This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
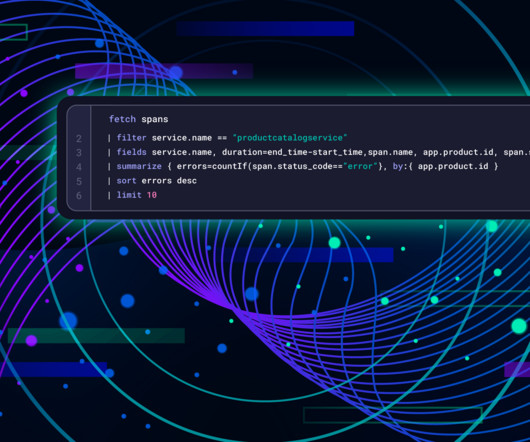
In this blog post, we’ll walk you through a hands-on demo that showcases how the Distributed Tracing app transforms raw OpenTelemetry data into actionable insights Set up the Demo To run this demo yourself, you’ll need the following: A Dynatrace tenant. If you don’t have one, you can use a trial account.
The OpenTelemetry community created its demo application, Astronomy Shop, to help developers test the value of OpenTelemetry and the backends they send their data to. Overview of the OpenTelemetry demo app dashboard Set up the demo To run this demo yourself, youll need the following: A Dynatrace tenant.
Histograms are commonly used to define and monitor service-level objectives (SLOs). This feature, available by default for OTel-instrumented services, allows users a standard way to measure and compare response times across different services consistently. Histograms also enhance the self-monitoring capabilities of the Collector.
It gives you visibility into which components are monitored and which are not and helps automate time-consuming compliance configuration checks. Discovery & Coverage helps prevent unexpected outages by detecting and remediating monitoring coverage gaps across your entire enterprise.
In this OpenTelemetry demo series, we’ll take an in-depth look at how to use OpenTelemetry to add observability to a distributed web application that originally didn’t know anything about tracing, telemetry, or observability. However, as software workloads have become more distributed, relying on logs alone is proving inadequate.
Synthetic monitoring can help to confirm your applications are performing as intended and, in the event they’re not, help you quickly figure out what’s going on. Here’s a look at what synthetic monitoring is, how it’s different from real-user monitoring, and why it matters to your business.
Dynatrace Dashboards provide a clear view of the health of the OpenTelemetry Demo application by utilizing data from the OpenTelemetry collector. With these dashboards, you can monitor your application’s usage and performance and identify potential issues like increasing failure rates. The file can be downloaded here.
In the first part of this three-part series, The road to observability with OpenTelemetry demo part 1: Identifying metrics and traces with OpenTelemetry , we talked about observability and how OpenTelemetry works to instrument applications across different languages and platforms. heapUsed); }); What to trace?
For that, we focused on OpenTelemetry as the underlying technology and showed how you can use the available SDKs and libraries to instrument applications across different languages and platforms. We also introduced our demo app and explained how to define the metrics and traces it uses.
This trend is prompting advances in both observability and monitoring. But exactly what are the differences between observability vs. monitoring? Monitoring and observability provide a two-pronged approach. To get a better understanding of observability vs monitoring, we’ll explore the differences between the two.
Infrastructure monitoring is the process of collecting critical data about your IT environment, including information about availability, performance and resource efficiency. Many organizations respond by adding a proliferation of infrastructure monitoring tools, which in many cases, just adds to the noise. Dynatrace news.
Monitoring Kubernetes is an important aspect of Day 2 o perations and is often perceived as a significant challenge. A container (or a pod) running on a node may eat up all the available CPU or memory and affect all other pods on the node, degrading performance (or worse) and preventing any new workload to be scheduled on the node.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. Dynatrace combines Synthetic Monitoring with automatic release validation for continuous quality assurance across the SDLC.
Most business processes are not monitored. Business processes can be quite complex, often including conditional branches and loops; many business process monitoring initiatives are abandoned or simplified after attempting to map the process flow. First and foremost, it’s a data problem.
As part of the Platform Extensions team, I’m one of those responsible for services that include the Dynatrace OneAgent SDKs, which are libraries that allow us to extend end-to-end visibility for technologies and frameworks for which there is no code module available yet. Autodynatrace is a python (2.7+, 3.4+) module that solves this problem.
Many of our customers—the world’s largest enterprises—have embraced the Dynatrace SaaS approach to monitoring, which provides critical business insights powered by AI and automation for globally-distributed, heterogeneous IT landscapes. New self-monitoring environment provides out-of-the-box insights and custom alerting.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. What is log monitoring? Log monitoring is a process by which developers and administrators continuously observe logs as they’re being recorded.
