This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The application consists of several microservices that are available as pod-backed services. This file is automatically configured with working defaults, but it can be easily modified using a code editor such as VS Code. Information about each of these topics will be available in upcoming announcements.
With the increasing amount of sensitive information stored and processed, it’s essential to ensure that systems are secure and protected against potential threats. The deep insights into application code provided by OneAgent® help track potentially vulnerable data flow within an application.
By leveraging Dynatrace observability on Red Hat OpenShift running on Linux, you can accelerate modernization to hybrid cloud and increase operational efficiencies with greater visibility across the full stack from hardware through application processes. Dynatrace observability is available for Red Hat OpenShift on IBM Power.
The IT world is rife with jargon — and “as code” is no exception. “As code” means simplifying complex and time-consuming tasks by automating some, or all, of their processes. ” While this methodology extends to every layer of the IT stack, infrastructure as code (IAC) is the most prominent example.
We’re excited to announce our verified HashiCorp Terraform integration is now available for Dynatrace customers. HashiCorp’s Terraform is an open-source infrastructure as a code software tool that provides a consistent CLI workflow to manage hundreds of cloud services. What is monitoring as code? Dynatrace news.
The end goal, of course, is to optimize the availability of organizations’ software. Hypermodal AI fuels automatic root-cause analysis to pinpoint the culprit amongst millions of service interdependencies and lines of code faster than humans can grasp. Dynatrace AI increases efficiency by magnitudes and prevents alert storms.
Modern infrastructure needs to be elastic and GitOps approaches are used to automate the provisioning of infrastructure and applications using Git, an open-source control system that provides the change processes including reviews and approvals. Key components of GitOps are declarative infrastructure as code, orchestration, and observability.
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. Data is then dynamically routed into pipelines for further processing. Commitment to privacy.
A production bug is the worst; besides impacting customer experience, you need special access privileges, making the process far more time-consuming. It also makes the process risky as production servers might be more exposed, leading to the need for real-time production data. This cumbersome process should not be the norm.
What developers want Developers want to own their code in a distributed, ephemeral, cloud, microservices-based environment. This ownership starts with understanding how their code behaves in all environments, resolving issues, and writing and optimizing code in a high-quality, secure, and timely manner.
By leveraging the Dynatrace Operator and Dynatrace capabilities on Red Hat OpenShift on IBM Power, customers can accelerate their modernization to hybrid cloud and increase operational efficiencies with greater visibility across the full stack from hardware through application processes.
Typically, the attackers attempt to exploit some weakness in the vendor’s development or delivery life cycle and attempt to inject malicious code before an application is signed and certified. It all starts with the code. Dynatrace has established a secure SDL, which automatically enforces that all developed code is reviewed by a peer.
One of the main reasons this feature exists is just like with food samples, to give you “a taste” of the production quality ETL code that you could encounter inside the Netflix data ecosystem. " , country_code STRING COMMENT "Country code of the playback session." This is one way to build trust with our internal user base.
Today, development teams suffer from a lack of automation for time-consuming tasks, the absence of standardization due to an overabundance of tool options, and insufficiently mature DevSecOps processes. This process begins when the developer merges a code change and ends when it is running in a production environment.
This process, known as auto-adaptive thresholding, eliminates the need to define a static threshold upfront. To provide automated feedback for developers, the concept of quality gates for static code analysis in continuous integration is widely adopted throughout the industry.
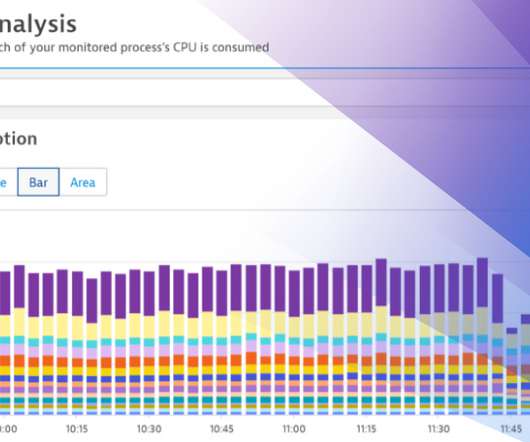
While in classic bare-metal stacks CPU resources are made “available” through over-provisioning, in modern SaaS environments you only pay for those CPU resources that you use—no over-provisioning of resources is required. Fully automated code-level visibility. Split analyzed workload by processes. Divide and conquer.
