This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Of course, the most important aspect of activating Dynatrace on Kubernetes is the incalculable level of value the platform unlocks. The application consists of several microservices that are available as pod-backed services. Of course, everything is deployed using standard kubectl commands.
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Our script, available on GitHub , provides details. Are the corresponding services running on those hosts?
In addition to service-level monitoring, certain services within the OpenTelemetry demo application expose process-level metrics, such as CPU and memory consumption, number of threads, or heap size for services written in different languages. For this purpose, we’ll use the in-built failure scenarios included in the OpenTelemetry demo.
The end goal, of course, is to optimize the availability of organizations’ software. Dynatrace is widely recognized for its AI capabilities’ ability to predict and prevent issues, and automatically identify root causes, maximizing availability.
Unrealized optimization potential of business processes due to monitoring gaps Imagine a retail company facing gaps in its business process monitoring due to disparate data sources. Due to separated systems that handle different parts of the process, the view of the process is fragmented.
A lack of automation and standardization often results in a labour-intensive process across post-production and VFX with a lot of dependencies that introduce potential human errors and security risks. Depending on the market, or production budget, cutting-edge technology might not be available or affordable.
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. Data is then dynamically routed into pipelines for further processing. Commitment to privacy.
Controller Manager: Runs controllers such as the node controller responsible for handling node availability. Of course, you can also create your own custom alerts based on any metric displayed on a dashboard. Of course this extension also comes with preconfigured alerts. What’s next?
A simple and automated approach can help you stay on top of things and ensure your systems are available and secure. Of course, seeing is believing. On the Hub detail page, look for the Try in Playground link, which is available for many Dynatrace Apps.
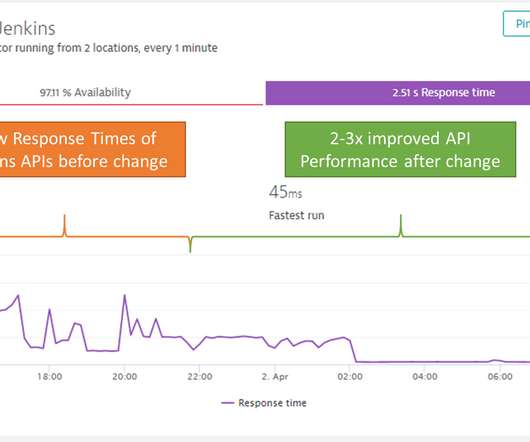
Dynatrace also alerted on intermittent outages throughout the day and especially after 8pm when the bulk of the nightly jobs were executed: On March 31st our Jenkins violated our SLAs from both availability and user experience.
Were excited to announce that Davis CoPilot Chat is now available across the Dynatrace platform. To help you navigate this and boost your efficiency, we’re excited to announce that Davis CoPilot Chat is now generally available (GA). Davis CoPilot can be accessed anytime directly from the Dock.
These blog posts, published over the course of this year, span a huge feature set comprising Davis 2.0, Follow transaction context and seamlessly analyze all the available full-stack information during root-cause detection. Key benefits of the Dynatrace Davis 2.0 AI causation engine. We opened up the Davis 2.0
The aforementioned principles have, of course, a major impact on the overall architecture. As a result, we created Grail with three different building blocks, each serving a special duty: Ingest and process. Ingest and process with Grail. Work with different and independent data types. Grail architectural basics. Retain data.
Of course, this example was easy to troubleshoot because were using a built-in failure simulation. The result of this query confirms our suspicion that there might be something wrong with a particular product, as all the errors seem to be caused by requests for a particular product ID: Figure 7.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
In Part I , we introduced a High Availability (HA) framework for MySQL hosting and discussed various components and their functionality. Semisynchronous replication, which is natively available in MySQL, helps the HA framework to ensure data consistency and redundancy for committed transactions. slave_preserve_commit_order = 1.
Of course, this requires a VM that provides rock-solid isolation, and in AWS Lambda, this is the Firecracker microVM. To handle N parallel requests, N Lambda instances need to be available, and AWS will spin up up to 1000 such instances automatically to handle 1000 parallel requests. The virtual CPU is turned off.
Three anomaly detection analyzers are available, each equipped with unique mechanisms to detect anomalies in your data that significantly deviate from the norm. Here, you can define the template for your event and describe all essential information for the subsequent process. We’re, of course, highly interested in your feedback.
The Dynatrace platform automatically integrates OpenTelemetry data, thereby providing the highest possible scalability, enterprise manageability, seamless processing of data, and, most importantly the best analytics through Davis (our AI-driven analytics engine), and automation support available. Seeing is believing.
The second major concern I want to discuss is around the data processing chain. The four stages of data processing. That brings me to the four stages of data processing which is another way of looking at the data processing chain. Four stages of data processing with a costly tool switch. Lost and rebuilt context.
Open a host, cluster, cloud service, or database view in one of these apps, and you immediately see logs alongside other relevant metrics, processes, SLOs, events, vulnerabilities, and data offered by the app. See for yourself Watch a demo of logs in context within various Dynatrace Apps in this Dynatrace University course.
Although Dynatrace can’t help with the manual remediation process itself , end-to-end observability, AI-driven analytics, and key Dynatrace features proved crucial for many of our customers’ remediation efforts. For example, a good course of action is knowing which impacted servers run mission-critical services and remediating those first.
OneAgent gives you all the operational and business performance metrics you need, from the front end to the back end and everything in between—cloud instances, hosts, network health, processes, and services. All the data bound to hosts is analyzed by the Davis AI causation engine and made available on custom dashboards and events pages.
The way we train juniors, whether it’s at university or in a boot camp or whether they train themselves from the materials we make available to them (Long Live the Internet), we imply from the very beginning that there’s a correct answer. It also helps us to better understand our own processes and update them where necessary.
