This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. Are you experiencing an increase or degradation in certain events that indicate a rising problem?
Business events: Delivering the best data It’s been two years since we introduced business events , a special class of events designed to support even the most demanding business use cases. Business event ingestion and analysis with log files. OpenPipeline: Simplify access and unify business events from anywhere.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
You can select any trigger thats available for standard workflows, including schedules, problem triggers, customer event triggers, or on-demand triggers. Here, you can select a specific event or a timed trigger like a cronjob. You can learn more about event triggers in Dynatrace Documentation. Its as simple as that!
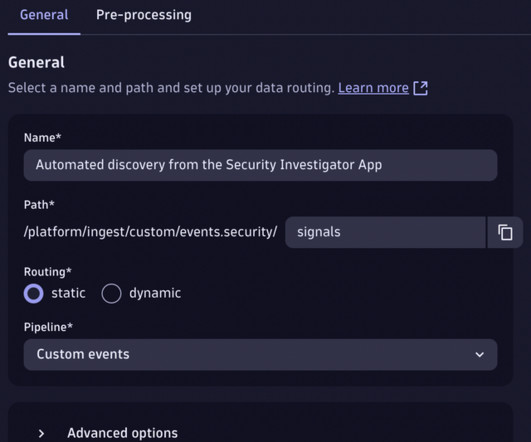
You now want to detect such events automatically by creating a custom Dynatrace security event. Ingest query results as security events The simplest way to do this is to use Dynatrace OpenPipeline. Set up a custom pipeline The best way to set up a security event ingestion to Dynatrace is via Dynatrace OpenPipeline.
The application consists of several microservices that are available as pod-backed services. This file is automatically configured with working defaults, but it can be easily modified using a code editor such as VS Code. Information about each of these topics will be available in upcoming announcements.
The first part of this blog post briefly explores the integration of SLO events with AI. Consequently, the AI is founded upon the related events, and due to the detection parameters (threshold, period, analysis interval, frequent detection, etc), an issue arose. In other words, where the application code resides.
Business events powered by our new Grail™ data lakehouse and by other Dynatrace platform technologies ensures the real-time precision that business and IT teams need to make data-driven decisions and improve business outcomes. Business events deliver the industry’s broadest, deepest, and easiest access to your critical business data.
In many cases, events are generated as these workloads go through different phases of their life cycles. For instance, events appear when the scheduler performs actions to bring workloads back to a desired state. For better or worse, every Kubernetes user learns about the CrashLoopBackOff and ImagePullBackOff events.
It automates tasks such as provisioning and scaling Dynatrace monitoring components, updating configurations, and ensuring the health and availability of your monitoring infrastructure. Dynatrace code modules, enabled via Dynatrace webhook, provide distributed tracing and code-level visibility for applications deployed on Kubernetes.
Business events are a special class of events, new to Business Analytics; together with Grail, our data lakehouse, they provide the precision and advanced analytics capabilities required by your most important business use cases. What are business events? This diagram shows a few examples of business events.
The end goal, of course, is to optimize the availability of organizations’ software. Hypermodal AI fuels automatic root-cause analysis to pinpoint the culprit amongst millions of service interdependencies and lines of code faster than humans can grasp. Dynatrace AI increases efficiency by magnitudes and prevents alert storms.
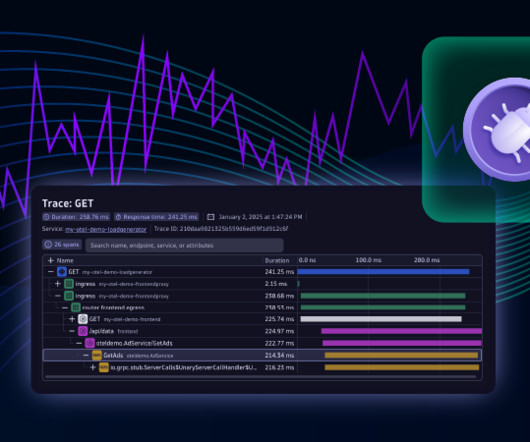
Upon detecting a high CPU load, Davis AI generates a problem event and populates it with a direct link to Live Debugger. This link allows us to open Live Debugger and dive into the code level of the AdService (example service) without requiring code changes or application redeployments.
