This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions.
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
This holds true for the critical field of dataengineering as well. As organizations gather and process astronomical volumes of data, manual testing is no longer feasible or reliable. This comprehensive guide takes an in-depth look at automated testing in the dataengineering domain.
Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. Collecting raw impression events Filtering & Enriching Raw Impressions Once the raw impression events are queued, a stateless Apache Flink job takes charge, meticulously processing this data.
Analytics at Netflix: Who We Are and What We Do An Introduction to Analytics and Visualization Engineering at Netflix by Molly Jackman & Meghana Reddy Explained: Season 1 (Photo Credit: Netflix) Across nearly every industry, there is recognition that data analytics is key to driving informed business decision-making.
Optionally, this step can use the Write-Audit-Publish pattern to ensure that data is correct before it is made available to the rest of the company. A large number of our data users employ SparkSQL, pyspark, and Scala. some_db.source_table.yaml ??? sparksql_write.sql ??? test_sparksql_write.py agg(F.sum($"view_hours").as("view_hours"))
Netflix’s engineering culture is predicated on Freedom & Responsibility, the idea that everyone (and every team) at Netflix is entrusted with a core responsibility and they are free to operate with freedom to satisfy their mission. In the Efficiency space, our data teams focus on transparency and optimization.
Now, imagine yourself in the role of a software engineer responsible for a micro-service which publishes data consumed by few critical customer facing services (e.g. You are about to make structural changes to the data and want to know who and what downstream to your service will be impacted.
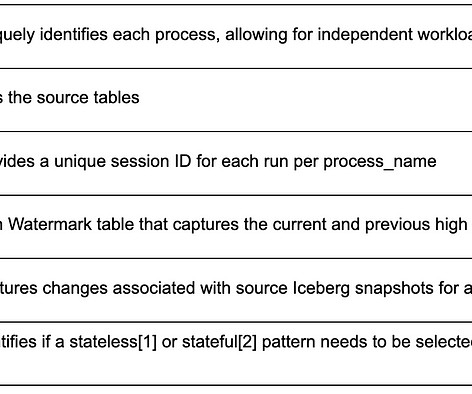
By Abhinaya Shetty , Bharath Mummadisetty In the inaugural blog post of this series, we introduced you to the state of our pipelines before Psyberg and the challenges with incremental processing that led us to create the Psyberg framework within Netflix’s Membership and Finance dataengineering team.
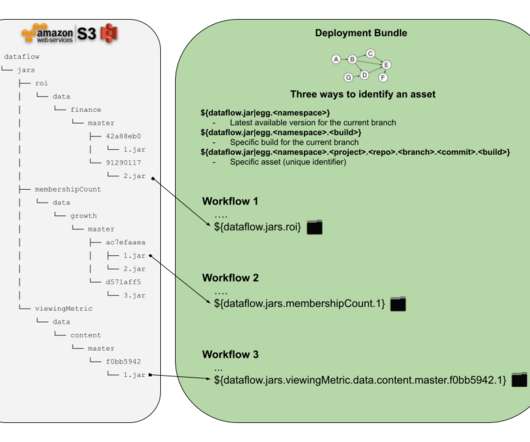
Let’s define some requirements that we are interested in delivering to the Netflix dataengineers or anyone who would like to schedule a workflow with some external assets in it. Conclusions This new method available for Netflix dataengineers makes workflow management easier, more transparent and more reliable.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Technology advancements in content creation and consumption have also increased its data footprint. We’ve compiled our speaking events below so you know what we’ve been working on.
At Netflix, our data scientists span many areas of technical specialization, including experimentation, causal inference, machine learning, NLP, modeling, and optimization. Together with data analytics and dataengineering, we comprise the larger, centralized Data Science and Engineering group.
More importantly, the low resource availability or “out of memory” scenario is one of the common reasons for crashes/kills. We at Netflix, as a streaming service running on millions of devices, have a tremendous amount of data about device capabilities/characteristics and runtime data in our big data platform.
Without these integrations, projects would be stuck at the prototyping stage, or they would have to be maintained as outliers outside the systems maintained by our engineering teams, incurring unsustainable operational overhead. Importantly, all the use cases were engineered by practitioners themselves.
