This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. While the SLO management web UI and API are already available, the dashboard tile will be released within the next weeks.
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Combined with Dynatrace OneAgent ® , you gain a precise view of the status of your systems at a glance.
For years, enterprises managed observability data on a team-by-team basis , using a combination of ticketing systems and configuration management tools. The application consists of several microservices that are available as pod-backed services. Information about each of these topics will be available in upcoming announcements.
Analytics Engineers deliver these insights by establishing deep business and product partnerships; translating business challenges into solutions that unblock critical decisions; and designing, building, and maintaining end-to-end analytical systems. DJ acts as a central store where metric definitions can live and evolve.
Messaging systems can significantly improve the reliability, performance, and scalability of the communication processes between applications and services. In serverless and microservices architectures, messaging systems are often used to build asynchronous service-to-service communication. Dynatrace news. This is great!
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
Journald provides unified structured logging for systems, services, and applications, eliminating the need for custom parsing for severity or details. System health, performance troubleshooting, and debugging situations no longer require manual correlation of logs across multiple disconnected tools or servers.
Stranger Things imagery showcasing the inspiration for the Hawkins Design System by Hawkins team member Joshua Godi ; with art contributions by Wiki Chaves Hawkins may be the name of a fictional town in Indiana, most widely known as the backdrop for one of Netflix’s most popular TV series “Stranger Things,” but the name is so much more.
As file sizes grow and workflows become more complex, these issues are magnified, leading to inefficiencies that slow down post-production and reduce the available time spent on creativework. Depending on the market, or production budget, cutting-edge technology might not be available or affordable. So what isit?
Many of these projects are under constant development by dedicated teams with their own business goals and development best practices, such as the system that supports our content decision makers , or the system that ranks which language subtitles are most valuable for a specific piece ofcontent. cluster=sandbox, workflow.id=demo.branch_demox.EXP_01.training
As a basis for that discussion, first some definitions: Dependability The degree to which a product or service can be relied upon. Availability and Reliability are forms of dependability. Availability The degree to which a product or service is available for use when required. Availability, reliability, and state.
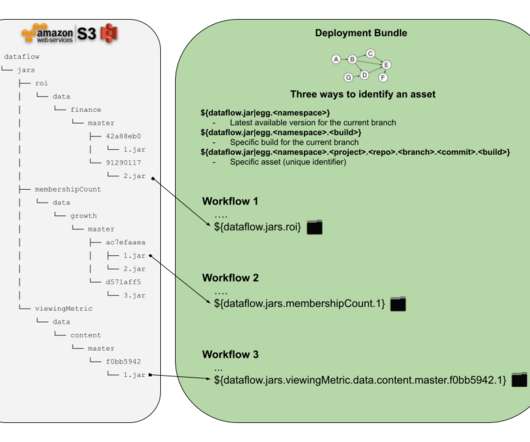
Thanks to the Netflix internal lineage system (built by Girish Lingappa ) Dataflow migration can then help you identify downstream usage of the table in question. Workflow Definitions Below you can see a typical file structure of a sample workflow package written in SparkSQL. ??? backfill.sch.yaml ??? daily.sch.yaml ???
Feature flag solutions currently use proprietary SDKs with frameworks, definitions, and data/event types that are unique to their platforms. The specification focuses primarily on feature flag evaluation in application code, leaving the definition and management of feature flags up to the feature flag management system.
Availability guarantee of 99.95%/month for customers with an active Enterprise Success and Support subscription. Enhanced uptime measurement Our new SLA is tailored to reflect our current product offering and includes broad coverage of product functionality in the availabilitydefinitions.
These are all interesting metrics from marketing point of view, and also highly interesting to you as they allow you to engage with the teams that are driving the traffic against your IT-system. In the next step change, the UTM campaign parameter to also be a user action property by editing the definition as shown on the screenshot below.
Complex IT systems make it possible to buy your favorite pair of jeans online, pay your bills, or help you navigate. These systems produce an unimaginably huge amount of data. All the data bound to hosts is analyzed by the Davis AI causation engine and made available on custom dashboards and events pages. Dynatrace news.
This article gives an overview of the system. Data Mesh Overview A New Definition Of Data Mesh Previously, we defined Data Mesh as a fully managed, streaming data pipeline product used for enabling Change Data Capture (CDC) use cases. As of now, we still have several specialized internal systems serving their own use cases.
We recently extended the pre-shipped code-level API definitions to group logical parts of our code so they’re consistently highlighted in all code-level views. Another benefit of defining custom APIs is that the memory allocation and surviving object metrics are split by each custom API definition.
see “data pipeline” Intro The problem of managing scheduled workflows and their assets is as old as the use of cron daemon in early Unix operating systems. The design of a cron job is simple, you take some system command, you pick the schedule to run it on and you are done. Manually constructed continuous delivery system.
The system could work efficiently with a specific number of concurrent users; however, it may get dysfunctional with extra loads during peak traffic. For example, the gaming app has to present definite actions to bring the right experience. An app is built with some expectations and is supposed to provide firm results.
And we definitely couldn’t replay test non-functional requirements like caching and logging user interaction. The AB experiment results hinted that GraphQL’s correctness was not up to par with the legacy system. The Replay Testing framework leverages the @override directive available in GraphQL Federation. How does it work?