Of course, you need to balance these opportunities with the business goals of the applications served by these hosts. And while these examples were resolved by just asking a few questions, in many cases, the answers are more elusive, requiring real-time and historical drill-downs into the processes and dependencies specific to each host.
Davis automatically analyzes and alerts on many important anomalies that can occur within your IT environment, such as host, process or service outages. How can you ensure that the measurements are always available and healthy? Still, you might have use cases that rely on important custom data streams. Seeing is believing.
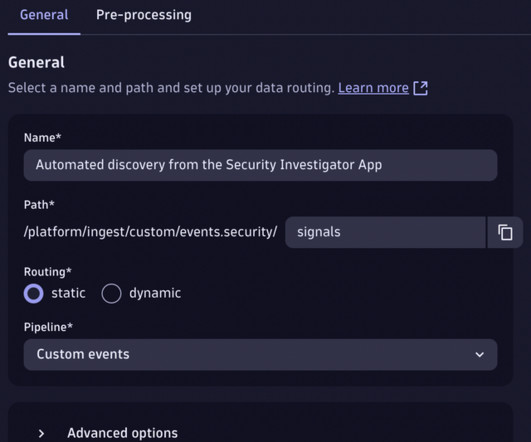
OpenPipeline allows you to create custom endpoints for data ingestion and process the events in the pipeline (for example, adding custom pipe-dependent fields to simplify data analysis in a later phase). Go to the Pre-processing tab and add a new processor with the type Add Fields. Ready to give this a shot yourself?
Configs can of course also be used within yourflow. The standard dictionary subscript notation is also available. You can see the actual command and args that were sub-processed in the Metaboost Execution section below. you can define arbitrary parsers using a string means the parser doesnt even have to be present remotely!
This, of course, is exacerbated by the new Vitals announcement, whereby data from the Chrome User eXperience Report will be used to aid and influence rankings. Every browser available on iOS is simply a wrapper around Safari. Of course, the whole point of this article is performance profiling, so let’s move over to the Network tab.
To provide you with more value when monitoring hosts in infrastructure mode, we’re extending our infrastructure mode with a range of metrics that have until now only been available in full-stack mode. Until now JMX and PMI extensions were only available in full-stack monitoring mode. Enabling JMX and PMI extensions. What’s next.
To make sure that Percona Backup for MongoDB answers the pains of our customers, we took the common denominator of the pains that anyone using snapshot capabilities faces when performing backups and restores and positioned PBM as the open source, freely available answer to those pains. I am happy to announce that with PBM 2.2.0,
Application Performance Monitoring (APM) in its simplest terms is what practitioners use to ensure consistent availability, performance, and response times to applications. And this isn’t even the full extent of the types of monitoring tools available out there.
DevOps and SRE engineers experience a lot of pressure to deliver applications faster and that adhere to standards like “ the five nines ” of availability, resulting in many new service level requirements. Developers also need to automate the release process to speed up deployment and reliability.
To find out this, he sent me the following Dynatrace screenshot that shows the number of actual successful order entries over the course of the last month. March 16 th – the first day of working-from-home – looks just as any other Monday: The first day of work-from-home didn’t have any negative impact on the successful orders process.
If you already have Dynatrace OneAgent in place, you can of course take advantage of the built-in OneAgent multidimensional metric API for ingestion of your OpenTelemetry custom metrics. Of course, all the ingested metrics are available to Davis AI and support auto-adaptive baselining or threshold-based alerting.
The subject line said: “Success Story: Major Issue in single AWS Frankfurt Availability Zone!” The problem started at 1:24PM PDT, with the services starting to become available again about 3 hours later. Fact #4: Multi-node, multi-availability zone deployment architecture. Ready to learn more?
Statoscope: A Course Of Intensive Therapy For Your Bundle. Statoscope: A Course Of Intensive Therapy For Your Bundle. At first, utilities for these tasks were available in the console, but not in the browser. This is all part of Webpack’s optimization process, in order to reduce the size of output assets. Sergey Melukov.
Dynatrace University is the team within Dynatrace that provides certification, self-paced micro-learning courses, and interactive instructor-led training. In the past, setting up all the hosts, clusters, and demo applications was a manual process that was very time consuming and error-prone. Dynatrace University. Automation.
A container (or a pod) running on a node may eat up all the available CPU or memory and affect all other pods on the node, degrading performance (or worse) and preventing any new workload to be scheduled on the node. Mentioned above, CPU is a compressible resource ; you can always allocate fewer or shorter CPU time slices to a process.
Is there an API available for this purpose? In an additional step, we can process the received data points and figure out the minimum. Most recent LTS version of js (version 20, as of May 2024). IDE or text editor of your choice (VS Code recommended) Now, consider your use case! What do you wish to automate?
Grail – the foundation of exploratory analytics Grail can already store and process log and business events. This is only possible because of our no-index approach and massive parallel processing capabilities, which enable Dynatrace to offer extra-long data retention (15+ months) at full granularity that is cost-efficient and fast.
Copies image layer into Docker image during build process. So rather than wait for the complete full-stack solution to be released, we’ll provide you with application-only observability as soon as it’s available. Pod uses an init container to download OneAgent. Can mount a volume to speed up injection for subsequent pods.
With the release of Dynatrace 1.194, we’ve added CPU related infrastructure metrics for LPARs (host metrics) and regions (process metrics) and expanded our multidimensional analysis to IBM Z systems, including CICS, IMS, and the CICS transaction gateway. . zIIP eligible time processed on general CPU.
For that, we focused on OpenTelemetry as the underlying technology and showed how you can use the available SDKs and libraries to instrument applications across different languages and platforms. This leads us to the process page of our specific Apache instance. And that’s where Dynatrace OneAgent comes in. What is OneAgent?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content