On the other hand, deploying new code on the backend is complex and offers no such transparency. With Dynatrace Live Debugger, you can set a non-breaking breakpoint and instantly see if new code is following the intended new paths, if any new arguments are being considered, and if input and output arguments are aligned with expectations.
Leveraging code-level insights and transaction analysis, Dynatrace Runtime Application Protection automatically detects attacks on applications in your environment. Site Reliability Guardian provides an automated change impact analysis to validate service availability, performance, and capacity objectives across various systems.
A utomatic detection of software service and application availability (including microservices and containers) . Automatic detection of service health and performance incidences, which are synchronized into the Event Management Dashboard. . Prioritize event entries . Improved service availability.
By adding Flutter support, we’re giving you more freedom to choose what best fits your use case and available resources. User actions in Dynatrace are more than just simple events. When you set up user actions in your code, OneAgent automatically links associated web requests to those user actions. What’s next.
Load and DOMContentLoaded are internal browser events—your users have no idea what a Load time even is. Equally, both DOMContentLoaded and Load aren’t just meaningless browser events, and once you understand what they actually signify, you can get some real insights as to your site’s runtime behaviour from each of them. That’s late!
Save time by directly analyzing code-level information. With the unique code-level capabilities of Davis, we’ve reduced the number of clicks required to reach and understand code-level findings. Beyond traceability: From root cause to code-level context in a single click. We opened up the Davis 2.0
It prevents your application from fully leveraging the available CPU. Optimize your code by finding and fixing the root cause of garbage collection problems. These details arm you with the knowledge necessary to find the respective code and remove unnecessary allocations. This resource is not available to your application. .
In a MySQL master-slave high availability (HA) setup, it is important to continuously monitor the health of the master and slave servers so you can detect potential issues and take corrective actions. If the exit code indicates a failure, the return code from MySQL will tell us the failure reason.
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. Code : The branch for the new feature in a GitHub repository is merged into the main branch.
Code changes are often required to refine observability data. This results in site reliability engineers nudging development teams to add resource attributes, endpoints, and tokens to their source code. Kubernetes workload pages offer resource analysis, lists of services, pods, events, and logs.
To make this possible, the application code should be instrumented with telemetry data for deep insights, including: Metrics to find out how the behavior of a system has changed over time. Logs represent event data in plain-text, structured or binary format. Traces help find the flow of a request through a distributed system.
During this event, we generate a timestamp and store it in an eBPF hash map using the process ID as the key. There are kfuncs available to lock and unlock RCU read-side critical sections. Each event includes a run queue latency sample with a cgroup ID, which we associate with running containers on the host.
It automates tasks such as provisioning and scaling Dynatrace monitoring components, updating configurations, and ensuring the health and availability of the monitoring infrastructure. It also detects new containers and injects OneAgent code modules into application pods.
Dynatrace Configuration as Code enables complete automation of the Dynatrace platform’s configuration, ensuring that software is secure and reliable. With Configuration as Code, developers can manage their observability and security tasks with config files that can be developed alongside source code conveniently and at scale.
Lack of data: In many cases, available data may not be enough to make informed decisions due to data silos, distribution, or negligence. Easy workflow creation and maintenance Dynatrace Workflows provides workflow automation capabilities with an intuitive drag-and-drop UI and a no-code, low-code approach.
Deploy stage In the deployment stage, the application code is typically deployed in an environment that mirrors the production environment. This step is crucial as this environment is used for the final validation and testing phase before the code is released into production. This approach effectively combats configuration drift.
Since becoming General Availability in the fall of 2019 , GitHub Actions has helped teams automate continuous integration and continuous delivery (CI/CD) workflows for code builds, tests, and deployments. Example #1 – Deploy application code to Kubernetes. Example #2 – Deployment information events. Annotation.
