This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Our script, available on GitHub , provides details. into NAM test definitions.
To solve this problem , Dynatrace offers a fully automated approach to infrastructure and application observability including Kubernetes control plane, deployments, pods, nodes, and a wide array of cloud-native technologies. None of this complexity is exposed to application and infrastructure teams.
One of the promises of container orchestration platforms is to make i t easier for the developers to accelerate the deployment of their app lication s without having to worry about scalability and infrastructure dependencies. But of course, there are many others. . By default, containers run with unbounded limits.
The end goal, of course, is to optimize the availability of organizations’ software. Dynatrace is widely recognized for its AI capabilities’ ability to predict and prevent issues, and automatically identify root causes, maximizing availability. Automation, however, should not be done in isolation of tech.
As file sizes grow and workflows become more complex, these issues are magnified, leading to inefficiencies that slow down post-production and reduce the available time spent on creativework. Depending on the market, or production budget, cutting-edge technology might not be available or affordable. So what isit?
In those cases, what should you do if you want to be proactive and ensure that your infrastructure is always up and running? You could of course create a custom device in Dynatrace and send data to it using our API or an ActiveGate extension. Easy and flexible infrastructure monitoring. Platform extensions.
Infrastructure exists to support the backing services that are collectively perceived by users to be your web application. Issues that manifest themselves as performance degradation on a user’s device can often be traced back to underlying infrastructure issues. Dynatrace news. Monitor additional metrics.
Famous for providing out-of-the-box solutions, automation, and smart context across the entire application infrastructure with our unique Davis AI, Dynatrace now delivers two new extensions to assist teams that face the challenges associated with operating self-managed OCP installations. Control plane. What’s next?
All the data bound to hosts is analyzed by the Davis AI causation engine and made available on custom dashboards and events pages. In the course of his research, he developed a OneAgent NVML extension , which is now available under the MIT License. Looking for ways to solve some of your infrastructure-related problems?
In my last blog I covered how our Engineering Productivity (EP) and Infrastructure & Services (IAS) Teams are ensuring that our DevOps tool chain is running as expected, even while workloads have shifted as our global engineering teams are now working from home. Dynatrace news.
You can easily pivot between a hot Kubernetes cluster and the log file related to the issue in 2-3 clicks in these Dynatrace® Apps: Infrastructure & Observability (I&O), Databases, Clouds, and Kubernetes. Finding answers begins with opening the right app for your use case. A sudden drop in received log data?
These blog posts, published over the course of this year, span a huge feature set comprising Davis 2.0, Follow transaction context and seamlessly analyze all the available full-stack information during root-cause detection. Reduce alert spam by detecting root causes without infrastructure thresholds. AI causation engine.
Distributing accounts across the infrastructure is an architectural decision, as a given account often has similar usage patterns, languages, and sizes for their Lambda functions. Of course, this requires a VM that provides rock-solid isolation, and in AWS Lambda, this is the Firecracker microVM. file uploaded to AWS Lambda.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
Configs can of course also be used within yourflow. The standard dictionary subscript notation is also available. As a central ML and AI platform team, our role is to empower our partner teams with tools that maximize their productivity and effectiveness, while adapting to their specific needs (not the other way around).
Of course, you’ll return to it (or its amazing cousin, k9s) when you need to troubleshoot issues in Kubernetes, but don’t use it to manage your cluster. A single pod may consume all the CPU or memory available on the node, causing its neighbors to be starved of CPU or hit Out of Memory errors. What are resource limits?
For example, a good course of action is knowing which impacted servers run mission-critical services and remediating those first. The key information displayed on the standard Dynatrace Problems app and the Infrastructure and Operations App became the basis of their team’s remediation plan. Before a crisis. During a crisis.
For instance, traditional universities that had never offered virtual courses are now letting students learn remotely. These customizable learning paths are rightsized, continuously available, and can be easily reported on for either of these groups. Blended learning at scale. Here, they needed a blended learning approach.
