This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
A decade ago, while working for a large hosting provider, I led a team that was thrown into turmoil over the purchasing of server and storage hardware in preparation for a multi-million dollar super-bowl ad campaign. The data had to be painstakingly stitched together over the course of a few weeks, across each layer of our stack.
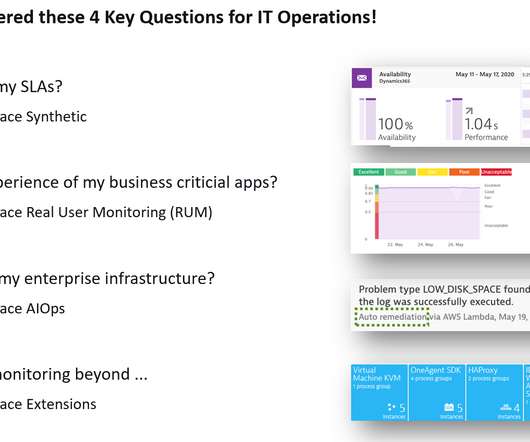
Synthetic monitoring locations execute browser and HTTP monitors from within your own infrastructure and answer questions about the availability of applications (internal and external) from the perspective of specific points of interest such as branch offices. Dynatrace news. In the near future, you can also expect support for: Ubuntu 18.
Other distributions like Debian and Fedora are available as well, in addition to other software like VMware, NGINX, Docker, and, of course, Java. This is especially the case with microservices and applications created around multiple tiers, where cheaper hardware alternatives play a significant role in the infrastructure footprint.
As an application owner, you need to ensure the continuous availability and performance of your applications from your end-users’ point of view. Sometimes, you need to check the availability of internal resources that aren’t accessible from outside your network. More information is available in Dynatrace Help.
The division by a power of two ( / (2 N )) can be implemented as a right shift if we are working with unsigned integers, which compiles to single instruction: that is possible because the underlying hardware uses a base 2. Of course, if d is not a power of two, 2 N / d cannot be represented as an integer. cycles per integer.
We continue to grow our public synthetic monitoring locations, but customers using Dynatrace Synthetic still need to monitor the performance and availability of internal web applications. With private synthetic browser monitors, we bring the testing capabilities available in public locations right into your own environment.
With the average cost of unplanned downtime running from $300,000 to $500,000 per hour , businesses are increasingly using high availability (HA) technologies to maximize application uptime. Where a high availability design once worked well, it can no longer keep up with more complex requirements. there cannot be high availability.
The short answers are, of course ‘all the time’ and ‘everyone’, but this mutual disownership is a common reason why performance often gets overlooked. Of course, it is impossible to fix (or even find) every performance issue during the development phase. Each have their own time, place, purpose, focus, and audience. Who: Engineers.
Dynatrace Synthetic allows you check the availability and performance for your business-critical applications. That’s why he setup Dynatrace Synthetic checks from the public available locations Frankfurt and Ohio as well as from their own Hamburg-based Data Center using Dynatrace Synthetic Private Locations. Summary & next steps.
Options 1 and 2 are of course the ‘scale out’ options, whereas option 3 is ‘scale up’. So we need low latency, but we also need very high throughput: A recurring theme in IDS/IPS literature is the gap between the workloads they need to handle and the capabilities of existing hardware/software implementations.
These guidelines work well for a wide range of applications, though the optimal settings, of course, depend on the workload. Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. I hope this helps!
Each cloud-native evolution is about using the hardware more efficiently. It's not because there are no other options available to them because of structural issues. Nitro is a revolutionary combination of purpose-built hardware and software designed to provide performance and security. Neither are clouds. It's a choice.
Balancing Low Latency, High Availability and Cloud Choice Cloud hosting is no longer just an option — it’s now, in many cases, the default choice. Let’s look at the top cloud computing use cases, the use cases for which cloud probably isn’t the best route available, and the use cases where a hybrid approach may be best.
An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., It’s a pretty impressive effort to pull together and make available in open source (not yet available as I write this) such a suite, and I’m sure explains much of the long list of 24 authors on this paper.
In general terms, here are potential trouble spots: Hardware failure: Manufacturing defects, wear and tear, physical damage, and other factors can cause hardware to fail. heat) can damage hardware components and prompt data loss. Human mistakes: Incorrect configuration is an all-too-common cause of hardware and software failure.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. Variations within these storage systems are called distributed file systems.
264/AVC, currently, the most ubiquitous video compression standard supported by modern devices, often in hardware. AOM has produced the reference software for AV1, which is called libaom and is available online. The first successful digital video standard was MPEG-2, which truly enabled digital transmission of video.
Krste Asanovic from UC Berkeley kicked off the main program sharing his experience on “ Rejuvenating Computer Architecture Research with Open-Source Hardware ”. He ended the keynote with a call to action for open hardware and tools to start the next wave of computing innovation. This year’s MICRO had three inspiring keynote talks.
Historically, NoSQL paid a lot of attention to tradeoffs between consistency, fault-tolerance and performance to serve geographically distributed systems, low-latency or highly available applications. A database should accommodate itself to different data distributions, cluster topologies and hardware configurations. Data Placement.
Most Linux users cannot afford the amount of resource large enterprises like Google put into custom Linux performance tuning… For Google of course, there’s an economy of scale that makes all that effort worth it. On the exact same hardware, the benchmark suite is then used to test 36 Linux release versions from 3.0
Below, I show measurements on comparable hardware for Amazon Redshift and three other vendors who have been recently claiming order-of-magnitude better performance and pricing. The code and scripts used by the Amazon Redshift team for benchmarking are available on GitHub and the accompanying dataset is hosted in a public Amazon S3 bucket.
