This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. While the SLO management web UI and API are already available, the dashboard tile will be released within the next weeks.
Imagine you’re using a lot of OpenTelemetry and Prometheus metrics on a crucial platform. A histogram is a specific type of metric that allows users to understand the distribution of data points over a period of time. You’re gathering a lot of data, but you can’t make sense of it. What are histograms, and why use them?
From a cost perspective, internal customers waste valuable time sending tickets to operations teams asking for metrics, logs, and traces to be enabled. A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. This approach is costly and error prone.
Most of these leverage the unique capability of Dynatrace OneAgent® to extract business data from in-flight application payloads — without writing any code. For years, logs have been the dominant approach many observability vendors have taken to report business metrics on dashboards.
For quite some time already, Dynatrace has provided full observability into AWS services by ingesting CloudWatch metrics that are published by AWS services. Amazon CloudWatch gathers metric data from various services that run on AWS. We’re happy to announce that Dynatrace is now a launch partner for Amazon CloudWatch Metric Streams.
The release candidate of OpenTelemetry metrics was announced earlier this year at Kubecon in Valencia, Spain. Since then, organizations have embraced OTLP as an all-in-one protocol for observability signals, including metrics, traces, and logs, which will also gain Dynatrace support in early 2023.
In an existing application landscape, however, it can be difficult to get to those metrics. Dynatrace customers have the ability to leverage PurePath distributed tracing functionality in driving adhoc multidimensional analysis (MDA) on any kind of data available within their microservices. Here’s how Dynatrace customers do it.
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. DevSecOps teams can tap observability to get more insights into the apps they develop, and automate testing and CI/CD processes so they can release better quality code faster.
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Like any IT or business project, you’ll need to track critical key metrics. Here are nine key DevOps metrics and DevOps KPIs that will help you be successful.
Telemetry data, such as traces and metrics, allow you to analyze the end-to-end performance of your deployed applications. It automates tasks such as provisioning and scaling Dynatrace monitoring components, updating configurations, and ensuring the health and availability of your monitoring infrastructure.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Boost your operational resilience: Combining availability and security is now essential.
Dynatrace has recently extended its Kubernetes operator by adding a new feature, the Prometheus OpenMetrics Ingest , which enables you to import Prometheus metrics in Dynatrace and build SLO and anomaly detection dashboards with Prometheus data. Here we’ll explore how to collect Prometheus metrics and what you can achieve with them.
One of these solutions is Micrometer which provides 17+ pre-instrumented JVM-based frameworks for data collection and enables instrumentation code with a vendor-neutral API. Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. That’s a large amount of data to handle. of Micrometer.
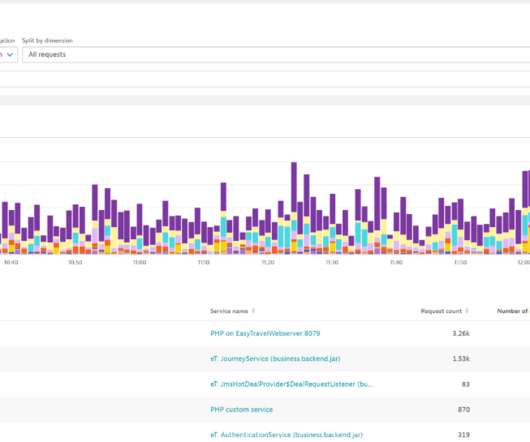
Metrics matter. But without complex analytics to make sense of them in context, metrics are often too raw to be useful on their own. To achieve relevant insights, raw metrics typically need to be processed through filtering, aggregation, or arithmetic operations. Examples of metric calculations. Dynatrace news.
To achieve the best visual outcome, we recommend experimenting with the available customization options. Use color coding to tell a story. While histograms look much like time-series bar charts, they’re different in that each bar represents a count (often termed frequency) of metric values. Try different cell shapes.
focused on technology coverage, building on the flexibility of JMX for Java and Python-based coded extensions for everything else. While Python code can address most data acquisition and ingest requirements, it comes at the cost of complexity in implementation and use-case modeling. Comprehensive metrics support Extensions 2.0
Your teams want to iterate rapidly but face multiple hurdles: Increased complexity: Microservices and container-based apps generate massive logs and metrics. You can select any trigger thats available for standard workflows, including schedules, problem triggers, customer event triggers, or on-demand triggers.
In Part 1 we explored how you can use the Davis AI to analyze your StatsD metrics. Part 2 showed how to run multidimensional analysis for external metrics that are ingested via the OneAgent Metric API. In Part 3 we discussed how the Davis AI can analyze your metrics from scripting languages like Bash or PowerShell.
Key components of GitOps are declarative infrastructure as code, orchestration, and observability. Many observability solutions don’t support an “as code” approach. Dynatrace enables software intelligence as code. Observability is required for effective collaboration and automation.
The end goal, of course, is to optimize the availability of organizations’ software. Hypermodal AI fuels automatic root-cause analysis to pinpoint the culprit amongst millions of service interdependencies and lines of code faster than humans can grasp. Dynatrace AI increases efficiency by magnitudes and prevents alert storms.
OpenTelemetry metrics are useful for augmenting the fully automatic observability that can be achieved with Dynatrace OneAgent. OpenTelemetry metrics add domain specific data such as business KPIs and license relevant consumption details. Enterprise-grade observability for custom OpenTelemetry metrics from AWS. Dynatrace news.
That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags. While classic logging is an essential tool in debugging issues, it often lacks context and only provides snapshot information of one specific location in your code/application. What is OpenTelemetry?
Dynatrace Synthetic Monitoring allows you to proactively monitor the availability of your public as well as your internal web applications and API endpoints from locations around the globe or important internal locations such as branch offices. Ensure better user experience with paint-focused performance metrics. Dynatrace news.