Dynatrace Simple Workflows make this process automatic and frictionlessthere is no additional cost for workflows. Why manual alerting falls short As your product and deployments scale horizontally and vertically, the sheer volume of data makes it impossible for teams to catch every error quickly using manual processes.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. Hence, having a dedicated dashboard tile visualizing the key parameters of each SLO simplifies the process of evaluating them.
With the help of open-source solutions and agile APIs, teams can now deliver and maintain code more efficiently than ever. In short, combining development and operations makes it possible for process to keep pace with progress. So, what does this combined process look like in practice? Solving for silos. Development potential.
To make this possible, the application code should be instrumented with telemetry data for deep insights, including: Metrics to find out how the behavior of a system has changed over time. And because Dynatrace can consume CloudWatch metrics, almost all your AWS usage information is available to you within Dynatrace.
Secondly, knowing who is responsible is essential but not sufficient, especially if you want to automate your triage process. Keeping ownership teams and their properties up to date is essential, as is having the right contact information available when needed. Dynatrace offers several ways to ingest ownership team information.
Dynatrace Configuration as Code enables complete automation of the Dynatrace platform’s configuration, ensuring that software is secure and reliable. With Configuration as Code, developers can manage their observability and security tasks with config files that can be developed alongside source code conveniently and at scale.
Save time by directly analyzing code-level information. With the unique code-level capabilities of Davis, we’ve reduced the number of clicks required to reach and understand code-level findings. Beyond traceability: From root cause to code-level context in a single click. We opened up the Davis 2.0
A key learning from the outage caused by the faulty CrowdStrike “Rapid Response” update is how critical it is to understand your vendors’ quality control and release processes. What is your testing process? code reviews, penetration testing)? A variety of events and circumstances can cause an outage. How often do you test it?
A Kubernetes-centric Internal Development Platform (IDP) enables platform engineering teams to provide self-service capabilities and features to their DevSecOps teams who need resilient, available, and secure infrastructure to build and deploy business-critical customer applications. Ensure that you get the most out of your product.
Most of these leverage the unique capability of Dynatrace OneAgent® to extract business data from in-flight application payloads — without writing any code. Dynatrace OpenPipeline is a new stream processing technology that ingests and contextualizes data from any source. Business process monitoring and optimization.
Dynatrace provides automatic and intelligent observability without touching any code through auto-instrumentation, thereby helping you to better understand potential issues that may impact your end users’ experience. All improvements are available with OneAgent version 1.217. Leverage the latest improvements today.
The Clouds app provides a view of all available cloud-native services. Logs in context, along with other details, are instantly available after selecting a resource. The reasons are easy to find, looking at the latest improvements that went live along with the general availability of the Logs app.
Your next challenge is ensuring your DevOps processes, pipelines, and tooling meet the intended goal. Let’s dive into how these metrics and DevOps KPIs can help your team perform better and deliver better code. Lead time for changes measures the amount of time it takes for committed code to get into production.
With the latest advances from Dynatrace, this process is instantaneous. Moreover, it is fast, powered by its massively parallel processing data lakehouse. As a result, organizations can reduce complexity, effort, and processing time to run powerful business analytics on exabytes of data in real time.
One issue that often complicates this process is the "noisy neighbor" problem. The sched_wakeup and sched_wakeup_new hooks are invoked when a process changes state from 'sleeping' to 'runnable.' ' They let us identify when a process is ready to run and is waiting for CPU time.
To achieve relevant insights, raw metrics typically need to be processed through filtering, aggregation, or arithmetic operations. Often referred to as calculated metrics (see Adobe Analytics and Google Analytics ), such metric processing takes one or more existing metrics as input to create a new user-defined metric.
Organizations can customize quality gate criteria to validate technical service-level objectives (SLOs) and business goals, ensuring early detection and resolution of code deficiencies. Ultimately, quality gates safeguard code viability as it advances through the delivery pipeline. But how do they function in practice?
