This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Of course, the most important aspect of activating Dynatrace on Kubernetes is the incalculable level of value the platform unlocks. The application consists of several microservices that are available as pod-backed services. Of course, everything is deployed using standard kubectl commands.
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Our script, available on GitHub , provides details. into NAM test definitions.
The end goal, of course, is to optimize the availability of organizations’ software. Dynatrace is widely recognized for its AI capabilities’ ability to predict and prevent issues, and automatically identify root causes, maximizing availability. Watch the on-demand recording now.
Note that the developers of the respective services need to make these metrics available by exposing them via, for example, a Prometheus endpoint that can be used by the OpenTelemetry collector to ingest them and forward them to your Dynatrace tenant. This query confirms the suspicion that a particular product might be wrong.
Controller Manager: Runs controllers such as the node controller responsible for handling node availability. Of course, you can also create your own custom alerts based on any metric displayed on a dashboard. Of course this extension also comes with preconfigured alerts. What’s next?
Through the course of the EAP, we expect to gain further insight into iSeries host performance by ingesting additional metrics, events, and properties. The post IBM iSeries (AS/400) ActiveGate extension now available (EAP) appeared first on Dynatrace blog. Coming soon. Interested in joining the EAP?
As file sizes grow and workflows become more complex, these issues are magnified, leading to inefficiencies that slow down post-production and reduce the available time spent on creativework. Depending on the market, or production budget, cutting-edge technology might not be available or affordable. So what isit?
Of course, the ingested metrics are automatically presented using the same rich visualization tools, infographics, and reports through which we display information for all OneAgent-monitored technologies. The post Juniper Networks ActiveGate extension now available (EAP) appeared first on Dynatrace blog. Interested in joining the EAP?
A simple and automated approach can help you stay on top of things and ensure your systems are available and secure. Of course, seeing is believing. On the Hub detail page, look for the Try in Playground link, which is available for many Dynatrace Apps.
Were excited to announce that Davis CoPilot Chat is now available across the Dynatrace platform. To help you navigate this and boost your efficiency, we’re excited to announce that Davis CoPilot Chat is now generally available (GA). Davis CoPilot Chat will be available with the release of Dynatrace SaaS version 1.307.
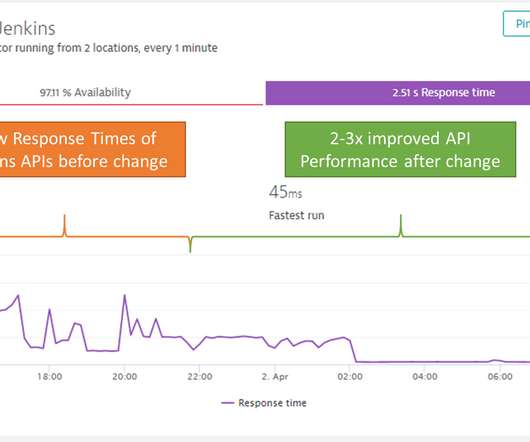
Dynatrace also alerted on intermittent outages throughout the day and especially after 8pm when the bulk of the nightly jobs were executed: On March 31st our Jenkins violated our SLAs from both availability and user experience.
This workshop is for you, designed to expand your knowledge and understanding of open-source observability tooling that is available to you today. Dive right into a free, online, self-paced, hands-on workshop introducing you to Prometheus.
Acceptance, of course, is not guaranteed, but its always worth a try! She also talked about the localization work shes doing, helping to translate the OTel docs into Portuguese as part of a larger effort to make the OTel docs available in a variety of languages. This was my second time attending, but my first time not as a speaker.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
This workshop is for you, designed to expand your knowledge and understanding of open-source observability tooling that is available to you today. Dive right into a free, online, self-paced, hands-on workshop introducing you to Prometheus.
Then, of course, great online free courses (these two are for MongoDB 3.6 – not covering the latest features; updated versions should be released soon): M201 MongoDB Performance course. M312 Diagnostic and Debugging course. (I Impact of Available IOPS On Your Database Performance. What is MongoDB FTDC (aka.
For instance, traditional universities that had never offered virtual courses are now letting students learn remotely. These customizable learning paths are rightsized, continuously available, and can be easily reported on for either of these groups. Blended learning at scale. Here, they needed a blended learning approach.
These blog posts, published over the course of this year, span a huge feature set comprising Davis 2.0, Follow transaction context and seamlessly analyze all the available full-stack information during root-cause detection. Key benefits of the Dynatrace Davis 2.0 AI causation engine.
Three anomaly detection analyzers are available, each equipped with unique mechanisms to detect anomalies in your data that significantly deviate from the norm. Figure 5: Overview of anomaly detectors available within Davis Anomaly Detection. We’re, of course, highly interested in your feedback.
And now, of course, given reports that Meta has trained Llama on LibGen, the Russian database of pirated books, one has to wonder whether OpenAI has done the same. This means we can compare the results for data that was publicly available against the results for data that was private but from the same book. He never did.
Of course, this example was easy to troubleshoot because were using a built-in failure simulation. The result of this query confirms our suspicion that there might be something wrong with a particular product, as all the errors seem to be caused by requests for a particular product ID: Figure 7.
Of course, this requires a VM that provides rock-solid isolation, and in AWS Lambda, this is the Firecracker microVM. To handle N parallel requests, N Lambda instances need to be available, and AWS will spin up up to 1000 such instances automatically to handle 1000 parallel requests. The virtual CPU is turned off.