A natural solution is to make flows configurable using configuration files, so variants can be defined without changing the code. Unlike parameters, configs can be used more widely in your flow code, particularly, they can be used in step or flow level decorators as well as to set defaults for parameters.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
Logs and events play an essential role in this mix; they include critical information which can’t be found anywhere else, like details on transactions, processes, users and environment changes. Without user transactions and experience data, in relation to the underlying components and events, you miss critical context.
With this enhancement, Dynatrace can respond to any event and execute synthetic monitors within your workflows to assess the impact of events on user experience. You can also provide a list of monitors, tags, or applications in the incoming event and extract the list using the expression , which allows you to build a generic Workflows.
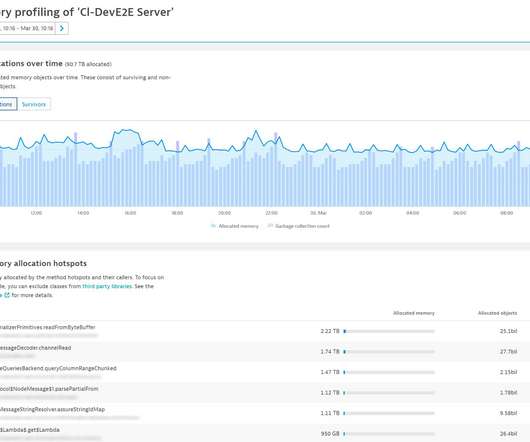
At Netflix, we periodically reevaluate our workloads to optimize utilization of available capacity. We turned to JVM-specific profiling, starting with the basic hotspot stats, and then switching to more detailed JFR (Java Flight Recorder) captures to compare the distribution of the events. let’s call it GS2?—?to
Managing Auto-Instrumentation in Pods The Operator automatically injects and configures auto-instrumentation for your applications, which enables you to collect telemetry data without modifying your source code. There are two versions available: v1alpha1 : apiVersion: opentelemetry.io/v1alpha1 spec.containers[*].name}'
Amazon compute solutions are designed to streamline resource provisioning and container management with two services: AWS Lambda : Lambda provides serverless compute infrastructure that lets you run code in response to predetermined events or conditions and automatically manage all compute resources required for these processes.
It receives binary log events from the master, does not apply these events, but serves them to all the other slaves. There are a limited set of commands that are supported which you can see directly in the source code on the mysql-ripple GitHub page. Encountered event Gtid, relay-log name /mysql_data/relaylogs/relay-log.000005,
To provide automated feedback for developers, the concept of quality gates for static code analysis in continuous integration is widely adopted throughout the industry. The developer must pause their current engineering work to address the reported issue and consider the code changes they worked on a few days or weeks prior.
Dynatrace has offered a Lambda code module for Node.js To handle N parallel requests, N Lambda instances need to be available, and AWS will spin up up to 1000 such instances automatically to handle 1000 parallel requests. A cold start occurs when there’s no instance of the requested Lambda function available.
Impact : This issue affects only those extensions that use native libraries called from Python code distributed with the extension. Removed seven-day preview from create/edit custom event for alerting pages. These pages are now available to be used in security policies: Settings > Anomaly detection > Applications.
The Qualys Threat Research Unit (TRU) has discovered a Remote Unauthenticated Code Execution (RCE) vulnerability in OpenSSH server (sshd) in glibc-based Linux systems. Look for timeout events Exploitation attempts for this vulnerability can be identified by many lines of “Timeout before authentication” in the logs.
A series of such actions can be combined into a GitHub workflow that can be triggered whenever new code is committed or when a new release tag is pushed to a repository. The purpose-built Dynatrace GitHub Action is available on the GitHub Marketplace in the monitoring category.
Developer tools for building container images : Docker Build creates a container image, the blueprint for a container, including everything needed to run an application – the application code, binaries, scripts, dependencies, configuration, environment variables, and so on. Event logs for ad-hoc analysis and auditing. Observability.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content