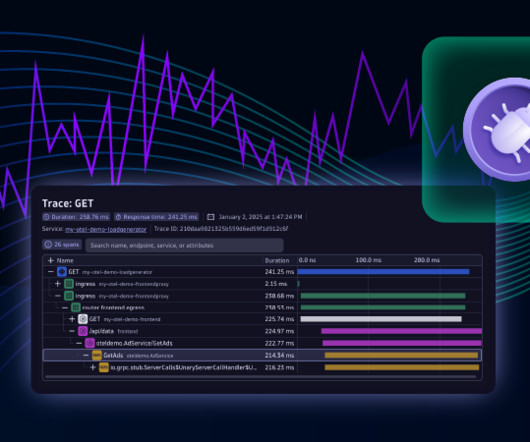
This link allows us to open Live Debugger and dive into the code level of the AdService (example service) without requiring code changes or application redeployments. We use the automatically populated filter for AdService and its corresponding source code repository, then select Done to go to Live Debugger.
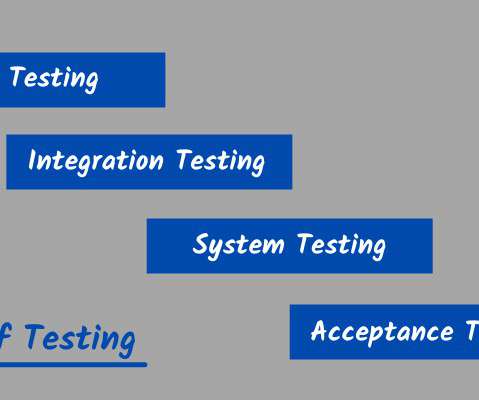
The goal of Levels of Testing is to make software testing more structured and efficient, as well as to make it easier to identify all available test cases and test scenarios at a given level. There are various steps in the SDLC paradigm, such as requirement gathering, analysis, coding, design, execution, testing, and deployment.
Container security is the practice of applying security tools, processes, and policies to protect container-based workloads. If containers are run with privileged flags, or if they receive details about host processes, they can easily become points of compromise for corporate networks. Source code tests. Image scanners.
Amazon compute solutions are designed to streamline resource provisioning and container management with two services: AWS Lambda : Lambda provides serverless compute infrastructure that lets you run code in response to predetermined events or conditions and automatically manage all compute resources required for these processes.
To further enrich log data for automated observability, it’s necessary to dynamically tie logs to distributed traces on the code level, user sessions in the app front-end, and the topology of your IT landscape. OneAgent processes rules precisely in this order, with host scope rules processed before host group and tenant scope rules.
Modern applications—enterprise and consumer—increasingly depend on third-party services to create a fast, seamless, and highly available experience for the end-user. API monitoring is the process of collecting and analyzing data about the performance of an API in order to identify problems that impact users. Dynatrace news.
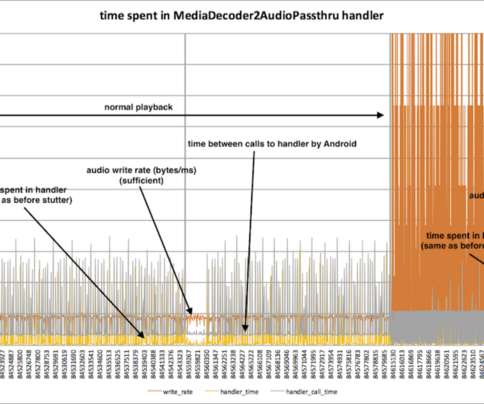
It provides a good read on the availability and latency ranges under different production conditions. Adding forking logic and complexity to the device code can create dependencies on device application release cycles that generally run at a slower cadence than service release cycles, leading to bottlenecks in the migration.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Shift-left using an SRE approach means that reliability is baked into each process, app and code change.
The integrator and Netflix had already completed the rigorous Netflix certification process, but during the TV operator’s internal trial an executive at the company reported a serious issue: Netflix playback on his device was “stuttering.”, They supplied a script to automate the process. Next I started reading the Ninja source code.
This increased efficiency applies to the most recent code committed to a repository to the final release and delivery of an application or service upgrade. Change failure rate is the percentage of DevOps code changes that lead to failure in production. What DevOps processes can be automated? Benefits of automation in DevOps.
Automatic data capture and display: More data, including span attributes, is available for out-of-the-box analysis, with no additional configuration necessary. To pinpoint the exact requests that are failing, the e-commerce team filters by excluding successful HTTP 200 status codes. The team can now dive deeper to find out why.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content