In this post, we outline the best way to host MySQL on Azure , including managed solutions, instance types, high availability replication, backup, and disk types to use to optimize your cloud database performance. High Availability Deployment. So, how do we configure high availability for MySQL on Azure?
If you want Davis to alert on CSP violations only , excluding all other available request error types, or if you want to want to focus on CSP violations for specific pages , Dynatrace has you covered. CSP violations are fully available with Dynatrace version 1.217. Customization for automatic alerts tailored to your requirements.
Over the course of the last year, we’ve incrementally extended the coverage of security policies to provide a common authorization mechanism for the entire Dynatrace platform. Policy-based access control is also available within Cloud Automation. to give you more control over how your Dynatrace environments are configured.
The Dynatrace platform automatically integrates OpenTelemetry data, thereby providing the highest possible scalability, enterprise manageability, seamless processing of data, and, most importantly the best analytics through Davis (our AI-driven analytics engine), and automation support available. What is OpenTelemetry? Seeing is believing.
All the data bound to hosts is analyzed by the Davis AI causation engine and made available on custom dashboards and events pages. Dynatrace also takes care of load balancing between the available ActiveGates during deployment. will be available to all users as well. Why use Extensions. framework, you don’t have to worry.
This translates to a large number of app configurations to toggle feature availability and optimize the in-app experience for each production. For our use-case, we’re configuring the availability of production, version, and region specific app feature sets. remotely configurable files that get downloaded to the device.
To make sure that Percona Backup for MongoDB answers the pains of our customers, we took the common denominator of the pains that anyone using snapshot capabilities faces when performing backups and restores and positioned PBM as the open source, freely available answer to those pains. I am happy to announce that with PBM 2.2.0,
The aforementioned principles have, of course, a major impact on the overall architecture. This unique, end-to-end data collection, together with Smartscape ® topology mapping, ensures Grail is fueled with all available data—in context—and ready for manual or AI-driven analytics tasks. Work with different and independent data types.
Of course, you’ll return to it (or its amazing cousin, k9s) when you need to troubleshoot issues in Kubernetes, but don’t use it to manage your cluster. A single pod may consume all the CPU or memory available on the node, causing its neighbors to be starved of CPU or hit Out of Memory errors. What are resource limits?
How can you ensure that the measurements are always available and healthy? In order to detect all kinds of availability issues, you need AI-powered alerting for your third-party data sources, too. But how can you ensure that these data sources are always up and running? Seeing is believing. New to Dynatrace?
With the average cost of unplanned downtime running from $300,000 to $500,000 per hour , businesses are increasingly using high availability (HA) technologies to maximize application uptime. Where a high availability design once worked well, it can no longer keep up with more complex requirements. there cannot be high availability.
SLOs with an observation period of, for example, one week, are of course not overly affected by short-lived outliers. These redundancies can of course create additional efforts and complexity. SLO templates for the most popular use cases are available out-of-the-box. Are you still “reacting to bad numbers”? Learn more.
More capabilities will be released faster to General Availability (GA). Increased automation and other improvements along our continuous delivery pipeline—of course, including our own internal leveraging of Dynatrace—have helped us to raise the bar for every one of our 24 releases each year.
This workshop is for you, designed to expand your knowledge and understanding of open-source observability tooling that is available to you today. Dive right into a free, online, self-paced, hands-on workshop introducing you to Prometheus.
before the app’s key functionality is available, with almost half waiting over 3.5s! domContentLoadedEventStart And of course, we should be very used to seeing DOMContentLoaded at the bottom of DevTools’ Network panel: They’re some satisfying numbers. log ( window. performance. domContentLoadedEventStart - window. performance.
With this approach, when available capacity of a critical resource is forecast to soon fall below acceptable levels, the operations team is notified with a single report, sent during business hours, well in advance of the resource actually experiencing a resource shortage. Select Filter and forecast for any chart line to start Davis Forecast.
This, of course, is exacerbated by the new Vitals announcement, whereby data from the Chrome User eXperience Report will be used to aid and influence rankings. Every browser available on iOS is simply a wrapper around Safari. Of course, the whole point of this article is performance profiling, so let’s move over to the Network tab.
For example, a good course of action is knowing which impacted servers run mission-critical services and remediating those first. By simulating user interactions and running tests from various locations worldwide, synthetic monitoring provides a comprehensive view of application performance and availability. Before a crisis.
Through the course of this text, I will share more information on this theorem and why it is important. In short, the CAP theorem is a mathematical theorem describing how our application will behave in the event of network partitioning. It is one of the most important laws currently in existence.
The subject line said: “Success Story: Major Issue in single AWS Frankfurt Availability Zone!” The problem started at 1:24PM PDT, with the services starting to become available again about 3 hours later. Fact #4: Multi-node, multi-availability zone deployment architecture. Ready to learn more?
A container (or a pod) running on a node may eat up all the available CPU or memory and affect all other pods on the node, degrading performance (or worse) and preventing any new workload to be scheduled on the node. Of course , you might think, Kubernetes has auto-scaling capabilities so wh y should I bother about resource s ?
If you already have Dynatrace OneAgent in place, you can of course take advantage of the built-in OneAgent multidimensional metric API for ingestion of your OpenTelemetry custom metrics. Of course, all the ingested metrics are available to Davis AI and support auto-adaptive baselining or threshold-based alerting.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content