This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
Building and Scaling Data Lineage at Netflix to Improve DataInfrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
Central engineering teams enable this operational model by reducing the cognitive burden on innovation teams through solutions related to securing, scaling and strengthening (resilience) the infrastructure. All these micro-services are currently operated in AWS cloud infrastructure.
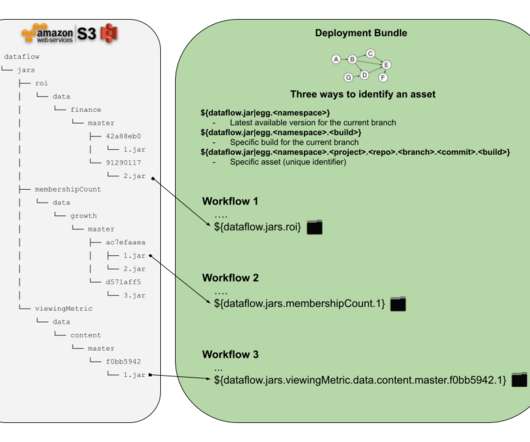
Optionally, this step can use the Write-Audit-Publish pattern to ensure that data is correct before it is made available to the rest of the company. Centralized Best Practices Datainfrastructure evolves continually. some_db.source_table.yaml ??? sparksql_write.sql ??? test_sparksql_write.py repartition(1).withColumn("date",
Berg , Romain Cledat , Kayla Seeley , Shashank Srikanth , Chaoying Wang , Darin Yu Netflix uses data science and machine learning across all facets of the company, powering a wide range of business applications from our internal infrastructure and content demand modeling to media understanding.
December 2 1pm-2pm CMP 326-R Capacity Management Made Easy with Amazon EC2 Auto Scaling Vadim Filanovsky , Senior Performance Engineer & Anoop Kapoor, AWS Abstract :Amazon EC2 Auto Scaling offers a hands-free capacity management experience to help customers maintain a healthy fleet, improve application availability, and reduce costs.
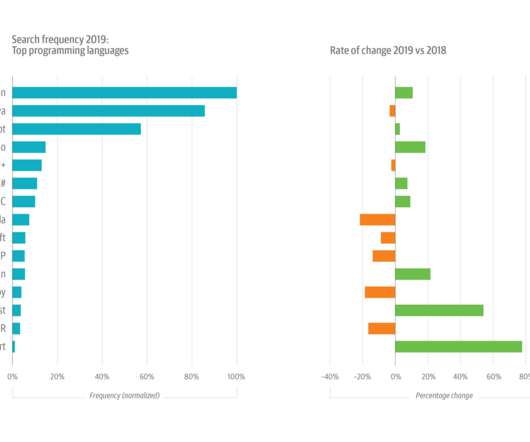
This year’s growth in Python usage was buoyed by its increasing popularity among data scientists and machine learning (ML) and artificial intelligence (AI) engineers. Software architecture, infrastructure, and operations are each changing rapidly. Also: infrastructure and operations is trending up, while DevOps is trending down.
Let’s define some requirements that we are interested in delivering to the Netflix dataengineers or anyone who would like to schedule a workflow with some external assets in it. Conclusions This new method available for Netflix dataengineers makes workflow management easier, more transparent and more reliable.
This is particularly important as we build out new functionality that relies on Pushy; a strong, stable infrastructure foundation allows our partners to continue to build on top of Pushy with confidence. As Pushy’s portfolio grew, we experienced some pain points with Dynomite.
Network Availability: The expected continued growth of our ecosystem makes it difficult to understand our network bottlenecks and potential limits we may be reaching. Cloud Network Insight is a suite of solutions that provides both operational and analytical insight into the Cloud Network Infrastructure to address the identified problems.
AWS recently announced the general availability (GA) of Amazon EC2 P5 instances powered by the latest NVIDIA H100 Tensor Core GPUs suitable for users that require high performance and scalability in AI/ML and HPC workloads. The GA is a follow-up to the earlier announcement of the development of the infrastructure.
Some of the optimizations are prerequisites for a high-performance data warehouse. Sometimes DataEngineers write downstream ETLs on ingested data to optimize the data/metadata layouts to make other ETL processes cheaper and faster. It decides what to do and when to do in response to an incoming event.
At Netflix, our data scientists span many areas of technical specialization, including experimentation, causal inference, machine learning, NLP, modeling, and optimization. Together with data analytics and dataengineering, we comprise the larger, centralized Data Science and Engineering group.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
December 2 1pm-2pm CMP 326-R Capacity Management Made Easy with Amazon EC2 Auto Scaling Vadim Filanovsky , Senior Performance Engineer & Anoop Kapoor, AWS Abstract :Amazon EC2 Auto Scaling offers a hands-free capacity management experience to help customers maintain a healthy fleet, improve application availability, and reduce costs.
December 2 1pm-2pm CMP 326-R Capacity Management Made Easy with Amazon EC2 Auto Scaling Vadim Filanovsky , Senior Performance Engineer & Anoop Kapoor, AWS Abstract :Amazon EC2 Auto Scaling offers a hands-free capacity management experience to help customers maintain a healthy fleet, improve application availability, and reduce costs.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
In such a data intensive environment, making key business decisions such as running marketing and sales campaigns, logistic planning, financial analysis and ad targeting require deriving insights from these data. However, the datainfrastructure to collect, store and process data is geared toward developers (e.g.,
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Lastly, we will talk about the internal platform and product divide – one key reason why data pipeline initiatives typically fail – and why it is better working backward from the product. Unfortunately, building data pipelines remains a daunting, time-consuming, and costly activity.
Since then Donna’s been bringing her expertise to Pulumi , a startup promising to make infrastructure automation much more friendly and less, well, YAML’ey. When building an application targeted to a FaaS platform it’s key to understand all the state-management options available to you in order to build a clean, high-performance, design.
Today, I am very happy to announce that QuickSight is now generally available in the N. When we announced QuickSight last year, we set out to help all customers—regardless of their technical skills—make sense out of their ever-growing data. Put simply, data is not always readily available and accessible to organizational end users.
Our A/B tests range across UI, algorithms, messaging, marketing, operations, and infrastructure changes. Due to compression and high performance computing, scientists can analyze billions of rows of raw data on their laptops using languages and statistical libraries they are familiar with like Python and R.
To learn about Analytics and Viz Engineering, have a look at Analytics at Netflix: Who We Are and What We Do by Molly Jackman & Meghana Reddy and How Our Paths Brought Us to Data and Netflix by Julie Beckley & Chris Pham. Curious to learn about what it’s like to be a DataEngineer at Netflix? Sensitivity analysis.
By J Han , PallaviPhadnis Context At Netflix, we use Amazon Web Services (AWS) for our cloud infrastructure needs, such as compute, storage, and networking to build and run the streaming platform that we love. Services can have multiple owners, cost heuristics are unique to each platform, and the scale of infra data is large.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content