This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
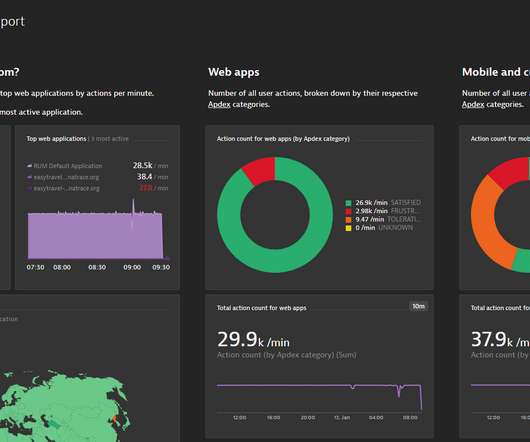
Thanks to the power of Grail, those details are available for all executions stored for the entire retention period during which synthetic results are kept. It now fully supports not only Network Availability Monitors but also HTTP synthetic monitors. Details of requests sent during each monitor execution are also available.
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Our script, available on GitHub , provides details. Overview and detailed requests comparison.
While Fluentd solves the challenges of collecting and normalizing Kubernetes events and logs, Kubernetes performance and availability problems can rarely be solved by investigating logs in isolation. All metrics, traces, and real user data are also surfaced in the context of specific events.
The second phase involves migrating the traffic over to the new systems in a manner that mitigates the risk of incidents while continually monitoring and confirming that we are meeting crucial metrics tracked at multiple levels. It provides a good read on the availability and latency ranges under different production conditions.
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. According to Google’s SRE handbook , best practices, there are “ Four Golden Signals ” we can convert into four SLOs for services: reliability, latency, availability, and saturation.
Consequently, this blog post highlights the new capability of the Site Reliability Guardian to define auto-adaptive thresholds that tackle the challenge of configuring static thresholds and protect your quality and security investments with relative comparisons to previous validations. For full details, see Dynatrace Documentation.
With dashboard subscriptions and scheduled reports, available as an Early Adopter Release with version 1.184, Dynatrace now makes your life substantially easier. Custom charts allow you to visualize metric performance over time, and USQL tiles allow you to dig deep into user session monitoring data. Next, select Enable reports.
Its design prioritizes high availability and efficient data transfer with minimal overhead, making it a practical choice for handling real-time data pipelines and distributed event processing. It follows a push-based approach, ensuring messages are distributed to consumers as soon as they become available.
By collecting and analyzing key performance metrics of the service over time, we can assess the impact of the new changes and determine if they meet the availability, latency, and performance requirements. The results are then evaluated using specific metrics to determine whether the hypothesis is valid.
Security vulnerabilities are checked throughout the lifecycle, including comparisons against previous releases. To enrich a release validation with security, simply add one of the out-of-the-box Dynatrace security metrics to your release validation dashboard. Further Managed deployment options will be released in a future release.
All of this convenient visibility is available with just a few clicks. The built-in unified analysis pages offer real-time comparison of key performance indicators while applying a topology-first approach to the data. Start monitoring in minutes. Begin network monitoring by simply deploying an extension with just a few clicks.
Symptoms : No data is provided for affected metrics on dashboards, alerts, and custom device pages populated by the affected extension metrics. These pages are now available to be used in security policies: Settings > Anomaly detection > Applications. General Availability (Build 1.231.196). Dashboards.
Service-level indicators (SLIs) are checked against your SLOs early in the lifecycle, including comparison against previous builds. Automated comparison of different timeframes based on SLIs and SLOs. Dynatrace Cloud Automation is currently only available for Dynatrace SaaS deployments. How the evaluation works.
Most monitoring tools for migrations, development, and operations focus on collecting and aggregating the three pillars of observability— metrics, traces, and logs. Using a data-driven approach to size Azure resources, Dynatrace OneAgent captures host metrics out-of-the-box to assess CPU, memory, and network utilization on a VM host.