Today, I'm happy to announce that the AWS Europe (Stockholm) Region, our 20th Region globally, is now generally available for use by customers. With this launch, AWS now provides 60 Availability Zones, with another 12 zones and four Regions expected to come online by 2020 in Bahrain, Cape Town, Hong Kong, and Milan.
This post mines publicly available data on the pace of compatibility fixes and feature additions to assess the claim. The information it captures is, however, available going back somewhat further, providing a fuller picture of the trend lines of engine completeness. Count of APIs available from JavaScript by Web Confluence.
As a result, there is a critical mass of data available. That is now changing, as packages of AI and ML services, frameworks and tools are today available to all sorts of companies and organizations, including those that don't have dedicated research groups in this field. They form the basis for new business models.
Mobile phones are rapidly becoming touchscreens and touchscreen phones are increasingly all-touch, with the largest possible display area and fewer and fewer hardware buttons. The hardware matters, but the underlying OS is the same , and pretty much all apps will run on any device of the same age. DRM-free, of course.
DRM-free, of course. Touch Design for Mobile Interfaces presents and shares real information on hardware, people, interactions, and environments. The eBook is available right away (PDF, ePUB, Amazon Kindle). DRM-free, of course. eBook is already available as PDF, ePUB, and Amazon Kindle. DRM-free, of course.
A year after the first web servers became available, how many companies had websites or were experimenting with building them? And of course, companies that don’t use AI don’t need an AI use policy. That pricing won’t be sustainable, particularly as hardware shortages drive up the cost of building infrastructure.
Upgrades are also rolled out progressively across the cluster of course. An out-of-band mechanism (tcp socket) is used to advertise the available wire protocol versions when connecting to a remote machine, and the lowest common denominator will be used. Then a short blackout period (200ms or less) cuts over to the new version.
Standardization is still important, of course, because it makes these improvements available portably, with portable guarantees for C++ code on all platforms. More things adopted for C++26: Core language changes/features Note: These links are to the most recent public version of each paper. Daniel Towner and Ruslan Arutyunyan.
Over the decade since [the introduction of Availability Zones], our thinking on failure and availability has continued to evolve, and we paid increasing attention to blast radius and correlation of failure. EBS uses chain replication for availability, with data flowing from client to primary to replica. Physalia in the large.
The current system assumes an application specific regression model is available on the servers which can predict processing time given the current parameters of the job (e.g. These use their regression models to estimate processing time (which will depend on the hardwareavailable, current load, etc.). in the cloud).
This paper presents Snowflake design and implementation along with a discussion on how recent changes in cloud infrastructure (emerging hardware, fine-grained billing, etc.) Of course, this has to be done whilst retaining strong isolation properties. From shared-nothing to disaggregation. of the persistent data on average.
MySQL, PostgreSQL, MongoDB, MariaDB, and others each have unique strengths and weaknesses and should be evaluated based on factors such as scalability, compatibility, performance, security, data types, community support, licensing rules, compliance, and, of course, the all-important learning curve if your choice is new to you.
They now allow users to interact more with the company in the form of online forms, shopping carts, Content Management Systems (CMS), online courses, etc. Web monitoring is a comprehensive term that describes the activity of testing a website or web application for its availability and performance. Hardware resources.
As we saw with the SOAP paper last time out, even with a fixed model variant and hardware there are a lot of different ways to map a training workload over the availablehardware. First off there still is a model of course (but then there are servers hiding behind a serverless abstraction too!). autoscaling).
This technique saves two instructions in the prologue and epilogue and makes one additional general-purpose register (%rbp) available." It was also a virtual machine that lacked low-level hardware profiling capabilities, so I wasn't able to do cycle analysis to confirm that the 10% was entirely frame pointer-based.
Inside the memory, they can be allocated any available space. When a program leaves the memory, space becomes available; however, the OS may or may not be able to allocate vacant memory space to another program or process as it has some issues. The next version of the pg_gather will have these details available.
Modern network performance and availability. Not as much as we'd like, of course, but the worldwide baseline has changed enormously. Hardware Past As Performance Prologue. There are differences, of course, but not where it counts. Here begins our 2021 adventure. Hard Reset. Advances in browser content processing.
Various standardized security methods are available. Penetration testing is comprehensively performed over a fully-functional system’s software and hardware. In addition to minimizing the risk of compromise to the system, the system’s configuration is also analyzed by validating checks on software and hardware.
Andrew Ng , Christopher Ré , and others have pointed out that in the past decade, we’ve made a lot of progress with algorithms and hardware for running AI. Our current set of AI algorithms are good enough, as is our hardware; the hard problems are all about data. The data available to our retail business is much more limited.
” This contains updated and new material that reflects the latest C++ standards and compilers, with a focus to using modern C++11/14/17 effectively on modern hardware and memory architectures. On April 25-27, I’ll be in Stockholm (Kista) giving a three-day seminar on “High-Performance and Low-Latency C++.”
The thrust of the argument is that there’s a chain of inter-linked assumptions / dependencies from the hardware all the way to the programming model, and any time you step outside of the mainstream it’s sufficiently hard to get acceptable performance that researchers are discouraged from doing so.
Pre-publication gates were valuable when better answers weren't available, but commentators should update their priors to account for hardware and software progress of the past 13 years. Fast forward a decade, and both the software and hardware situations have changed dramatically. Don't like the consequences?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content