This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Are all network devices up and running, and is the network providing reliable and swift access to your systems?
Quick and easy network infrastructure monitoring. All of this convenient visibility is available with just a few clicks. Begin network monitoring by simply deploying an extension with just a few clicks. Tired of constantly switching between all your monitoring tools? Start monitoring in minutes.
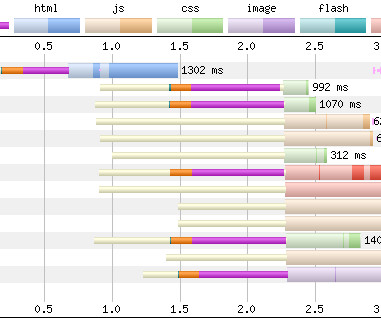
In this post I want to look at how CSS can prove to be a substantial bottleneck on the network (both in itself and for other resources) and how we can mitigate it, thus shortening the Critical Path and reducing our time to Start Render. Employ Critical CSS. The same waterfall occurs in Opera and Safari.).
For example, the gaming app has to present definite actions to bring the right experience. Performance testing does not essentially display imperfections with an app, yet it needs to ensure that the app function as expected despite the bandwidth availability, network fluctuations, or traffic overload.
IT infrastructure is the heart of your digital business and connects every area – physical and virtual servers, storage, databases, networks, cloud services. Simply put, infrastructure monitoring is the oxygen to your infrastructure, collecting all the data for a complete picture of availability, performance, and resource efficiency.
We recently extended the pre-shipped code-level API definitions to group logical parts of our code so they’re consistently highlighted in all code-level views. Another benefit of defining custom APIs is that the memory allocation and surviving object metrics are split by each custom API definition.
Always force HTTPS when it’s available. However, we can also see that the browser didn’t begin network negotiation until closer to the 1.5-second Connection overhead isn’t huge , but too many preconnect s that either a) aren’t critical, or b) don’t get used at all, is definitely wasteful. href=//… ). What went wrong?!
In Part I , we introduced a High Availability (HA) framework for MySQL hosting and discussed various components and their functionality. Semisynchronous replication, which is natively available in MySQL, helps the HA framework to ensure data consistency and redundancy for committed transactions. rpl_semi_sync_master_timeout.
These metrics help to keep a network system up and running?, All these definitions are distinct and important. If one system has an MTTR of 24 hours and another has an MTTR of three days with equal time between failures, the first system is more valuable because its availability is higher. So, what is MTTR?
This blog post focuses on the definition of events that are triggered by measurements (i.e, Examples here could be, “High network activity” or “CPU saturation.” The following table summarizes the semantics of all available event severities that trigger problems and are analyzed by Davis: Severity.
And we definitely couldn’t replay test non-functional requirements like caching and logging user interaction. The Replay Testing framework leverages the @override directive available in GraphQL Federation. We knew we could test the same query with the same inputs and consistently expect the same results. How does it work?
Modern applications—enterprise and consumer—increasingly depend on third-party services to create a fast, seamless, and highly available experience for the end-user. If this were the case, IT teams would need to plan to migrate to the newest available version of that API. Dynatrace news. So what is API monitoring?
Metrics provide a unified and standardized definition to numerical data points over a period of time (for example, network throughput, CPU usage, number of active users, and error rates), whereas logs address traditional logging and allow you to handle logging information in an aggregated fashion.
The Operator also manages configurations across a fleet of Collectors using Open Agent Management Protocol (OpAMP), which is a network protocol for remotely managing large fleets of data collection agents. There are two versions available: v1alpha1 : apiVersion: opentelemetry.io/v1alpha1 spec.containers[*].name}'
Adoption As of writing this blog, Conductor orchestrates 600+ workflow definitions owned by 50+ teams across Netflix. The task definition parameter rateLimitFrequencyInSeconds sets the duration window, while rateLimitPerFrequency defines the number of tasks that can be scheduled in a duration window.
Lack of data: In many cases, available data may not be enough to make informed decisions due to data silos, distribution, or negligence. By shifting your automation configuration left, Monaco moves automation definition closer to not only your source code, but also your testing, observability, security, and remediation capabilities.