Observability is a topic at the top of mind for all architects, Site Reliability Engineers (SREs), and more – each wanting to use observability to proactively detect issues and guarantee the best experience and availability to users. Metric 2: number of requests in error. Let’s start by creating a dashboard to follow our metrics.
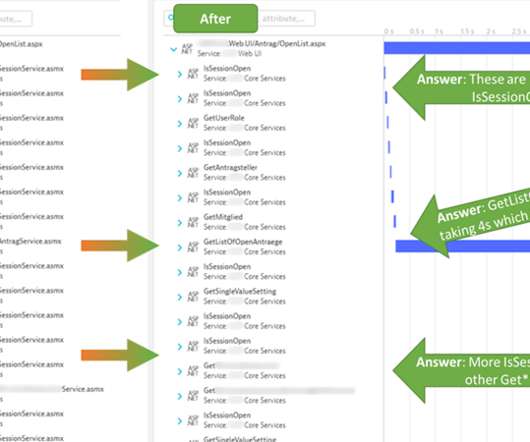
In Dynatrace, tagging also allows you to control access rights (via Management Zones), filter data on dashboards or via the API as well as allowing you to control calculation of custom service metrics or extraction of request attributes. This allows us to analyze metrics (SLIs) for each individual endpoint URL.
Having released this functionality in an Preview Release back in September 2019, we’re now happy to announce the General Availability of our Citrix monitoring extension. Synthetic monitoring: Citrix login availability and performance. These metrics help you understand whether your Citrix landscape is sized correctly for its load.
With the release of Dynatrace 1.177, you can now do exactly this—our most recent dashboarding update provides a powerful comparison feature for all available dashboard tiles. Compare metrics and KPIs over time. Comparisons over time are necessary for analyzing trends. Other improvements.
ESG metrics are increasingly important to investors as they evaluate risk; in turn, these metrics are increasingly important to organizations because they measure and disclose their performance. The app translates utilization metrics, including CPU, memory, disk, and network I/O, into their CO2 equivalent (CO2e).
In summary, simple randomization and mean comparison we typically utilize in A/B testing with millions of members may not work well for quasi experiments. getting closer to apples to apples comparison). We utilize the pre-intervention period to generate baselines for our metrics, and normalize post intervention values by the baseline.
SREs use Service-Level Indicators (SLI) to see the complete picture of service availability, latency, performance, and capacity across various systems, especially revenue-critical systems. Additionally, you can easily use any previously defined metrics and SLOs from your environments.
While Fluentd solves the challenges of collecting and normalizing Kubernetes events and logs, Kubernetes performance and availability problems can rarely be solved by investigating logs in isolation. All metrics, traces, and real user data are also surfaced in the context of specific events.
Bringing together metrics, logs, traces, problem analytics, and root-cause information in dashboards and notebooks, Dynatrace offers an end-to-end unified operational view of cloud applications. To observe model drift and accuracy, companies can use holdout evaluation sets for comparison to model data.
In a unified strategy, logs are not limited to applications but encompass infrastructure, business events, and custom metrics. A prime example is when a business analyst requests information about how many units of a product were sold within the last month or wants to perform a year-to-year comparison.
by Jason Koch , with Martin Spier , Brendan Gregg , Ed Hunter Improving the tools available to our engineers to help them diagnose, triage, and work through software performance challenges in the cloud is a key goal for the cloud performance engineering team at Netflix. or “are there noisy neighbors affecting my container task?”.
Organizations that have transitioned to agile software development strategies (including the adoption of a DevOps culture and continuous delivery automation) enforce automated solutions for such decision making—or at the very least, use automation in the gathering of a release-quality metrics.
At its core, data observability is about ensuring the availability, reliability, and quality of data. Scenario : For many B2B SaaS companies, the number of reported customers is an important metric. Value: KPIs and metrics such as the number of reported customers are central to an organization’s business and strategic processes.
As a Software Engineer, the mind is trained to seek optimizations in every aspect of development and ooze out every bit of available CPU Resource to deliver a performing application. There were languages I briefly read about, including other performance comparisons on the internet. These include Python, PHP, Perl, and Ruby.
