This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Combined with Dynatrace OneAgent ® , you gain a precise view of the status of your systems at a glance.
For years, enterprises managed observability data on a team-by-team basis , using a combination of ticketing systems and configuration management tools. Of course, the most important aspect of activating Dynatrace on Kubernetes is the incalculable level of value the platform unlocks. Flexible automation for Kubernetes observability.
The end goal, of course, is to optimize the availability of organizations’ software. Dynatrace is widely recognized for its AI capabilities’ ability to predict and prevent issues, and automatically identify root causes, maximizing availability. That’s where observability from Dynatrace goes far beyond “observing systems.”
Note that the developers of the respective services need to make these metrics available by exposing them via, for example, a Prometheus endpoint that can be used by the OpenTelemetry collector to ingest them and forward them to your Dynatrace tenant. This query confirms the suspicion that a particular product might be wrong.
While many large-scale environments use OpenShift Container Platform (OCP) as their Kubernetes distribution of choice, teams typically still lack intelligent observability and centralized alerting despite the monitoring system included with the platform. Of course this extension also comes with preconfigured alerts. What’s next?
As file sizes grow and workflows become more complex, these issues are magnified, leading to inefficiencies that slow down post-production and reduce the available time spent on creativework. Depending on the market, or production budget, cutting-edge technology might not be available or affordable. So what isit?
A simple and automated approach can help you stay on top of things and ensure your systems are available and secure. Finally, you can find pre-defined workflows to automate manual work by connecting seamlessly with external systems through our extensive range of connectors. Of course, seeing is believing.
This workshop is for you, designed to expand your knowledge and understanding of open-source observability tooling that is available to you today. Prometheus is an open-source systems monitoring and alerting tool kit that enables you to hit the ground running with discovering, collecting, and querying your observability today.
Many of these projects are under constant development by dedicated teams with their own business goals and development best practices, such as the system that supports our content decision makers , or the system that ranks which language subtitles are most valuable for a specific piece ofcontent.
Availability and Reliability are forms of dependability. Availability The degree to which a product or service is available for use when required. This means a system that is not merely available but is also engineered with extensive redundant measures to continue to work as its users expect.
This workshop is for you, designed to expand your knowledge and understanding of open-source observability tooling that is available to you today. Prometheus is an open-source systems monitoring and alerting tool kit that enables you to hit the ground running with discovering, collecting, and querying your observability today.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. Some disruption might occur, but it will be minimal.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. This guide delves into how these systems work, the challenges they solve, and their essential role in businesses and technology.
Then, of course, great online free courses (these two are for MongoDB 3.6 – not covering the latest features; updated versions should be released soon): M201 MongoDB Performance course. M312 Diagnostic and Debugging course. (I Some good videos on the topic: Solving MongoDB Performance Riddles with Systems Thinking.
Through the course of this text, I will share more information on this theorem and why it is important. By the time you’re done reading, you’ll also know why CAP may not be enough for modern-day systems. It is one of the most important laws currently in existence.
Over the course of the last year, we’ve incrementally extended the coverage of security policies to provide a common authorization mechanism for the entire Dynatrace platform. Having a configurable, flexible, and centralized system for authorization reduces management effort and allows you to handle complex authorization requirements.
The resulting outages wreaked havoc on customer experiences and left IT professionals scrambling to quickly find and repair affected systems. Dynatrace offers various out-of-the-box features and applications to provide a high-density overview of system health for all hosts and related metrics in a single view.
Why did the system behave differently? Three anomaly detection analyzers are available, each equipped with unique mechanisms to detect anomalies in your data that significantly deviate from the norm. Figure 5: Overview of anomaly detectors available within Davis Anomaly Detection. Why did we have an outage?
Due to separated systems that handle different parts of the process, the view of the process is fragmented. While some data comes from modern systems with APIs, other data stems from older systems that generate log files, and some data originates from external vendors. On top of that, the data sources are inconsistent.
Of course, this requires a VM that provides rock-solid isolation, and in AWS Lambda, this is the Firecracker microVM. To handle N parallel requests, N Lambda instances need to be available, and AWS will spin up up to 1000 such instances automatically to handle 1000 parallel requests. The virtual CPU is turned off.
And now, of course, given reports that Meta has trained Llama on LibGen, the Russian database of pirated books, one has to wonder whether OpenAI has done the same. This means we can compare the results for data that was publicly available against the results for data that was private but from the same book. He never did.
The fact is, Reliability and Resiliency must be rooted in the architecture of a distributed system. The subject line said: “Success Story: Major Issue in single AWS Frankfurt Availability Zone!” The problem started at 1:24PM PDT, with the services starting to become available again about 3 hours later. Ready to learn more?
Are the systems we rely on every day as reliable via the home internet connection? Example #1 Order System: No change in user or buyers’ behavior. Both types of users mentioned access the same system, the only difference is that employees access it via the internal network and externals through a public exposed URL.
Complex IT systems make it possible to buy your favorite pair of jeans online, pay your bills, or help you navigate. These systems produce an unimaginably huge amount of data. All the data bound to hosts is analyzed by the Davis AI causation engine and made available on custom dashboards and events pages. Dynatrace news.
In Part I , we introduced a High Availability (HA) framework for MySQL hosting and discussed various components and their functionality. Semisynchronous replication, which is natively available in MySQL, helps the HA framework to ensure data consistency and redundancy for committed transactions. rpl_semi_sync_master_timeout.
