This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
by David Berg , Ravi Kiran Chirravuri , Romain Cledat , Savin Goyal , Ferras Hamad , Ville Tuulos tl;dr Metaflow is now open-source! Netflix applies data science to hundreds of use cases across the company, including optimizing content delivery and video encoding. How could we improve the quality of life for data scientists?
Ready to transition from a commercial database to opensource, and want to know which databases are most popular in 2019? We broke down the data by opensource databases vs. commercial databases: OpenSource Databases. Popular examples of opensource databases include MySQL, PostgreSQL and MongoDB.
Opensource software has become a key standard for developing modern applications. From common coding libraries to orchestrating container-based computing, organizations now rely on opensource software—and the open standards that define them—for essential functions throughout their software stack.
It also makes the process risky as production servers might be more exposed, leading to the need for real-time production data. This is why were excited to announce the launch of Dynatrace Live Debugger , a revolutionary tool that provides developers with visibility and data access to their running applications. Browse your code.
Our talk was called “Putting the Experience in UX: The Importance of Making Data Accessible.” OpenTelemetry provides us with a standard for generating, collecting, and emitting telemetry, and we have existing tooling that leverages OTel data to help us understand work processes and workflows.
It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data. This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes.
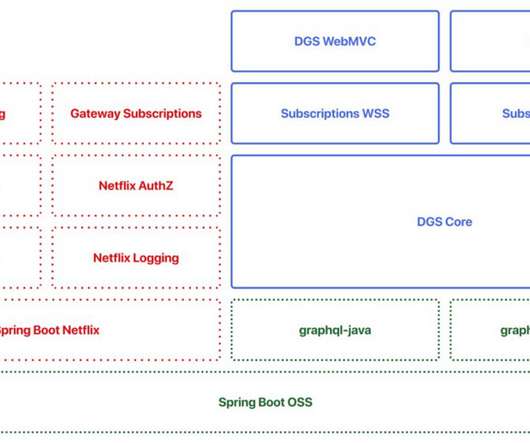
By Paul Bakker and Kavitha Srinivasan , Images by David Simmer , Edited by Greg Burrell Netflix has developed a Domain Graph Service (DGS) framework and it is now opensource. Comprehensive documentation is available on the website but let’s walk through an example to show you how easy it is to use this framework.
Some time ago Federico Toledo published Performance Testing with OpenSource Tools- Busting The Myths. Otherwise we wouldn’t see so many commercial tools built on the top of opensource including BlazeMeter (it is ironic that the article is posted on the BlazeMeter site), Flood, and OctoPerf.
Syslog is the go-to protocol that delivers infrastructure administrators, network engineers, and security team logs that tell them all they need to know about their systems’ delivery, performance, availability, and security. The Dynatrace OTel Collector for syslog has numerous benefits.
The newly introduced step-by-step guidance streamlines the process, while quick data flow validation accelerates the onboarding experience even for power users. Tagging is also available when using API-based ingestion methods or later within the platform. Different log ingestion methods are available to address various needs.
As organizations strive for observability and data democratization, OpenTelemetry emerges as a key technology to create and transfer observability data. This collector, fully supported and maintained by Dynatrace, is entirely opensource. A collector helps developers control their telemetry data streams for each signal.
The addition of OpenTelemetry is especially helpful for organizations looking at embedding OpenTelemetry into their applications as their data will automatically enrich PurePath’s distributed trace data. For this, they created a form where they fill data such as business unit, application name, application URL, etc.
Structured Query Language (SQL) is a simple declarative programming language utilized by various technology and business professionals to extract and transform data. Visualization & Reporting: Can the tool generate reports or visual representations like ER diagrams, data charts, or query execution plans?
Managing High Availability (HA) in your PostgreSQL hosting is very important to ensuring your database deployment clusters maintain exceptional uptime and strong operational performance so your data is always available to your application. It reduces downtime and supports business continuity.
In the final post of this series, we will review the last solution, Patroni by Zalando, and compare all three at the end so you can determine which high availability framework is best for your PostgreSQL hosting deployment. Managing High Availability in PostgreSQL – Part I: PostgreSQL Automatic Failover. Patroni for PostgreSQL.
Metric definitions are often scattered across various databases, documentation sites, and code repositories, making it difficult for analysts and data scientists to find reliable information quickly. A metric can therefore be defined once in DJ and be made available across analytics dashboards and experimentation analysis.
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. But is five nines availability attainable? Downtime per year. 90% (one nine).
Netflix has open-sourced Escrow Buddy, which helps Security and IT teams ensure they have valid FileVault recovery keys for all their Macs in MDM. They can also facilitate automations that require information available only in the “login window” context, such as the provided username and password. Deploy Escrow Buddy.
You’re gathering a lot of data, but you can’t make sense of it. A histogram is a specific type of metric that allows users to understand the distribution of data points over a period of time. In practice, histograms are useful when the measurement distribution is relevant and the data sets are large.
Whether youre a developer, database administrator, or data analyst, a good GUI can make everyday tasks faster, clearer, and less error-prone. In this post, well walk through some of the best MySQL GUI tools available in 2025covering both free and commercial optionsso you can find the one that fits your workflow.
The jobs executing such workloads are usually required to operate indefinitely on unbounded streams of continuous data and exhibit heterogeneous modes of failure as they run over long periods. Failures are injected using Chaos Mesh , an opensource chaos engineering platform integrated with Kubernetes deployment.
