for interactive SVG.)
This feature support required a significant update in the data table design (which includes new tables and updating existing table columns). Data Sharding strategy in elasticsearch is updated to provide low search latency (as described in blog post) Design of new Cassandra reverse indices to support different sets of queries.
All data should be also available for offline analytics in Hive/Iceberg. Unlike Java, we support multiple inheritance as well. Data ingestions from the ML data pipelines are generally in bulk specifically when a new algorithm is designed and annotations are generated for the full catalog. Annotations can be versioned.
service with a composable JavaScript API that made downstream microservice calls, replacing the old Java API. Java…Script? As Android developers, we’ve come to rely on the safety of a strongly typed language like Kotlin, maybe with a side of Java. ecosystem and the rich selection of npm packages available. It was a Node.js
This approach to IAC uses object-oriented programming languages, such as Java or C++. To maintain visibility into how infrastructure affects application availability, performance, and security, it’s critical for developers to incorporate observability throughout the development lifecycle.
Before jumping into either of those scenarios, have a look at what Strategic Domain-Driven Design can offer you. remember, it’s not a waterfall project Tools and Techniques There are plentiful tools and techniques available to you in your modernisation initiative. Architecture modernisation caveats?—?remember, You can do either first.
The Azure Well-Architected Framework is a set of guiding tenets organizations can use to evaluate architecture and implement designs that will scale over time. Design efficient use of your computing resources as demand changes and technologies evolves. Design applications to recover from errors gracefully. Reliability.
We’ve completely re-designed the internals of the OneAgent installer for Windows. The Oracle other processes group will keep the pre-rework identifier of the Oracle group, so all historic data will be available under the entry. with Java 6. Going forward, only the combination with Java 7 or higher will be supported.
A typical design pattern is the use of a semantic search over a domain-specific knowledge base, like internal documentation, to provide the required context in the prompt. OneAgent can automatically monitor all C#,NET, Java, Go, and NodeJS bindings. Our example dashboard below visualizes OpenAI token consumption.
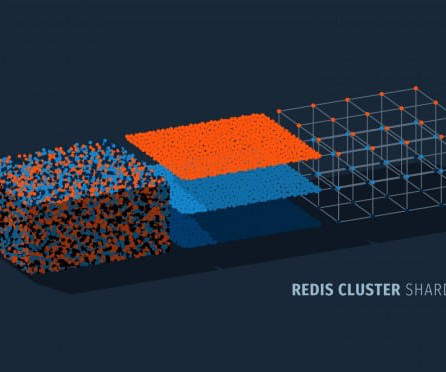
Redis Cluster is the native sharding implementation available within Redis that allows you to automatically distribute your data across multiple nodes without having to rely on external tools and utilities. High Availability. It also implements a Raft -like consensus approach to ensure availability of the entire cluster.
Sample GraphQL Schema Once entities like the above are available in the graph, it’s very common for folks to want to query for a particular entity based on attributes of related entities, e.g. give me all movies that are currently in photography with Ryan Reynolds as an actor. This was done using graphql-java.
Today we have a wealth of tools, both OSS and commercial, all designed for cloud-native environments. Since there were no existing solutions available, we needed to build them ourselves. To improve availability, we designed systems where components could fail separately and avoid single points of failure.
A new generation of automated solutions — designed to provide end-to-end observability of assets, applications, and performance across legacy and cloud systems — make that job easier, says Federal Chief Technology Officer Willie Hicks at Dynatrace. But these systems must always be on and highly available. What’s the root cause?
“All configuration and pipeline” definition itself is designed to live in source control. While not intended to be a step-by-step tutorial around building a Concourse pipeline, below is an example pipeline that unit tests, builds, and deploys a sample Java application to Cloud Foundry.
Meson was based on a single leader architecture with high availability. Maestro’s scalable foreach design to support super large iterations With this design, foreach pattern supports sequential loop and nested loop with high scalability. Users can write the code in Java syntax as the parameter definition.
When it comes to enterprise-level databases, there are several options available in the market, but PostgreSQL stands out as one of the most popular and reliable choices. This makes it an excellent choice for mission-critical applications that require high availability. Download Percona Distribution for PostgreSQL Today!
With a few lines of code, developers can easily integrate existing web services with Alexa or, in just a few hours, they can build entirely new experiences designed around voice. Note that the Lambda free tier does not automatically expire, but is available indefinitely. The first one million requests each month are free.
It offers automatic data sharding, master-replica configurations for high availability, and a scalable and flexible architecture to maintain consistent performance. Sharding in Redis involves dividing data across multiple machines to enhance scalability and maintain availability. What is Redis Sharding?
Join Etleap , an Amazon Redshift ETL tool to learn the latest trends in designing a modern analytics infrastructure. FlexBalancer makes it easy to manage traffic between multiple CDN providers, API’s, Databases or any custom endpoint helping you achieve better performance, ensure the availability of services and reduce vendor costs.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content