In comparison, on-premises clusters have more and larger nodes: on average, 9 nodes with 32 to 64 GB of memory. That trend will likely continue as Kubernetes security awareness further rises and a new class of security solutions becomes available. Kubernetes infrastructure models differ between cloud and on-premises.
A bandit recommender system constructing a slate of K items may look like the following: A bandit style recommender system for slate construction To insert an element at slot k in the slate, the item scorer scores all of the available N items and may make use of the slate constructed so far (slate above) as additional context.
Because it’s critical that operations teams ensure that all internal resources are available for their users, synthetic monitoring of those resources is important. To stay in lockstep with container usage across industries, synthetic monitoring solutions are making tools available to cater to those trends.
In comparison, the AIOps approach discussed within this article, is built upon a radically different deterministic AI engine – at Dynatrace known as Davis – that yields precise, actionable results in real-time. metrics) but it’s just adding another dataset and not solving the problem of cause-and-effect certainty. Conclusion.
Modern observability has evolved from simple metric telemetry monitoring to encompass a wide range of data, including logs, traces, events, alerts, and resource attributes. The native multi-select feature lets users open a filtered group of problems simultaneously, facilitating quick comparisons and detailed analysis.
Allow for flexibility Custom query variables are available to fine-tune guardian objectives and maintain flexibility in fetching data from Grail. In many cases, you want to retrieve the logs, metrics, or traces of a particular version, which is unknown upfront. Fully functional and pre-configured guardian for a Kubernetes workload.
You’ll typically want to find a way to make a connection between a performance metric (such as First Meaningful Paint ) and a business metric (Conversion Rate). We’ve made your life easier by starting the comparison for you. The Simpsons Family = Web Performance Metrics. Percent Availability. Maggie Simpson.
Historically, NoSQL paid a lot of attention to tradeoffs between consistency, fault-tolerance and performance to serve geographically distributed systems, low-latency or highly available applications. However, consistency is a very expensive thing in distributed systems, so it can be traded not only to availability. Data Placement.
The challenge with ASP.NET Web Service Observability, Diagnostics and Performance Optimization is that most monitoring & diagnostic tools only provide global Service Level Indicators metrics (SLIs) such as response time, failure rate, and throughput, but not metrics for each individual service endpoint.
Perceptual quality measurements are used to drive video encoding optimizations , perform video codec comparisons , carry out A/B testing and optimize streaming QoE decisions to mention a few. In particular, the VMAF metric lies at the core of improving the Netflix member’s streaming video quality. Assembly for two of the metrics (e.g.
Technically, “performance” metrics are those relating to the responsiveness or latency of the app, including start up time. At Netflix the term “performance” usually encompasses both performance metrics (in the strict meaning) and memory metrics, and that’s how we’re using the term here. What do we mean by Performance?
What is the availability, configurability, and efficacy of each? ?️ In our specific examples above, the one-big-file pattern incurred 201ms of latency, whereas the many-files approach accumulated 4,362ms by comparison. The former makes for a simpler build step, but is it faster? ?️ That’s almost 22× more!
Therefore, it requires multidimensional and multidisciplinary monitoring: Infrastructure health —automatically monitor the compute, storage, and network resources available to the Citrix system to ensure a stable platform. Synthetic monitoring: Citrix login availability and performance. Dynatrace Extension: NetScaler performance.
HDR was launched at Netflix in 2016 and the number of titles available in HDR has been growing ever since. Bitrate versus quality comparison HDR-VMAF is designed to be format-agnostic — it measures the perceptual quality of HDR video signal regardless of its container format, for example, Dolby Vision or HDR10.
Easily compare and view trends on multiple metrics with the new visualization. Easily compare and view trends across multiple metrics. With the newly enhanced user sessions queries, you can query and display multiple metrics side-by-side in a bar or line chart. They’re available for all users by default.
This post will discuss how Studio Search supports querying the data available in these indices. The DSL supports specifying the search criteria as comparison expressions or inclusion/exclusion filters. Through the power of federation, users are then able to hydrate the search results with any data available in the federated graph.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content