Digital experience monitoring (DEM) allows an organization to optimize customer experiences by taking into account the context surrounding digital experience metrics. What is digital experience monitoring? Primary digital experience monitoring tools.
Despite its benefits, serverless computing introduces additional monitoring challenges for developers and IT Operations, particularly in understanding dependencies and identifying issues in the end-to-end traces that flow through a complex mix of dynamic and hybrid on-premise/cloud environments. Azure Functions in a nutshell. So stay tuned!
As I highlight the keptn integration with Dynatrace during my demos, I have rolled out a Dynatrace OneAgent using the OneAgent Operator into my GKE cluster. In my case, both prometheus.knative-monitoring pods jumped in Process CPU and I/O request bytes. Alerting on high CPU is not special – but – I am really only running a small node.js
As Dynatrace is a leader in Cloud monitoring, we have architected our Software Intelligence Platform specifically to complement Kubernetes by providing extensive functionality to tame the complexities and prevent performance issues that can occur across the development and deployment cycles. Don’t underestimate complexity.
Despite its benefits, serverless computing introduces additional monitoring challenges for developers and IT Operations, particularly in understanding dependencies and identifying issues in the end-to-end traces that flow through a complex mix of dynamic and hybrid on-premise/cloud environments. Azure Functions in a nutshell. So stay tuned!
I’m willing to bet you still monitor TTFB , even though you know your customers will have no concept of a first byte whatsoever. If you aren’t (able to) monitoring custom metrics around your application’s interactivity, hydration state, etc., before the app’s key functionality is available, with almost half waiting over 3.5s!
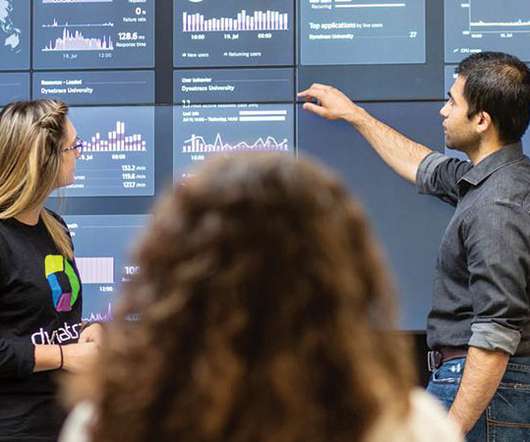
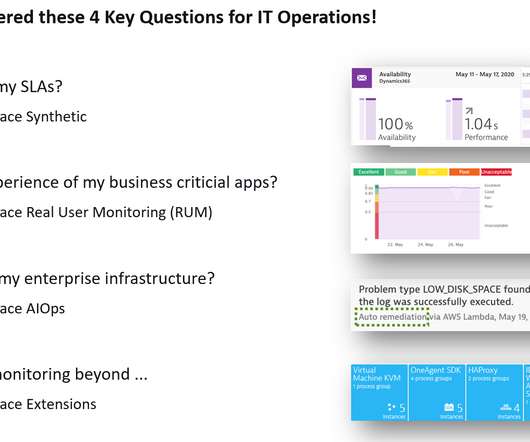
We came up with list of four key questions, then answered and demoed in our recent webinar. Dynatrace Synthetic allows you check the availability and performance for your business-critical applications. Stephan demoed how avodaq internally leverages Dynatrace Synthetic.
A Kubernetes-centric Internal Development Platform (IDP) enables platform engineering teams to provide self-service capabilities and features to their DevSecOps teams who need resilient, available, and secure infrastructure to build and deploy business-critical customer applications. All important health signals are highlighted.
Logs provide answers, but monitoring is a challenge Manual tagging is error-prone Making sure your required logs are monitored is a task distributed between the data owner and the monitoring administrator. Often, it comes down to provisioning YAML configuration files and listing the files or log sources required for monitoring.
The Clouds app provides a view of all available cloud-native services. Logs in context, along with other details, are instantly available after selecting a resource. The reasons are easy to find, looking at the latest improvements that went live along with the general availability of the Logs app.
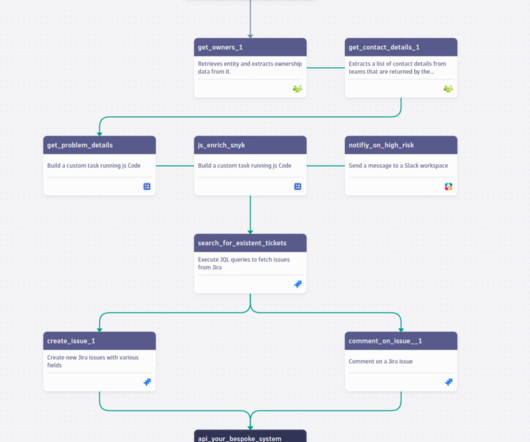
Keeping ownership teams and their properties up to date is essential, as is having the right contact information available when needed. Besides supporting UI and API input for ownership teams, a dedicated workflow action for importing, storing, and updating ownership teams is available. Contact us to schedule a demo.