The aforementioned principles have, of course, a major impact on the overall architecture. Just a few minutes after installation, you get all the performance metrics and log data you need to monitor IT infrastructure of any complexity—from front end to back end. Work with different and independent data types. But what does that mean?
How can you ensure that the measurements are always available and healthy? In order to detect all kinds of availability issues, you need AI-powered alerting for your third-party data sources, too. See the possible placeholders for the Synology example below: Limits safeguard the health of your monitoring infrastructure.
Using environment automation from both AWS and Dynatrace, supported by the AWS Infrastructure Event Management program , Dynatrace University successfully delivered the required environments – these were three times more than the conference the year before. Perform 2020 Infrastructure Setup. Quite impressive! The results.
Chances are that if you are using the latest Percona Monitoring and Management (PMM) version, you have seen the availability of the new Percona Database as a Service (DBaaS). Introducing the Percona DBaaS Infrastructure Creator, or Percona My Database as a Service (MyDBaaS). This tool creates the infrastructure in an AWS account.
Today we’re happy to announce, that with the release of Dynatrace version 1.198 (SaaS and Managed), auto-adaptive baseline extends beyond application performance (APM) metrics to include thousands of infrastructure and cloud metrics as well. Of course, we could define a static threshold for each disk within the IT system.
With integrated visibility from your back-end infrastructure to your end users’ devices, Dynatrace can uniquely identify and prioritize issues before they impact your business. Of course, “all access” doesn’t mean that everything is turned on all the time. You have access to Dynatrace capabilities when and where you need them.
Dynatrace supports full-stack monitoring for Kubernetes, from the application down to the infrastructure layer. However, if you don’t have access to the infrastructure layer, Dynatrace also provides the option of application-only monitoring. Automated rollout of application observability. As of OneAgent Operator v0.8.0,
More capabilities will be released faster to General Availability (GA). Increased automation and other improvements along our continuous delivery pipeline—of course, including our own internal leveraging of Dynatrace—have helped us to raise the bar for every one of our 24 releases each year.
With the release of Dynatrace 1.194, we’ve added CPU related infrastructure metrics for LPARs (host metrics) and regions (process metrics) and expanded our multidimensional analysis to IBM Z systems, including CICS, IMS, and the CICS transaction gateway. . zIIP eligible time processed on general CPU. Prerequisites.
Application Performance Monitoring (APM) in its simplest terms is what practitioners use to ensure consistent availability, performance, and response times to applications. And this isn’t even the full extent of the types of monitoring tools available out there. What sets Dynatrace apart? .”
SLOs with an observation period of, for example, one week, are of course not overly affected by short-lived outliers. These redundancies can of course create additional efforts and complexity. This works out-of-the-box because Dynatrace understands how all your application and infrastructure components depend on each other.
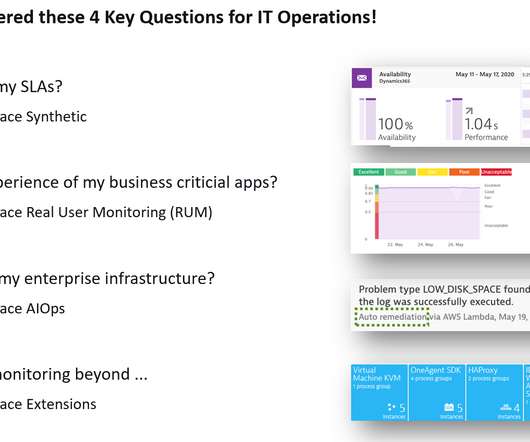
I posed these questions to a couple of friends and colleagues who are responsible for monitoring critical infrastructure and services and my friend Thomas and my colleagues from the Dynatrace Engineering Productivity shared the following stories and screenshots with me. Example #2 ensuring DevOps tool chain availability at Dynatrace.
This, of course, is exacerbated by the new Vitals announcement, whereby data from the Chrome User eXperience Report will be used to aid and influence rankings. Every browser available on iOS is simply a wrapper around Safari. Of course, the whole point of this article is performance profiling, so let’s move over to the Network tab.
