This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
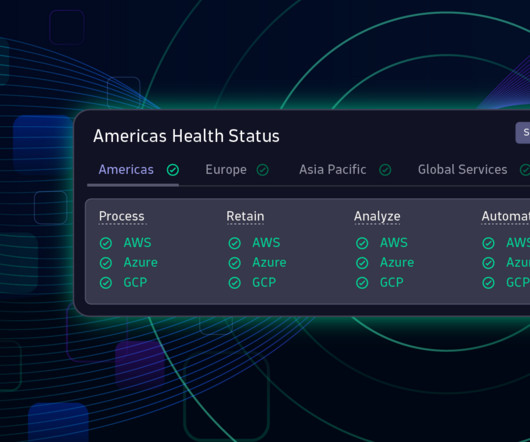
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. While the SLO management web UI and API are already available, the dashboard tile will be released within the next weeks.
DataJunction: Unifying Experimentation and Analytics Yian Shang , AnhLe At Netflix, like in many organizations, creating and using metrics is often more complex than it should be. DJ acts as a central store where metricdefinitions can live and evolve. Enter DataJunction (DJ).
From a cost perspective, internal customers waste valuable time sending tickets to operations teams asking for metrics, logs, and traces to be enabled. A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. This approach is costly and error prone.
Dynatrace collects a huge number of metrics for each OneAgent-monitored host in your environment. Depending on the types of technologies you’re running on individual hosts, the average number of metrics is about 500 per computational node. Running metric queries on a subset of entities for live monitoring and system overviews.
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. into NAM test definitions. Our script, available on GitHub , provides details.
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Like any IT or business project, you’ll need to track critical key metrics. Here are nine key DevOps metrics and DevOps KPIs that will help you be successful.
Dynatrace Synthetic Monitoring allows you to proactively monitor the availability of your public as well as your internal web applications and API endpoints from locations around the globe or important internal locations such as branch offices. Ensure better user experience with paint-focused performance metrics. Dynatrace news.
Welcome to the blog series where we give you a deeper dive into the latest awesomeness around Dynatrace : how we bring scale, zero configuration, automatic AI driven alerting, and root cause analysis to all your custom metrics, including open source observability frameworks like StatsD, Telegraf, and Prometheus.
That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags. In addition to tracing, observability also defines two other key concepts, metrics and logs. When software runs in a monolithic stack on on-site servers, observability is manageable enough. What is OpenTelemetry?
To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. Named after the Greek god who brought fire down from Mount Olympus, Prometheus metrics have been transforming observability since the project’s inception in 2012.
This dual-path approach leverages Kafkas capability for low-latency streaming and Icebergs efficient management of large-scale, immutable datasets, ensuring both real-time responsiveness and comprehensive historical data availability. Thus, all data in one region is processed by the Flink job deployed within thatregion.
It provides unified observability by automatically correlating logs and placing them in the context of traces and metrics. Unlike traditional setups that require predefined schemas, Grail allows you to store diverse data types without schema definitions at any point, providing greater flexibility in any analytic situation.
The standard dictionary subscript notation is also available. Imagine a ML practitioner on the Netflix Content ML team, sourcing features from hundreds of columns in our data warehouse, and creating a multitude of models against a growing suite of metrics. You can access Configs of any past runs easily through the Client API.
Captures metrics, traces, logs, and other telemetry data in context. Smartscape topology mapping: Dynatrace uses its Smartscape technology to semantically map metrics, traces, logs, and real user data to specific Kubernetes objects, including containers, pods, nodes, and services.
A new preview section enables you to test the definition iteratively against actual values before creating the SLO. On the Service-level objectives page, the Actions > Edit SLO entry has been renamed SLO definition. Calculated app, log, and service metrics now consume Davis data units (Metrics pool).
OneAgent gives you all the operational and business performance metrics you need, from the front end to the back end and everything in between—cloud instances, hosts, network health, processes, and services. But what if a particular metric that’s crucial to your monitoring needs isn’t covered out of the box? Why use Extensions.
And we definitely couldn’t replay test non-functional requirements like caching and logging user interaction. So, we relied on higher-level metrics-based testing: AB Testing and Sticky Canaries. To determine customer impact, we could compare various metrics such as error rates, latencies, and time to render. How does it work?
These are all interesting metrics from marketing point of view, and also highly interesting to you as they allow you to engage with the teams that are driving the traffic against your IT-system. In the next step change, the UTM campaign parameter to also be a user action property by editing the definition as shown on the screenshot below.
The flip side of speeding up delivery, however, is that each software release comes with the risk of impacting your goals of availability, performance, or any business KPIs. Which metrics are relevant for your business, anyway? Modern observability tools provide many metrics, but which ones are really important for your business?
Symptoms : No data is provided for affected metrics on dashboards, alerts, and custom device pages populated by the affected extension metrics. On the Service-level objectives page, the Actions > Edit SLO entry has been renamed SLO definition. General Availability (Build 1.231.196). Service-level objectives.
Availability guarantee of 99.95%/month for customers with an active Enterprise Success and Support subscription. Enhanced uptime measurement Our new SLA is tailored to reflect our current product offering and includes broad coverage of product functionality in the availabilitydefinitions.
We can establish these SLOs by setting availability and performance targets, such as a target uptime percentage or a target response time. We can build the availability SLO using the Dynatrace SLO wizard. We already know how to build the availability SLO. You can use the status metric as a reference for the global SLO.