Some time ago, at a restaurant near Boston, three Dynatrace colleagues dined and discussed the growing data challenge for enterprises. At its core, this challenge involves a rapid increase in the amount—and complexity—of data collected within a company. Work with different and independent data types. Thus, Grail was born.
We are a company of opensource proponents. We’re also dedicated and active participants in the global opensource community. Both opensource and proprietary options have advantages. With opensource database software , anyone in the general public can access the source code, read it, and modify it.
From the moment a Netflix film or series is pitched and long before it becomes available on Netflix, it goes through many phases. Operational Reporting is a reporting paradigm specialized in covering high-resolution, low-latency data sets, serving detailed day-to-day activities¹ and processes of a business domain.
Store the data in an optimized, highly distributed datastore. Additionally, some collectors will instead poll our kafka queue for impressions data. This data is processed from a real-time impressions stream into a Kafka queue, which our title health system regularly polls. Track real-time title impressions from the NetflixUI.
In today’s data-driven world, businesses across various industry verticals increasingly leverage the Internet of Things (IoT) to drive efficiency and innovation. Dynatrace offers a feature-rich agent, Dynatrace OneAgent ® , and an agentless opensource approach perfectly tailored for edge-IoT use cases, leveraging OpenTelemetry.
OpenTelemetry Astronomy Shop is a demo application created by the OpenTelemetry community to showcase the features and capabilities of the popular open-source OpenTelemetry observability standard. metrics from span data. Afterward, the demo starts instantly, and the load generator automatically begins creating data.
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. However, there are many obstacles and limitations along the way to becoming a data-driven organization. Understanding the context.
IT operations analytics is the process of unifying, storing, and contextually analyzing operational data to understand the health of applications, infrastructure, and environments and streamline everyday operations. ITOA collects operational data to identify patterns and anomalies for faster incident management and near-real-time insights.
The study analyzes factual Kubernetes production data from thousands of organizations worldwide that are using the Dynatrace Software Intelligence Platform to keep their Kubernetes clusters secure, healthy, and high performing. Open-source software drives a vibrant Kubernetes ecosystem. Java, Go, and Node.js
Percona is dedicated to opensource software. But recently, opensource software has come under attack. Once opensource software is being locked away by changing licenses and code that you depended on. Before opensource was available, there was little to no interoperability between computer systems.
The subject line said: “Success Story: Major Issue in single AWS Frankfurt Availability Zone!” The problem started at 1:24PM PDT, with the services starting to become available again about 3 hours later. In our case that includes the login to our SaaS tenants and exploring captured data. Ready to learn more?
It is an open standard format which organizes data into key/value pairs and arrays detailed in RFC 7159. JSON is the most common format used by web services to exchange data, store documents, unstructured data, etc. You can also check out our Working with JSON Data in PostgreSQL vs. JSONB Patterns & Antipatterns.
The unstoppable rise of opensource databases. One database in particular is causing a huge dent in Oracle’s market share – opensource PostgreSQL. See how opensource PostgreSQL Community version costs compare to Oracle Standard Edition and Oracle Enterprise Edition. What’s causing this massive shift?
Andreas Andreakis , Ioannis Papapanagiotou Overview Change-Data-Capture (CDC) allows capturing committed changes from a database in real-time and propagating those changes to downstream consumers [1][2]. Therefore, dumps are needed to capture the full state of a source. Designed with High Availability in mind.
In this article, I’m going to demonstrate how you can migrate a comprehensive web application from MySQL to YugabyteDB using the open-sourcedata migration engine YugabyteDB Voyager. This helps improve availability, scalability, and performance.
Over the last year, Dynatrace extended its AI-powered log monitoring capabilities by providing support for all log datasources. We added monitoring and analytics for log streams from Kubernetes and multicloud platforms like AWS, GCP, and Azure, as well as the most widely used open-source log data frameworks.
Migrating a proprietary database to opensource is a major decision that can significantly affect your organization. Advantages of migrating to opensource For many reasons mentioned earlier, organizations are increasingly shifting towards opensource databases for their data management needs.
Data Engineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ Data Engineers of Netflix ” series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer on the Product Data Science and Engineering team.
PostgreSQL graphical user interface (GUI) tools help these opensource database users to manage, manipulate, and visualize their data. Offers great visualization to help you interpret your data. The window-based interface makes it much easier to manage your PostgreSQL data. pgAdmin Cost: Free (opensource).
OpenTelemetry standardizes how organizations instrument, generate, and collect telemetry data for analysis and provides community-based support. Because of its flexibility, this opensource approach to instrumenting and collecting telemetry data is becoming increasingly important in large-size organizations.
Docker Engine is built on top containerd , the leading open-source container runtime, a project of the Cloud Native Computing Foundation (DNCF). Kubernetes is an open-source container orchestration platform for managing, automating, and scaling containerized applications. Here the overlap with Kubernetes begins.
Fluentd is an open-sourcedata collector that unifies log collection, processing, and consumption. Built-in resiliency ensures data completeness and consistency even if Fluentd or an endpoint service goes down temporarily. All metrics, traces, and real user data are also surfaced in the context of specific events.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Both serve distinct purposes, from managing message queues to ingesting large data volumes. What is RabbitMQ? What is Apache Kafka?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content