Adoption As of writing this blog, Conductor orchestrates 600+ workflow definitions owned by 50+ teams across Netflix. External Payload Storage External payload storage was implemented to prevent the usage of Conductor as a data persistence system and to reduce the pressure on its backend datastore.
Kubernetes can be a confounding platform for system architects. Extensible admission lets us change the definition of a pod after the pod is authorized but before it’s scheduled to run. If your custom resource-definition targets the pod’s namespace, OneAgent will be injected before it starts. Dynatrace news.
Due to its popularity, the number of workflows managed by the system has grown exponentially. The scheduler on-call has to closely monitor the system during non-business hours. Meson was based on a single leader architecture with high availability. With the high growth of workflows in the past few years?—?increasing
This is not a general rule, but as databases are responsible for a core layer of any IT system – data storage and processing — they require reliability. Availability solutions – Advanced backups, including physical backups and point-in-time recovery that are not available to MongoDB Community Edition.
Monitoring , by textbook definition, is the process of collecting, analyzing, and using information to track a program’s progress toward reaching its objectives and to guide management decisions. Logging provides additional data but is typically viewed in isolation of a broader system context.
This information is curated from the expert microservices material available on our online learning platform. Sam Newman provides a succinct definition of microservices in Building Microservices : “Microservices are small, autonomous services that work together.”. Microservices are an alternative to monolithic systems.
As IT infrastructure has become increasingly distributed and complex, organizations face the challenge of aligning business objectives and end-user experience with the availability and performance of the IT infrastructure. Dealing with an unstable website is stress that users don’t need, and definitely don’t want.
This was one of the most demanded features, and with the introduction of security policies, this control mechanism is finally available. Let’s take a look at how the new permission system is leveraged within Settings 2.0 As of today, many settings are already available to be referenced in security policies. Policy format.
The flip side of speeding up delivery, however, is that each software release comes with the risk of impacting your goals of availability, performance, or any business KPIs. Typical Dynatrace use cases cover SLOs for service availability, web application performance, mobile application availability, and synthetic availability.
The fact is, Reliability and Resiliency must be rooted in the architecture of a distributed system. The subject line said: “Success Story: Major Issue in single AWS Frankfurt Availability Zone!” The problem started at 1:24PM PDT, with the services starting to become available again about 3 hours later. Ready to learn more?
From the moment a Netflix film or series is pitched and long before it becomes available on Netflix, it goes through many phases. Data connectivity across Netflix Studio and availability of Operational Reporting tools also incentivizes studio users to avoid forming data silos.
Building effective and reliable systems is only possible with automation, which, in the past, proved difficult due to the following issues: Complexity of systems: The complexity of modern systems makes it difficult to gather all the necessary information to automate decision-making.
In Part I , we introduced a High Availability (HA) framework for MySQL hosting and discussed various components and their functionality. Semisynchronous replication, which is natively available in MySQL, helps the HA framework to ensure data consistency and redundancy for committed transactions. rpl_semi_sync_master_timeout.
This architecture offers rich data management and analytics features (taken from the data warehouse model) on top of low-cost cloud storage systems (which are used by data lakes). Data is available in real time without requiring indexing by our powerful Dynatrace Query Language. This scenario is a thing of the past.
As we look at today’s applications, microservices, and DevOps teams, we see leaders are tasked with supporting complex distributed applications using new technologies spread across systems in multiple locations. For most systems, an optimum MTTR could be less than one hour while others have an MTTR of less than one day.
Integration with Red Hat Event-Driven-Ansible will also leverage Red Hat’s flexible rulebook system to map event data, such as problem categories or vulnerability identification, to the correct job template. Context-rich tickets can be created in systems like Jira or ServiceNow for traceability and compliance. Got any more questions?
Anyone who’s concerned with developing, delivering, and operating software knows the importance of making software and the systems it runs on observable. With observability, you can get a better understanding of how your systems behave and what they do, especially in case of errors. Why should I adopt observability?
Migrating Critical Traffic At Scale with No Downtime — Part 2 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Picture yourself enthralled by the latest episode of your beloved Netflix series, delighting in an uninterrupted, high-definition streaming experience. This is where large-scale system migrations come into play.
Collector Custom Resource A custom resource (CR) represents a customization of a specific Kubernetes installation that isnt necessarily available in a default Kubernetes installation; CRs help make Kubernetes more modular. There are two versions available: v1alpha1 : apiVersion: opentelemetry.io/v1alpha1 is required.
Running metric queries on a subset of entities for live monitoring and system overviews. The Metrics API v2 is the first v2 API available in Dynatrace. Metrics API v2 is designed in a RESTful way to allow you to discover which metrics are available, retrieve metadata, and to execute sophisticated time series queries.
As a Software Engineer, the mind is trained to seek optimizations in every aspect of development and ooze out every bit of available CPU Resource to deliver a performing application. They still will win for mission-critical or real-time systems, which need performance over these parameters.
These metrics help to keep a network system up and running?, All these definitions are distinct and important. Containment: Implements actions to safeguard affected systems, resolves incidents quickly and escalates an event to other teams when necessary. This does not include lag time in the alert system.
The CSI pod is mounted to application pods using an overlay file system. The CSI pod offers a prepared file system, mounted automatically, and includes unzipped agent binaries to every application pod. kubectl label namespaces [your-namespace] monitoring=Dynatrace Note: GKE Autopilot support is available as of Dynatrace Operator 0.12
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content