This translates to a large number of app configurations to toggle feature availability and optimize the in-app experience for each production. For our use-case, we’re configuring the availability of production, version, and region specific app feature sets. remotely configurable files that get downloaded to the device.
This workshop is for you, designed to expand your knowledge and understanding of open-source observability tooling that is available to you today. Prometheus is an open-source systems monitoring and alerting tool kit that enables you to hit the ground running with discovering, collecting, and querying your observability today.
The aforementioned principles have, of course, a major impact on the overall architecture. This architecture offers rich data management and analytics features (taken from the data warehouse model) on top of low-cost cloud storage systems (which are used by data lakes). Work with different and independent data types.
More capabilities will be released faster to General Availability (GA). Increased automation and other improvements along our continuous delivery pipeline—of course, including our own internal leveraging of Dynatrace—have helped us to raise the bar for every one of our 24 releases each year.
SLOs with an observation period of, for example, one week, are of course not overly affected by short-lived outliers. Teams who are primarily reactive in their approach therefore use SLOs to decide when the state of a system has become so bad that it requires intervention. Are you still “reacting to bad numbers”? Get started with SLOs.
Today’s highly dynamic, heterogeneous, and complex software systems require organizations to establish observability for all provided cloud-native services. Gathering performance metrics like memory usage from systems where an agent can’t be installed. Dynatrace news.
Imagine traditional support operations: for every alert detected by a monitoring system, a ticket is created in an ITSM solution, someone then takes action on the ticket, kicks-off activities until the situation is resolved and the ticket can be closed. For example, invoking a webhook that creates a ticket in an ITSM system.
As a strong supporter of open source and open standards, I’m aware that the wide availability of standards, open-source tools, and some newly coined terms are causing a lot of confusion. Distributed tracing describes the act of following a transaction through all participating applications (tiers) and sub-systems, such as databases.
With the average cost of unplanned downtime running from $300,000 to $500,000 per hour , businesses are increasingly using high availability (HA) technologies to maximize application uptime. Where a high availability design once worked well, it can no longer keep up with more complex requirements. there cannot be high availability.
GPU-based machine learning system crashes, and you don’t know why? All the data bound to hosts is analyzed by the Davis AI causation engine and made available on custom dashboards and events pages. In the course of his research, he developed a OneAgent NVML extension , which is now available under the MIT License.
For that, we focused on OpenTelemetry as the underlying technology and showed how you can use the available SDKs and libraries to instrument applications across different languages and platforms. We’d like to get deeper insight into the host, the underlying operating system, and any third-party services used by our application.
Kubernetes has taken over the container management world and beyond , to become what some say the operating system or the new Linux of the cloud. Of course , you might think, Kubernetes has auto-scaling capabilities so wh y should I bother about resource s ? But of course, there are many others. . Dynatrace news.
Operations teams want to make sure the system doesn’t break. DevOps and SRE engineers experience a lot of pressure to deliver applications faster and that adhere to standards like “ the five nines ” of availability, resulting in many new service level requirements. Charting the course with Keptn.
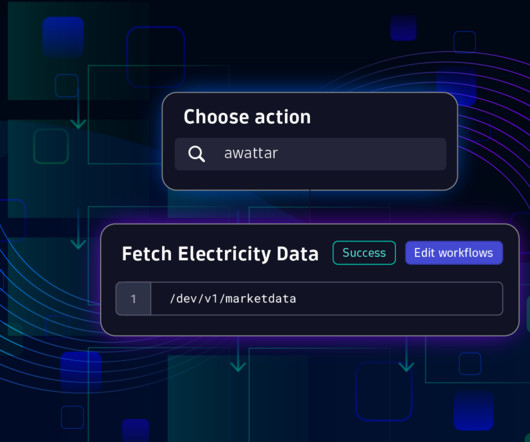
To address this challenge, the Dynatrace App Toolkit allows you to create custom workflow actions, providing seamless integration with third-party systems. Is there an API available for this purpose? This extends the capabilities of AutomationEngine for all users in your environment. What do you wish to automate?
Kubernetes can be a confounding platform for system architects. So rather than wait for the complete full-stack solution to be released, we’ll provide you with application-only observability as soon as it’s available. Dynatrace news. Microservice design principles force people to think along a spectrum of loose coupling.
IBM Z systems power billions of transactions each day and are used by most Fortune 500 companies. Over the years however, classic mainframe environments have been transformed, with their services frequently linked to distributed systems or an enterprise cloud. Dynatrace news. zIIP eligible time processed on general CPU.
Compared to intrusion detection systems (IDS/IPS), WAFs are focused on the application traffic. For most enterprises, using a RASP solution would mean running multiple agents on their production systems, potentially creating risk due to incompatibilities. WAFs protect the network perimeter and monitor, filter, or block HTTP traffic.
Application Performance Monitoring (APM) in its simplest terms is what practitioners use to ensure consistent availability, performance, and response times to applications. And this isn’t even the full extent of the types of monitoring tools available out there. ” How to evaluate a APM solution?
We continue to grow our public synthetic monitoring locations, but customers using Dynatrace Synthetic still need to monitor the performance and availability of internal web applications. With private synthetic browser monitors, we bring the testing capabilities available in public locations right into your own environment.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content