With this approach, when available capacity of a critical resource is forecast to soon fall below acceptable levels, the operations team is notified with a single report, sent during business hours, well in advance of the resource actually experiencing a resource shortage. Select Filter and forecast for any chart line to start Davis Forecast.
Additionally, you don’t have to worry about scaling the Prometheus infrastructure because doesn’t even have to be collected by the Prometheus server. One of the advantages of the Prometheus ingest is that all the Prometheus labels will be available as dimensions in Dynatrace. Defining management zones. Create anomaly detection rules.
Whenever a performance problem is flagged, Infrastructure and Operations (I&O) practitioners strive to resolve the issue as soon as possible by identifying the root cause, understanding the impact, obtaining the relevant details, and fixing the issue within the shortest possible timeframe—the meantime to resolution (MTTR). Dynatrace news.
But end users kept complaining about slow applications, and despite increasing costs and control over networks, the baseline of end user experience wasn’t available. Application availability and performance measured using network probe technology. In 2012, we anticipated the shifts towards cloud infrastructures and microservices.
Other distributions like Debian and Fedora are available as well, in addition to other software like VMware, NGINX, Docker, and, of course, Java. This is especially the case with microservices and applications created around multiple tiers, where cheaper hardware alternatives play a significant role in the infrastructure footprint.
With the average cost of unplanned downtime running from $300,000 to $500,000 per hour , businesses are increasingly using high availability (HA) technologies to maximize application uptime. Where a high availability design once worked well, it can no longer keep up with more complex requirements. there cannot be high availability.
Synthetic monitoring locations execute browser and HTTP monitors from within your own infrastructure and answer questions about the availability of applications (internal and external) from the perspective of specific points of interest such as branch offices. Dynatrace news.
The way we train juniors, whether it’s at university or in a boot camp or whether they train themselves from the materials we make available to them (Long Live the Internet), we imply from the very beginning that there’s a correct answer. “This is the solution for printing the Fibonacci sequence using recursion.”
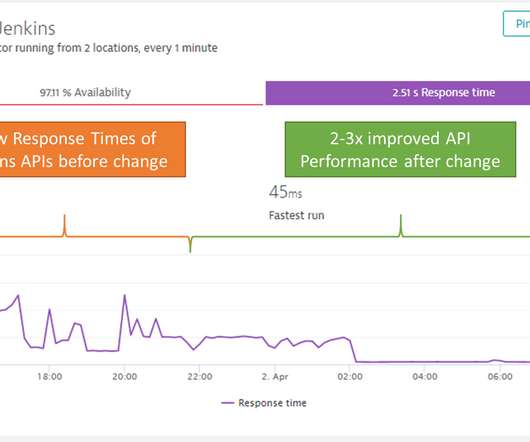
Dynatrace Synthetic allows you check the availability and performance for your business-critical applications. That’s why he setup Dynatrace Synthetic checks from the public available locations Frankfurt and Ohio as well as from their own Hamburg-based Data Center using Dynatrace Synthetic Private Locations.
This is a rather simple move as it doesn’t directly impact your infrastructure, just your contract with your electricity provider. Of course, you need to balance these opportunities with the business goals of the applications served by these hosts. The complication with this approach is that your energy bill will likely increase.
Data sources typically include common infrastructure monitoring tools and second-generation APM solutions as well as other solutions. And of course, this type of information needs to be available to the AI and therefore be part of the entity. The second major concern I want to discuss is around the data processing chain.
As an application owner, you need to ensure the continuous availability and performance of your applications from your end-users’ point of view. Sometimes, you need to check the availability of internal resources that aren’t accessible from outside your network. More information is available in Dynatrace Help.
The color of the line reflects the impact of the problem: infrastructure, service or application. The raw event data is available via API just like the problem data as well. Of course, this was only a quick remediation action. When you look closely you will notice quite some “noise” – lots of problems with a short duration.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content