This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
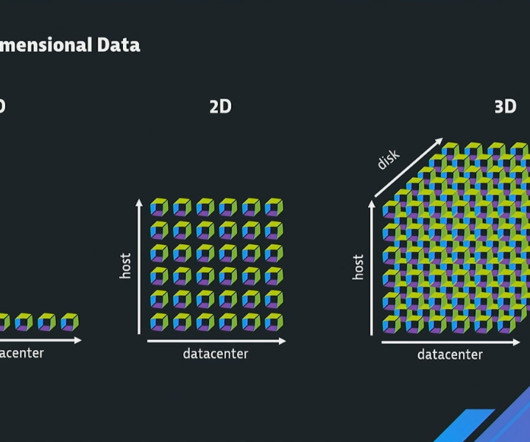
To provide maximum freedom in selecting the service-level indicators that matter most to your business, Dynatrace combines SLOs with the power of Dynatrace Grail™ data lakehouse, the central data platform with heterogeneous and contextually linked data. This is where Grail, the Dynatrace central data platform, excels.
Take your monitoring, data exploration, and storytelling to the next level with outstanding data visualization All your applications and underlying infrastructure produce vast volumes of data that you need to monitor or analyze for insights.
There’s a goldmine of business data traversing your IT systems, yet most of it remains untapped. To unlock business value, the data must be: Accessible from anywhere. Data has value only when you can access it, no matter where it lies. Agile business decisions rely on fresh data. Easy to access. Contextualized.
As modern multicloud environments become more distributed and complex, having real-time insights into applications and infrastructure while keeping data residency in local markets is crucial. As of October 2024, Dynatrace is available on Microsoft Azure Australia East region, enabling joint customers to maintain a local SaaS presence.
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. But is five nines availability attainable? What is always-on infrastructure?
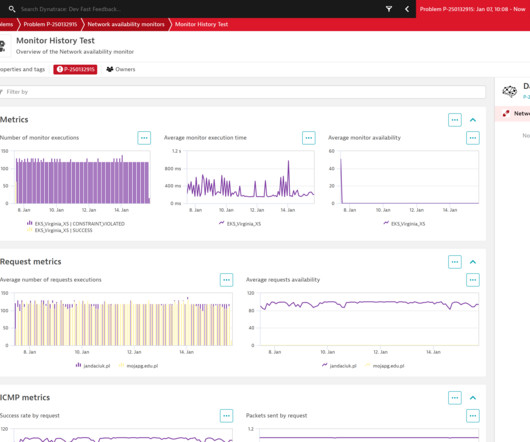
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Our script, available on GitHub , provides details. into NAM test definitions.
Expectations for network monitoring In today’s digital landscape, businesses rely heavily on their IT infrastructure to deliver seamless services to customers. The market demands a robust solution that can monitor applications and the underlying network infrastructure to ensure end-to-end availability and performance.
However, the challenge often lies in the fragmentation of vulnerability data across different systems and tools. On the other hand, Tenable focuses on infrastructure, conducting comprehensive scans of hosts, web applications, and compliance checks.
Welcome, data enthusiasts! Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the dataavailable to you is essential. In this blog series, we’ll guide you through creating powerful dashboards that transform complex data into actionable insights.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
By taking advantage of native Kubernetes standards, Dynatrace Cloud Native Full Stack injection empowers you to precisely provide the data that your teams need in exceptionally fast and automated ways. None of this complexity is exposed to application and infrastructure teams. Flexible automation for Kubernetes observability.
Cloud service providers (CSPs) share carbon footprint data with their customers, but the focus of these tools is on reporting and trending, effectively targeting sustainability officers and business leaders. This is partly due to the complexity of instrumenting and analyzing emissions across diverse cloud and on-premises infrastructures.
An hourly rate for Infrastructure Monitoring The Dynatrace Platform Subscription (DPS) offers a flat rate for Infrastructure Monitoring , providing observability for cloud platforms, containers, networks, and data center technologies with no limits on host memory and with AIOps included.
For IT infrastructure managers and site reliability engineers, or SREs , logs provide a treasure trove of data. But on their own, logs present just another data silo as IT professionals attempt to troubleshoot and remediate problems. Data volume explosion in multicloud environments poses log issues.
IBM Z and LinuxONE mainframes running the Linux operating system enable you to respond faster to business demands, protect data from core to cloud, and streamline insights and automation. Telemetry data, such as traces and metrics, allow you to analyze the end-to-end performance of your deployed applications.
Through this integration, Dynatrace enriches data collected by Microsoft Sentinel to provide organizations with enhanced data insights in context of their full technology stack. This enables Dynatrace customers to achieve faster time-to-value and accelerate innovation. Audit logs.
.” While this methodology extends to every layer of the IT stack, infrastructure as code (IAC) is the most prominent example. Here, we’ll tackle the basics, benefits, and best practices of IAC, as well as choosing infrastructure-as-code tools for your organization. What is infrastructure as code? Consistency.
More than 90% of enterprises now rely on a hybrid cloud infrastructure to deliver innovative digital services and capture new markets. That’s because cloud platforms offer flexibility and extensibility for an organization’s existing infrastructure. Dynatrace news. What is hybrid cloud architecture?
Infrastructure and operations teams must maintain infrastructure health for IT environments. With the Infrastructure & Operations app ITOps teams can quickly track down performance issues at their source, in the problematic infrastructure entities, by following items indicated in red.