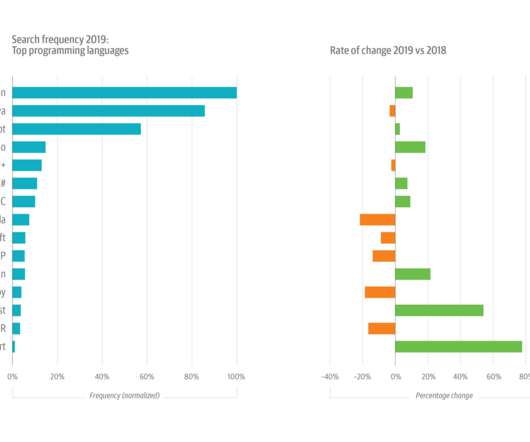
This year’s growth in Python usage was buoyed by its increasing popularity among data scientists and machine learning (ML) and artificial intelligence (AI) engineers. there’s a Python library for virtually anything a developer or data scientist might need to do. In aggregate, dataengineering usage declined 8% in 2019.
Some of the optimizations are prerequisites for a high-performance data warehouse. Sometimes DataEngineers write downstream ETLs on ingested data to optimize the data/metadata layouts to make other ETL processes cheaper and faster. It decides what to do and when to do in response to an incoming event.
Meson was based on a single leader architecture with high availability. Usability Netflix is a data-driven company, where key decisions are driven by data insights, from the pixel color used on the landing page to the renewal of a TV-series. The scheduler on-call has to closely monitor the system during non-business hours.
Talent and Expertise Shortages The rapid evolution of edge computing technologies has outpaced the availability of skilled professionals who can design, implement, and manage these systems effectively. Key issues include: A shortage of edge-native dataengineers and architects. High costs of training and retaining talent.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Throughout this evolution, we’ve been able to maintain high availability and a consistent message delivery rate, with Pushy successfully maintaining 99.999% reliability for message delivery over the last few months. When our partners want to deliver a message to a device, it’s our job to make sure they can do so.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Technology advancements in content creation and consumption have also increased its data footprint. We’ve compiled our speaking events below so you know what we’ve been working on.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Technology advancements in content creation and consumption have also increased its data footprint. We’ve compiled our speaking events below so you know what we’ve been working on.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
AWS recently announced the general availability (GA) of Amazon EC2 P5 instances powered by the latest NVIDIA H100 Tensor Core GPUs suitable for users that require high performance and scalability in AI/ML and HPC workloads. The GA is a follow-up to the earlier announcement of the development of the infrastructure. By Steef-Jan Wiggers
Network Availability: The expected continued growth of our ecosystem makes it difficult to understand our network bottlenecks and potential limits we may be reaching. As with any sustainable engineering design, focusing on simplicity is very important. The enriched data allows us to analyze networks across a variety of dimensions (e.g.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
However, the data infrastructure to collect, store and process data is geared toward developers (e.g., In AWS’ quest to enable the best data storage options for engineers, we have built several innovative database solutions like Amazon RDS, Amazon RDS for Aurora, Amazon DynamoDB, and Amazon Redshift.
Mei-Chin Tsai, Vinod discuss the internal architecture of Azure Cosmos DB and how it achieves high availability, low latency, and scalability. By Mei-Chin Tsai, Vinod Sridharan
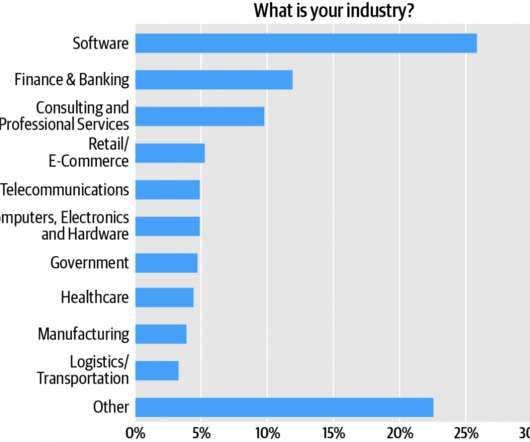
Software engineers comprise the survey audience’s single largest cluster, over one quarter (27%) of respondents (Figure 1). Adding architects and engineers, we see that roughly 55% of the respondents are directly involved in software development. Complexity is an engineering problem, and engineering problems are always about tradeoffs.
Kubernetes has emerged as go to container orchestration platform for dataengineering teams. In 2018, a widespread adaptation of Kubernetes for big data processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content