This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When we launched the new Dynatrace experience, we introduced major updates to the platform, including Grail ™, our innovative data lakehouse unifying observability, security, and business data, and Dynatrace Query Language ( DQL ) for accessing and exploring unified data.
Expectations for network monitoring In today’s digital landscape, businesses rely heavily on their IT infrastructure to deliver seamless services to customers. However, network issues can lead to significant downtime, affecting user experience and business operations. For more details, please refer to Dynatrace Documentation.
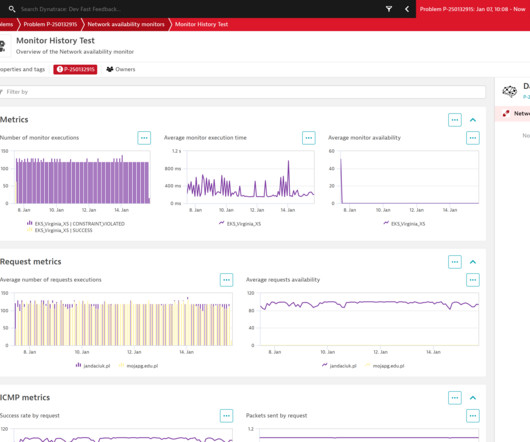
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Are all network devices up and running, and is the network providing reliable and swift access to your systems?
By Alok Tiagi , Hariharan Ananthakrishnan , Ivan Porto Carrero and Keerti Lakshminarayan Netflix has developed a network observability sidecar called Flow Exporter that uses eBPF tracepoints to capture TCP flows at near real time. Without having network visibility, it’s difficult to improve our reliability, security and capacity posture.
Dynatrace Managed is intrinsically highly available as it stores three copies of all events, user sessions, and metrics across its cluster nodes. The network latency between cluster nodes should be around 10 ms or less. Near-zero RPO and RTO—monitoring continues seamlessly and without data loss in failover scenarios.
Managing SNMP devices at scale can be challenging SNMP (Simple Network Management Protocol) provides a standardized framework for monitoring and managing devices on IP networks. Its simplicity, scalability, and compatibility with a wide range of hardware make it an ideal choice for network management across diverse environments.
This, of course, is exacerbated by the new Vitals announcement, whereby data from the Chrome User eXperience Report will be used to aid and influence rankings. Every browser available on iOS is simply a wrapper around Safari. Network Link Conditioner. In there, you should find a tool called Network Link Conditioner.
Cloud service providers (CSPs) share carbon footprint data with their customers, but the focus of these tools is on reporting and trending, effectively targeting sustainability officers and business leaders. The certification results are now publicly available.
In the final post of this series, we will review the last solution, Patroni by Zalando, and compare all three at the end so you can determine which high availability framework is best for your PostgreSQL hosting deployment. Managing High Availability in PostgreSQL – Part I: PostgreSQL Automatic Failover. Network Isolation Tests.
Exploratory analytics now cover more bespoke scenarios, allowing you to access any element of test results stored in the Dynatrace Grail data lakehouse. Thanks to the power of Grail, those details are available for all executions stored for the entire retention period during which synthetic results are kept.
Large enterprise environments are often distributed across multiple data centers around the world. Unnecessary traffic between such data centers can result in wasted resources, unpredictable downtimes, and lost business. preventing unrelated traffic between data centers and regions. optimizing traffic routing.
It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data. This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes.
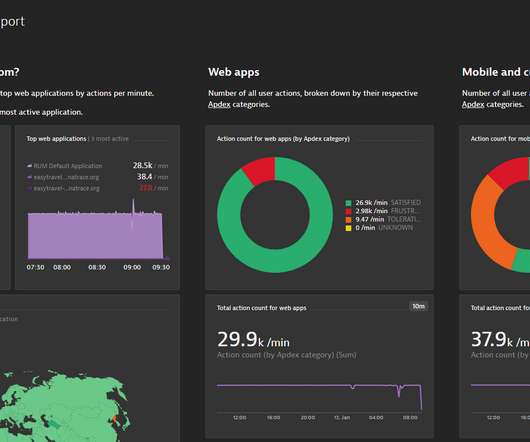
Welcome, data enthusiasts! Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the dataavailable to you is essential. In this blog series, we’ll guide you through creating powerful dashboards that transform complex data into actionable insights.
Managing High Availability (HA) in your PostgreSQL hosting is very important to ensuring your database deployment clusters maintain exceptional uptime and strong operational performance so your data is always available to your application. It reduces downtime and supports business continuity.
With all the data collected and powered by our Davis AI-driven causation engine, Dynatrace automatically identifies slowdowns in your applications and services and points you to their root cause. Ensure high quality network traffic by tracking DNS requests out-of-the-box. Network services visibility (DNS, NTP, ActiveDirectory).
Quick and easy network infrastructure monitoring. Would you like to access all your monitoring data on a single platform? Dynatrace has you covered—Dynatrace extensions collect the necessary data and offer improved visibility wherever you need a single platform for IM and APM purposes. Start monitoring in minutes. Interfaces.
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. But is five nines availability attainable? Downtime per year. 90% (one nine).
For cloud operations teams, network performance monitoring is central in ensuring application and infrastructure performance. If the network is sluggish, an application may also be slow, frustrating users. Worse, a malicious attacker may gain access to the network, compromising sensitive application data.
Complexity and data volume for IT infrastructure soars to new heights. The volume of data and events grows in tandem with the rising complexity of IT infrastructure. Monitoring modern IT infrastructure is difficult, sometimes impossible, without advanced network monitoring tools. How SNMP traps help detect problems.