The title size of a tile has been moved from the dashboard definition to the dashboard metadata definition and included in the advanced settings UI for dashboards. General Availability (Build 1.241.153). General Availability (Build 1.241.153). Dashboards. Dynatrace API. Dynatrace API. Resolved issues. Resolved issues.
Are you applying AI to the unique metrics and KPIs that matter most to the success of your digital business? Do you provide dashboards and analytics that combine technical and business metrics that are specific to your business? Dynatrace out-of-the-box metrics generally focus on availability, failure rate, and performance.
Monitoring , by textbook definition, is the process of collecting, analyzing, and using information to track a program’s progress toward reaching its objectives and to guide management decisions. Monitoring focuses on watching specific metrics. Here’s a closer look at logs, metrics, and distributed traces.
All of this convenient visibility is available with just a few clicks. This eliminates the need for creating ad hoc dashboards and figuring out which metrics to apply—it’s a one-stop shop for performance analytics and enabling an end-to-end visibility into the health state and performance of complex enterprise network infrastructures.
As a full stack monitoring platform, Dynatrace collects a huge number of metrics for each OneAgent monitored host in your environment. Depending on the types of technologies you’re running on your individual hosts, the average number of metrics is about 500 per computational node. New metric identifiers and structure.
We recently extended the pre-shipped code-level API definitions to group logical parts of our code so they’re consistently highlighted in all code-level views. Another benefit of defining custom APIs is that the memory allocation and surviving object metrics are split by each custom API definition.
These technologies are poorly suited to address the needs of modern enterprises—getting real value from data beyond isolated metrics. Just a few minutes after installation, you get all the performance metrics and log data you need to monitor IT infrastructure of any complexity—from front end to back end. Thus, Grail was born.
Spring also introduced Micrometer, a vendor-agnostic metric API with rich instrumentation options. Soon after, Dynatrace built a registry for exporting Micrometer metrics. Our data APIs, which ingest millions of metrics, traces, and logs per second, are reconciled using Micrometer-based metrics.
Collector Custom Resource A custom resource (CR) represents a customization of a specific Kubernetes installation that isnt necessarily available in a default Kubernetes installation; CRs help make Kubernetes more modular. There are two versions available: v1alpha1 : apiVersion: opentelemetry.io/v1alpha1 spec.containers[*].name}'
One of our Preview customers summarized the new analytics capabilities as follows: “The new analytics views for messaging systems will definitely change the way we troubleshoot asynchronous communication problems because now we have full visibility into connected producer and consumer services. This is great! How to get started.
This means we can compare the results for data that was publicly available against the results for data that was private but from the same book. We then used the models identification rate as the metric to distinguish between these classes. There is clear precedent for training on publicly available data.
To get a better handle on this, let’s start with some definitions. These can include business metrics, such as conversion rates, uptime, and availability; service metrics, such as application performance; or technical metrics, such as dependencies to third-party services, underlying CPU, and the cost of running a service.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). These metrics help to keep a network system up and running?, Other such metrics include uptime, downtime, number of incidents, time between incidents, and time to respond to and resolve an issue. So, what is MTTR?
If you still use the legacy version of Log Monitoring ( Log Monitoring v1 ), the Log Monitoring v1 documentation is still available, but we strongly encourage you to switch to the latest Dynatrace Log Monitoring version and gain direct access to the log content of all your mission-critical processes. General Availability (Build 1.239.178).
With Dynatrace, you only need to install a single OneAgent per host to collect all relevant metrics from 100% of your application-delivery chain. Given our relatively frequent releases, this means that you can benefit from 11 to 12 OneAgent updates a year that are deployed as soon as they are available for your environment.
Cloud-native observability for Google’s fully managed GKE Autopilot clusters demands new methods of gathering metrics, traces, and logs for workloads, pods, and containers to enable better accessibility for operations teams. Managed Kubernetes clusters on GKE Autopilot have gained unprecedented momentum among enterprises.
However, such observation periods come with a disadvantage: incidents can pile up and there is a delay between those incidents and the corresponding health metrics ultimately dropping low enough to trigger a warning. Most monitoring tools offer only a single SLO metric. Get up and running in under a minute with SLO templates.
metric-based events) and events that are independent of any metric (for example, process crashes, deployment changes, and VM motion events). This blog post focuses on the definition of events that are triggered by measurements (i.e, metric-based events) within your Dynatrace monitoring environment. Availability.
Modern applications—enterprise and consumer—increasingly depend on third-party services to create a fast, seamless, and highly available experience for the end-user. If this were the case, IT teams would need to plan to migrate to the newest available version of that API. Dynatrace news. So what is API monitoring? Ways to monitor APIs.
There are many definitions of environmental sustainability, most of which converge on a common theme: collectively and individually, we have a responsibility to act to protect global ecosystems and support health and wellbeing, now and in the future. General availability is planned for the second quarter of 2023.
Adoption As of writing this blog, Conductor orchestrates 600+ workflow definitions owned by 50+ teams across Netflix. Below is a snapshot of our Kibana dashboard which shows the workflow execution metrics over a typical 7-day period. Cassandra persistence module is a partial implementation.
We also couldn’t compromise on performance and availability.” But “the benefits are definitely worth the effort, provided you do it in a strategic way,” Bollampally said. “The key metrics we were able to gather from Dynatrace helped us complete the testing with zero downtime,” Bollampally said.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content