While DevOps is often referred to as “agile operations,” the widely quoted definition from Jez Humble, co-author of The DevOps Handbook, calls it “a cross-disciplinary community of practice dedicated to the study of building, evolving, and operating rapidly-changing resilient systems at scale.” App availability.
For example, the number of threads of your process is already available in Dynatrace in most cases, so there is no need to spend the extra effort. With insights from Dynatrace into network latency and utilization of your cloud resources, you can design your scaling mechanisms and save on costly CPU hours.
A cluster is just a pool of compute resources available to a customer’s applications. The pool of resources, at this time, is the CPU, memory, and networking resources of Amazon EC2 instances as partitioned by containers. The agent is written in Go, has a minimal footprint, and is available on GitHub under an Apache license.
Content, genre and languages Instead of augmenting or synthesizing training data, we sample the large scale data available in the Netflix catalog with noisy labels. One of the fundamental issues encountered during the annotation of our manually-labeled TVSM-test set, was the definition of music and speech.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. While many databases offer server-side compression, handling compression on the client side reduces expensive server CPU usage, network bandwidth, and disk I/O.
The shortest possible time to value offered by Dynatrace is one of the most important reasons that our customers select Dynatrace over other monitoring solutions available on the market. The Ansible OneAgent collection is available from two primary sources: Directly from Dynatrace. Dynatrace news. From the Ansible Galaxy repository.
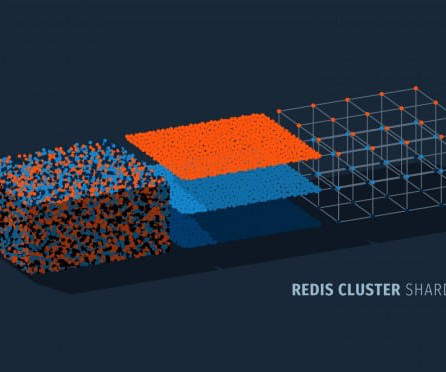
Redis Cluster is the native sharding implementation available within Redis that allows you to automatically distribute your data across multiple nodes without having to rely on external tools and utilities. High Availability. It also implements a Raft -like consensus approach to ensure availability of the entire cluster.
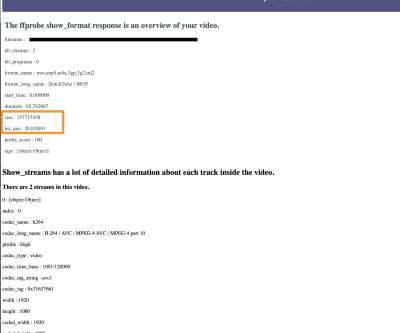
A video with large dimensions or a high bitrate will take longer to download and will require a higher speed network to play back smoothly. This leads to longer startup times, and if the network cannot supply the video fast enough, the video will stall during video playback. There is a solution though! Large preview ).
For example, if a lookup fails and times out to your first DNS server it queries the next DNS server until the correct IP address is returned, or it is unable to resolve as seen in the infamous "This webpage is not available" error below. So DNS services definitely go down!
But often, we use additional services and solutions within our environment for backups, storage, networking, and more. This covers the infrastructure, processes, and the application stack, including tracing, profiling, and logs.
As a basis for that discussion, first some definitions: Dependability The degree to which a product or service can be relied upon. Availability and Reliability are forms of dependability. Availability The degree to which a product or service is available for use when required. Availability, reliability, and state.
In the age of big-data-turned-massive-data, maintaining high availability , aka ultra-reliability, aka ‘uptime’, has become “paramount”, to use a ChatGPT word. So when they don’t get one, they ask again — and again… and again… We thus have two compelling reasons for why high availability is so important: 1. What is high availability?
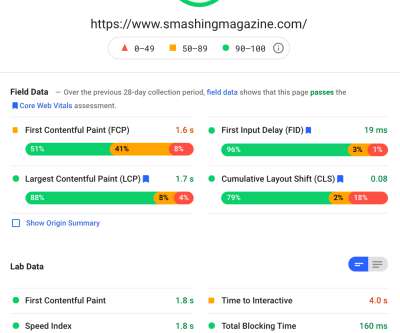
Google uses anonymized data from Chrome users to feedback metrics and makes these available in the Chrome User Experience Report (CrUX). CrUX data is available in a number of tools, including in Google Search Console for your site. That data is what they are using to measure these three metrics for the search rankings.