To address this need, Dynatrace now provides automation for DevSecOps collaboration that associates ownership information with monitored services to further minimize mean-time-to-restore (MTTR). Associating ownership-team details with monitored services is flexible. Associated ownership information is available on each entity page.
“Digital workers are now demanding IT support to be more proactive,” is a quote from last year’s Gartner Survey Understandably, a higher number of log sources and exponentially more log lines would overwhelm any DevOps, SRE, or Software Developer working with traditional log monitoring solutions.
Dynatrace broadens its Digital Experience Monitoring capabilities by adding Flutter support. With the release of Flutter support in Dynatrace, we’re filling a gap that no other solution in the market has addressed, enabling you to leverage the full power of Dynatrace Digital Experience Monitoring for Flutter apps.
As such, we recently opened up our platform for metric ingestion and log monitoring and built integrations for key formats in those spaces. Say you’re running the Online Boutique , a cloud-native microservices demo application, that allows users to browse items, add them to a shopping cart, and purchase them. Detailed use case.
In addition to automatic full-stack monitoring, Dynatrace provides comprehensive support for a wide range of AWS services. Achieving this designation differentiates Dynatrace as an AWS Advanced Technology Partner with a product that is integrated with Amazon RDS and is generally available and fully supported. Next steps.
Kubernetes (k8s) provides basic monitoring through the Kubernetes API and you can find instructions like Top 9 Open Source Tools for Monitoring Kubernetes as a “do it yourself guide”. End-user monitoring. Dynatrace news. For EKS – Amazon’s Kubernetes Service – you can get a preview of CloudWatch Container Insights.
With Dynatrace, teams can seamlessly monitor the entire system, including network switches, database storage, and third-party dependencies. Impact of fewer resources, for example, CPU and disk, available to different services and applications. The problems that take maximum time to resolve – lowest MTTR.
Real-time monitoring with out-of-the-box features Real-time data and monitoring are crucial for maintaining situational awareness of IT environment stability and performance, especially during a crisis. They also enable companies to measure the effectiveness of their remediation activities to ensure that recoveries proceed as expected.
While logging is the act of recording logs, organizations extract actionable insights from these logs with log monitoring, log analytics, and log management. Comparing log monitoring, log analytics, and log management. Log monitoring enables the collection of log data, and log analysis promotes intelligent, data-driven decision making.
Organizations are constantly being measured against the best available digital experiences — coming from Google, Amazon, Facebook, and other industry leaders. Some of the factors that affect user experience include: Availability : Is the touchpoint available when the user wants to use it? What is digital experience monitoring?
During the webinar, Peter Vinh highlighted a crucial point for partners to convey: the latest innovations on the Dynatrace platform, including Grail, Davis CoPilot™ , OpenPipeline™️ , and Workflows, are exclusively available to SaaS customers. While the process may seem daunting, the tooling that is now available makes it much easier.
You took advantage of the launch of AutomationEngine , configured ownership information for all the monitored entities in your IT landscape, and set up workflows that automatically create tickets and route them to the responsible teams when security vulnerabilities are detected. But this is not the case for you, thankfully.
The airline : My preferences for a recent long-haul flight included price and the availability of aisle seats. How well do the IT departments for each of these companies monitor critical user journeys and business transactions? Based on my experience, here are my guesses: The airline IT team does not monitor user journeys.
In 2015, the Spring folks already regarded Dynatrace as the gold standard for performance monitoring. We’ll demonstrate this with a demo Spring application, which uses the Spring Web and Dynatrace Micrometer registry, as shown below. Auto-enrichment is also available in cases where OneAgent is unavailable or unnecessary.
Every time the trigger executes, the function runs on an available resource. Serverless vendors make resources available exactly when you need them. Monitoring serverless applications. Serverless application providers do provide basic monitoring and insights, but the features are limited.
For the sessions, each student needed to have their own Dynatrace SaaS tenant to monitor and perform the hands-on exercises. In the past, setting up all the hosts, clusters, and demo applications was a manual process that was very time consuming and error-prone. Monitoring. Automation. Dynatrace out-of-the-box AWS dashboard.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content