However, the extended infrastructure of CDNs requires diligent monitoring to ensure optimal performance and identify potential issues. CDN observability refers to gaining insights into the CDN infrastructure's performance, availability, and reliability. What Is CDN Observability?
The newly introduced step-by-step guidance streamlines the process, while quick data flow validation accelerates the onboarding experience even for power users. Tagging is also available when using API-based ingestion methods or later within the platform. Different log ingestion methods are available to address various needs.
Managing High Availability (HA) in your PostgreSQL hosting is very important to ensuring your database deployment clusters maintain exceptional uptime and strong operational performance so your data is always available to your application. It reduces downtime and supports business continuity.
It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data. This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes.
by Jasmine Omeke , Obi-Ike Nwoke , Olek Gorajek Intro This post is for all data practitioners, who are interested in learning about bootstrapping, standardization and automation of batch data pipelines at Netflix. You may remember Dataflow from the post we wrote last year titled Data pipeline asset management with Dataflow.
The end goal, of course, is to optimize the availability of organizations’ software. Dynatrace is widely recognized for its AI capabilities’ ability to predict and prevent issues, and automatically identify root causes, maximizing availability. Eventually, the goal is to arrive at self-healing through autonomous cloud operations.
Ensuring smooth operations is no small feat, whether you’re in charge of application performance, IT infrastructure, or business processes. However, your responsibilities might change or expand, and you need to work with unfamiliar data sets. Your trained eye can interpret them at a glance, a skill that sets you apart.
Some time ago, at a restaurant near Boston, three Dynatrace colleagues dined and discussed the growing data challenge for enterprises. At its core, this challenge involves a rapid increase in the amount—and complexity—of data collected within a company. Work with different and independent data types. Thus, Grail was born.
Log data—the most verbose form of observability data, complementing other standardized signals like metrics and traces—is especially critical. As cloud complexity grows, it brings more volume, velocity, and variety of log data. When trying to address this challenge, your cloud architects will likely choose Amazon Data Firehose.
Log data provides a unique source of truth for debugging applications, optimizing infrastructure, and investigating security incidents. This contextualization of log data enables AI-powered problem detection and root cause analysis at scale. Dynamic landscape and data handling requirements result in manual work.
Vidhya Arvind , Rajasekhar Ummadisetty , Joey Lynch , Vinay Chella Introduction At Netflix our ability to deliver seamless, high-quality, streaming experiences to millions of users hinges on robust, global backend infrastructure. To overcome these challenges, we developed a holistic approach that builds upon our Data Gateway Platform.
In today’s complex IT environments, the sheer volume of data created makes it impossible for humans to monitor, comprehend, or troubleshoot problems before they impact the experience of your end users. Still, you might have use cases that rely on important custom data streams. Now you can: Alert on the outage of a custom data source.
I have ingested important custom data into Dynatrace, critical to running my applications and making accurate business decisions… but can I trust the accuracy and reliability?” ” Welcome to the world of data observability. At its core, data observability is about ensuring the availability, reliability, and quality of data.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
They handle complex infrastructure, maintain service availability, and respond swiftly to incidents. Predictive AI uses machine learning, data analysis, statistical models, and AI methods to predict anomalies, identify patterns, and create forecasts. Proactive resource allocation. Capacity planning.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Both serve distinct purposes, from managing message queues to ingesting large data volumes.
Welcome back to our power dashboarding blog series , data enthusiasts! You can either continue with the custom infrastructure metrics dashboard you created in Part I or use the dashboard we prepared here (Dynatrace login required). exploring your data when you know your desired outcome but are unfamiliar with the availabledata.
While this approach can be effective if the model is trained with a large amount of data, even in the best-case scenarios, it amounts to an informed guess, rather than a certainty. But to be successful, data quality is critical. Teams need to ensure the data is accurate and correctly represents real-world scenarios. Consistency.
Recently, the Parliament of India released the Digital Personal Data Protection Act 2023 , which regulates the processing of digital personal data in India and recognizes the right of individuals to protect their data in India. Dynatrace is already supported in 17 local regions on three hyperscalers (AWS, Azure, and GCP).
IT operations analytics is the process of unifying, storing, and contextually analyzing operational data to understand the health of applications, infrastructure, and environments and streamline everyday operations. Here are the six steps of a typical ITOA process : Define the datainfrastructure strategy.
Considering the latest State of Observability 2024 report, it’s evident that multicloud environments not only come with an explosion of data beyond humans’ ability to manage it. It’s increasingly difficult to ingest, manage, store, and sort through this amount of data. You can find the list of use cases here.
Over the last year, Dynatrace extended its AI-powered log monitoring capabilities by providing support for all log data sources. We added monitoring and analytics for log streams from Kubernetes and multicloud platforms like AWS, GCP, and Azure, as well as the most widely used open-source log data frameworks. Duration: 163.41
Optimize cost and availability while staying compliant Observability data like logs and metrics provide automated answers, root cause detection, and security issues. Customer decisions about data retention are often determined by important security, privacy, and legal issues.
The jobs executing such workloads are usually required to operate indefinitely on unbounded streams of continuous data and exhibit heterogeneous modes of failure as they run over long periods. Failures can occur unpredictably across various levels, from physical infrastructure to software layers.
The data locked in your log files can be a goldmine for your application developers, operations teams, and your enterprise as a whole. However, it can be complicated , expensive , or even impossible to set up robust observability that makes use of this data. Log format inconsistency makes it a challenge to access critical data.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content