To ensure observability, the open source CNCF project OpenTelemetry aims at providing a standardized, vendor-neutral way of pre-instrumenting libraries and platforms and annotating UserLAnd code. New OpenTelemetry metrics exporters provide the broadest language support on the market.
Welcome back to the second part of our blog series on how easy it is to get enterprise-grade observability at scale in Dynatrace for your OpenTelemetry custom metrics. In Part 1 , we announced our new OpenTelemetry custom-metric exporters that provide the broadest language coverage on the market, including Go , .NET record(value); }.
A natural solution is to make flows configurable using configuration files, so variants can be defined without changing the code. Unlike parameters, configs can be used more widely in your flow code, particularly, they can be used in step or flow level decorators as well as to set defaults for parameters.
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
Save time by directly analyzing code-level information. With the unique code-level capabilities of Davis, we’ve reduced the number of clicks required to reach and understand code-level findings. Beyond traceability: From root cause to code-level context in a single click.
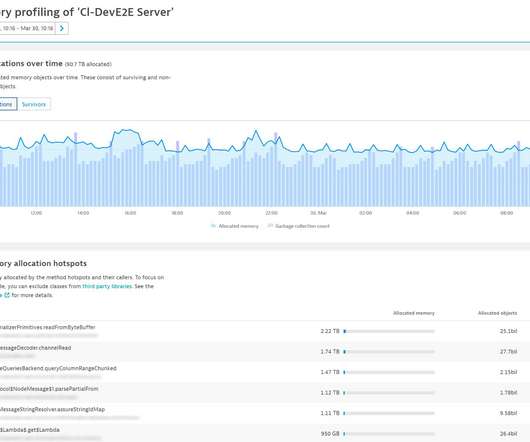
It prevents your application from fully leveraging the available CPU. Optimize your code by finding and fixing the root cause of garbage collection problems. These details arm you with the knowledge necessary to find the respective code and remove unnecessary allocations. This resource is not available to your application. .
Metrics that offer measurable, repeatable insight into the user experience from the moment they arrive on a website from a mobile or desktop device. Great user experiences start with Core Web Vitals (CWVs) — a set of metrics defined by Google to help measure user experience at scale. When do these metrics matter?
To provide automated feedback for developers, the concept of quality gates for static code analysis in continuous integration is widely adopted throughout the industry. The developer must pause their current engineering work to address the reported issue and consider the code changes they worked on a few days or weeks prior.
Captures metrics, traces, logs, and other telemetry data in context. Smartscape topology mapping: Dynatrace uses its Smartscape technology to semantically map metrics, traces, logs, and real user data to specific Kubernetes objects, including containers, pods, nodes, and services.
To make this possible, the application code should be instrumented with telemetry data for deep insights, including: Metrics to find out how the behavior of a system has changed over time. And because Dynatrace can consume CloudWatch metrics, almost all your AWS usage information is available to you within Dynatrace.
The second phase involves migrating the traffic over to the new systems in a manner that mitigates the risk of incidents while continually monitoring and confirming that we are meeting crucial metrics tracked at multiple levels. It provides a good read on the availability and latency ranges under different production conditions.
To emit a run queue latency metric, we leveraged three eBPF hooks: sched_wakeup, sched_wakeup_new, and sched_switch. There are kfuncs available to lock and unlock RCU read-side critical sections. When a cgroup ID correlates with a container, we emit a percentile timer Atlas metric (runq.latency) for that container.
Dynatrace has offered a Lambda code module for Node.js To handle N parallel requests, N Lambda instances need to be available, and AWS will spin up up to 1000 such instances automatically to handle 1000 parallel requests. A cold start occurs when there’s no instance of the requested Lambda function available.
Spring also introduced Micrometer, a vendor-agnostic metric API with rich instrumentation options. Soon after, Dynatrace built a registry for exporting Micrometer metrics. Our data APIs, which ingest millions of metrics, traces, and logs per second, are reconciled using Micrometer-based metrics.
Open-source metric sources automatically map to our Smartscape model for AI analytics. We’ve just enhanced Dynatrace OneAgent with an open metric API. Here’s a quick overview of what you can achieve now that the Dynatrace Software Intelligence Platform has been extended to ingest third-party metrics. Dynatrace news.
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. According to Google’s SRE handbook , best practices, there are “ Four Golden Signals ” we can convert into four SLOs for services: reliability, latency, availability, and saturation.
Dynatrace security notification integration with Jira is now available. The maximum number of metrics per chart has been increased from 5 to 10. When you select a metric, an overview of the highlighted metric is now displayed. Calculated application, log, and service metrics now consume Davis data units (Metrics pool).
Dynatrace is the only Kubernetes monitoring solution that provides continuous automation and full-stack advanced observability without changing code, container images, or deployments. A pending pod is one that’s already available in the Kubernetes system but not yet successfully running on a node. Dynatrace news.
A Kubernetes-centric Internal Development Platform (IDP) enables platform engineering teams to provide self-service capabilities and features to their DevSecOps teams who need resilient, available, and secure infrastructure to build and deploy business-critical customer applications. All this can be self-defined in the source code.
Organizations can customize quality gate criteria to validate technical service-level objectives (SLOs) and business goals, ensuring early detection and resolution of code deficiencies. Automating quality gates is ideal, as it minimizes manually checking and validating key metrics throughout the SDLC.
Red Hat just announced the availability of their OpenShift 4.0 So Dynatrace is now available as a certified operator in the OpenShift OperatorHub, a pool of high-quality operators for managing Kubernetes-native deployments. These enhancements include: Integration of the new Kubernetes/OpenShift cluster metrics with custom charting.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content