We’re happy to announce the General Availability of cross-environment dashboarding capabilities (having released this functionality in an Early Adopter release with Dynatrace version 1.172 back in June 2019). Visualize data from multiple environments on a single dashboard. Step 2) Configure the remote environment connection.
However, your responsibilities might change or expand, and you need to work with unfamiliar data sets. Activate Davis AI to analyze charts within seconds Davis AI can help you expand your dashboards and dive deeper into your availabledata to extract additional information.
In today’s complex IT environments, the sheer volume of data created makes it impossible for humans to monitor, comprehend, or troubleshoot problems before they impact the experience of your end users. Still, you might have use cases that rely on important custom data streams. Now you can: Alert on the outage of a custom data source.
Log data provides a unique source of truth for debugging applications, optimizing infrastructure, and investigating security incidents. This contextualization of log data enables AI-powered problem detection and root cause analysis at scale. Dynamic landscape and data handling requirements result in manual work.
Having released this functionality in an Early Adopter Release with OneAgent version 1.173 and Dynatrace version 1.174 back in August 2019, we’re now happy to announce the General Availability of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux. Release details.
Log data—the most verbose form of observability data, complementing other standardized signals like metrics and traces—is especially critical. As cloud complexity grows, it brings more volume, velocity, and variety of log data. When trying to address this challenge, your cloud architects will likely choose Amazon Data Firehose.
This is the ability to see into and measure the current state of a system based on the data it generates, which typically includes logs, metrics, traces, end-user experiences, and context across cloud, multi-cloud, and hybrid environments. This blog originally appeared in Federal News Network. First, let’s discuss observability.
In today’s data-driven world, businesses across various industry verticals increasingly leverage the Internet of Things (IoT) to drive efficiency and innovation. Both methods allow you to ingest and process raw data and metrics. The ADS-B protocol differs significantly from web technologies.
IT operations analytics is the process of unifying, storing, and contextually analyzing operational data to understand the health of applications, infrastructure, and environments and streamline everyday operations. ITOA collects operational data to identify patterns and anomalies for faster incident management and near-real-time insights.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. Second, developers had to constantly re-learn new data modeling practices and common yet critical data access patterns.
Welcome back to our power dashboarding blog series , data enthusiasts! Query your data with natural language Davis CoPilot is an excellent virtual assistant that helps you create queries using natural language. exploring your data when you know your desired outcome but are unfamiliar with the availabledata.
Youll also learn strategies for maintaining data safety and managing node failures so your RabbitMQ setup is always up to the task. Implementing clustering and quorum queues in RabbitMQ significantly improves load distribution and data redundancy, ensuring high availability and fault tolerance for messaging services.
Dynatrace and the Dynatrace Intelligent Observability Platform have added support for the newly introduced Amazon VPC Flow Logs to Amazon Kinesis Data Firehose. This support enables customers to define specific endpoint delivery of real-time streaming data to platforms such as Dynatrace. What is VPC Flow Logs? Why Dynatrace?
In a digital-first world, site reliability engineers and IT data analysts face numerous challenges with data quality and reliability in their quest for cloud control. Increasingly, organizations seek to address these problems using AI techniques as part of their exploratory data analytics practices.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance Data Engineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. We expect complete and accurate data at the end of each run.
OpenTelemetry , the open source observability tool, has become the go-to standard for instrumenting custom applications to collect observability telemetry data. For this third and final part of our series, we saved the best for last: How you can enhance telemetry data even more and with less effort on your end with Dynatrace OneAgent.
With dashboard subscriptions and scheduled reports, available as an Early Adopter Release with version 1.184, Dynatrace now makes your life substantially easier. Custom charts allow you to visualize metric performance over time, and USQL tiles allow you to dig deep into user session monitoring data. Dynatrace news.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
Recent improvements in OneAgent runtime-data handling. Sometimes these locations landed on mount points which, due to capacity, availability, or access constraints, weren’t well suited for large runtime storage. Storage and network transfer of files is a measurable cost. Customizable location of large runtime files.
The massive volumes of log data associated with a breach have made cybersecurity forensics a complicated, costly problem to solve. As organizations adopt more cloud-native technologies, observability data—telemetry from applications and infrastructure, including logs, metrics, and traces—and security data are converging.
By Anupom Syam Background At Netflix, our current data warehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
When deploying in production, it’s highly recommended to setup in a MongoDB replica set configuration so your data is geographically distributed for high availability. 1305:12 @(shell):1:1 2019-04-18T19:44:42.261+0530 I NETWORK [thread1] trying reconnect to SG-example-1.servers.mongodirector.com:27017 import pymongo.
With more organizations taking the multicloud plunge, monitoring cloud infrastructure is critical to ensure all components of the cloud computing stack are available, high-performing, and secure. With agent monitoring, third-party software collects data and reports from the component that’s attached to the agent.
This year’s conference agenda was packed full of choices, including: Keynotes : Topics included accelerating digital transformation, with Dynatrace CIO Mike Maciag, and Spatial Collapse: The Great Acceleration of Turning Data Into an Asset, with Tricia Wang from Sudden Compass. We’ve all heard it: data is one of your biggest assets.
The key to success is making data in this complex ecosystem actionable, as many types of syslog producers exist. These include traditional on-premises network devices and servers for infrastructure applications like databases, websites, or email. A local endpoint in a protected network or DMZ is required to capture these messages.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content