Network effects are not the same as monopoly control. It's not because there are no other options available to them because of structural issues. Cloud providers incur huge fixed costs for creating and maintaining a network of datacenters spread throughout the word. Does the there can be only one apply to the cloud?
I am very excited that today we have launched Amazon Route 53, a high-performance and highly-available Domain Name System (DNS) service. Authoritative servers hold the definitive mappings. Route 53 provides Authoritative DNS functionality implemented using a world-wide network of highly-available DNS servers. No lock-in.
With Dynatrace version 1.172, an updated of our metrics API endpoint (version 2) is now available. The latest version is based on our improved metrics framework, which provides: A logical tree structure for all available metric types. Globally unique metric keys that better integrate over multiple Dynatrace environments.
With Fargate, you don't need to stand up a control plane, choose the right instance type, or configure all the other components of your application stack like networking, scaling, service discovery, load balancing, security groups, permissions, or secrets management. This is the vision behind AWS Fargate.
Use it for <Provider> s, global definitions, application settings, and so on. Every time a new route is visited, our pages can tap into the AppStateContext and have their definitions passed down as props. A route will wrap other routes and thus provide them with common definitions instead of making developers duplicate code.
Let’s start with this: MongoDB is accurately referred to as source-available software. That early decision was notable because whereas the GPL is applied if derivative work is distributed, the AGPL license applies both for distributed work and whenever end users interact with a program over a network. Now, back to MongoDB itself.
It offers automatic data sharding, master-replica configurations for high availability, and a scalable and flexible architecture to maintain consistent performance. Sharding in Redis involves dividing data across multiple machines to enhance scalability and maintain availability. What is Redis Sharding?
But pages keep getting bigger and more complex year over year – and this increasing size and complexity is not fully mitigated by faster devices and networks, or by our hard-working browsers. Having said that, looking at data over the past ten years, it's safe to make the observation that pages are definitely trending bigger.
Practitioners use APM to ensure system availability, optimize service performance and response times, and improve user experiences. Causes can run the gamut — from coding errors to database slowdowns to hosting or network performance issues. Mobile apps, websites, and business applications are typical use cases for monitoring.
It also, however, takes a full network round trip to complete before anything else can be done on a connection. Finally, QUIC also uses so-called flow-control and congestion-control mechanisms that prevent a sender from overloading the network or the receiver, but that also make TCP slower than what you could do with raw UDP.
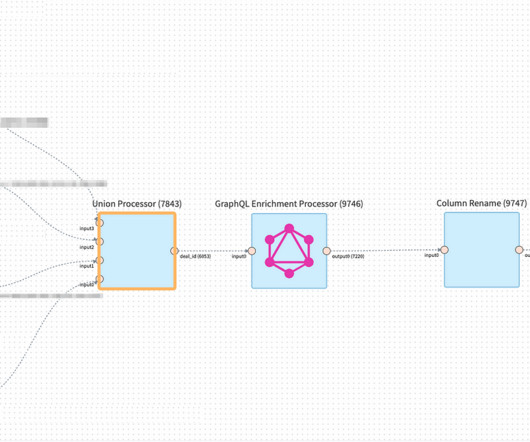
It is responsible for listening to incoming events and requests and prioritizing different tables and actions to make the best usage of the available resources. At the snapshot scan stage, we get a commit definition containing the list of files and their metadata (like size, number of records, etc.)
The code for the site is available on GitHub for reference. Using a network request inspector, I’m going to see if there’s anything we can remove via the Network panel in DevTools. I like using Fiddler , and when I inspect the network requests I see that there are indeed some old URLs and redirects floating around.
It's time once again to update our priors regarding the global device and network situation. This split decision was available via last year's update , but was somewhat buried. seconds on the target device and network profile, consuming 120KiB of critical path resources to become interactive, only 8KiB of which is script.
In this blog, I am trying to list the options available for users and list them in increasing order of priority. For example, the high availability solution Patroni passes some of the most critical parameters as a command line argument. So, the setting goes as part of the function definition.
There was a time when standing up a website or application was simple and straightforward and not the complex networks they are today. By definition, a distributed system is any system that comprises of multiple components on variety of machines that work together to appear as a single, organized system. The recipe was straightforward.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content