This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Compressing them over the network: Which compression algorithm, if any, will we use? What is the availability, configurability, and efficacy of each? ?️ Caching them at the other end: How long should we cache files on a user’s device? Cache This is the easy one. main.af8a22.css main.af8a22.css
Caching is the process of storing frequently accessed data or resources in a temporary storage location, such as memory or disk, to improve retrieval speed and reduce the need for repetitive processing. Bandwidth optimization: Caching reduces the amount of data transferred over the network, minimizing bandwidth usage and improving efficiency.
For the longest time now, I have been obsessed with caching. I think every developer of any discipline would agree that caching is important, but I do tend to find that, particularly with web developers, gaps in knowledge leave a lot of opportunities for optimisation on the table. Want to know everything (and more) about HTTP cache?
We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe. The cache is kept in sync with the current leader process. How do I know that my cache is up to date? of the data.
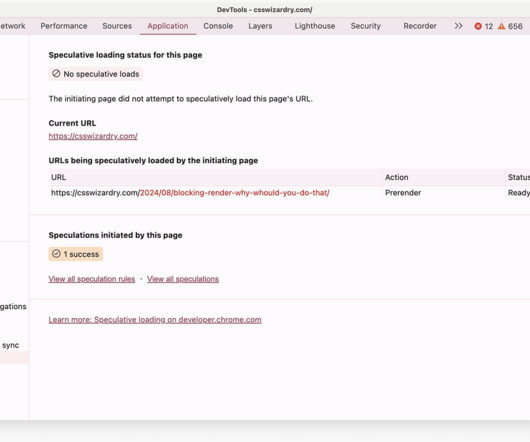
In this post I want to look at how CSS can prove to be a substantial bottleneck on the network (both in itself and for other resources) and how we can mitigate it, thus shortening the Critical Path and reducing our time to Start Render. Employ Critical CSS. This reduces the size of the blocking CSS on the Critical Path.
The good news is that you can maximize availability and prevent website crashes by designing websites specifically for these events. There are also online optimization tools available like Tinify , as well as advanced image editing software like Photoshop or GIMP : Image format is also a key consideration. Lets jump right in!
The high likelihood of unreliable network connectivity led us to lean into mobile solutions for robust client side persistence and offline support. This translates to a large number of app configurations to toggle feature availability and optimize the in-app experience for each production. Networking Hendrix interprets rule set(s)?—?remotely
Users might already have the file cached. If website-a.com links to [link] , and a user goes from there to website-b.com who also links to [link] , then the user will already have that file in their cache. Penalty: Network Negotiation. On a high latency connection, network overhead totals a whopping 5.037s. to just 3.6s.
The GraphQL shim enabled client engineers to move quickly onto GraphQL, figure out client-side concerns like cache normalization, experiment with different GraphQL clients, and investigate client performance without being blocked by server-side migrations. To launch Phase 1 safely, we used AB Testing. How does it work?
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. You can’t change that someone was from Nigeria, you can’t change that someone was on a mobile, and you can’t change their network conditions. Go and give it a quick read—the context will help.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
Browsers will cache tools popular among vocal, leading-edge developers. There's plenty of space for caching most popular frameworks. The best available proxy data also suggests that shared caches would have a minimal positive effect on performance. Suppose a user has only downloaded part of the cache.
Performance Game Changer: Browser Back/Forward Cache. Performance Game Changer: Browser Back/Forward Cache. With that caveat out of the way, let’s get to the guts of the article: What is the Back/Forward Cache and why does it matter so much? Didn’t The HTTP Cache Do All That Anyway? Barry Pollard.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
The demand for Redis is skyrocketing across dozens of use cases, particularly for cache, queues, geospatial data, and high speed transactions. ScaleGrid is the only Redis cloud service that allows you to customize your master-slave and cross-datacenter configurations for 100% uptime and availability across 30 different Azure regions.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. While many databases offer server-side compression, handling compression on the client side reduces expensive server CPU usage, network bandwidth, and disk I/O.
The Site Reliability Guardian helps automate release validation based on SLOs and important signals that define the expected behavior of your applications in terms of availability, performance errors, throughput, latency, etc. This workflow uses the Dynatrace Site Reliability Guardian application.
This allows the app to query a list of “paths” in each HTTP request, and get specially formatted JSON (jsonGraph) that we use to cache the data and hydrate the UI. ecosystem and the rich selection of npm packages available. video titles, descriptions) could be aggressively cached and reused across multiple requests.
Each of these models is suitable for production deployments and high traffic applications, and are available for all of our supported databases, including MySQL , PostgreSQL , Redis™ and MongoDB® database ( Greenplum® database coming soon). This becomes really important for cache solutions like Redis™. Startup Hosting Credits.
We have several YouTube Tutorials and blog posts available that show how you can use Dynatrace RUM data for Web Performance & User Experience Optimization. Missing Cache Settings – Make sure you cache resources that don’t change often on the browser or use a CDN. Impressive results I have to say! N+1 Query Pattern.
Lambda then takes a snapshot of the memory and disk state of the initialized execution environment, persists the encrypted snapshot, and caches it for low-latency access. With SnapStart enabled, function code is initialized once when a function version is published. Users can take advantage of the platform features immediately.
The demand for Redis™ is skyrocketing across dozens of use cases, particularly for cache, queues, geospatial data, and high speed transactions. Redis™, the #1 key-value store and top 10 database in the world, has grown by over 300% in popularity over that past 5 years, per the DB-Engines knowledge base.
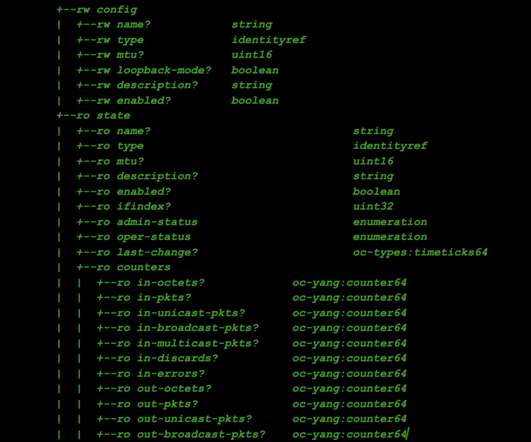
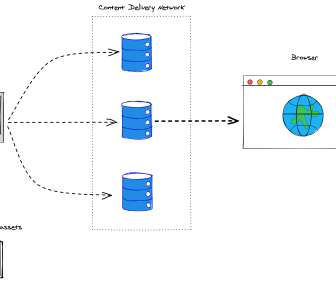
Introducing gnmi-gateway: a modular, distributed, and highly available service for modern network telemetry via OpenConfig and gNMI By: Colin McIntosh, Michael Costello Netflix runs its own content delivery network, Open Connect , which delivers all streaming traffic to our members.
But it’s not easy: to pull this off, VFX studios need to build and operate serious technical infrastructure (compute, storage, networking, and software licensing), otherwise known as a “ render farm.” via direct plug-ins, and is available on multi-cloud platform services. Additionally, Conductor supports render management systems?—?including
Metrics provide a unified and standardized definition to numerical data points over a period of time (for example, network throughput, CPU usage, number of active users, and error rates), whereas logs address traditional logging and allow you to handle logging information in an aggregated fashion.
Have you ever been on a website and noticed a popup notification that suggests that there is a new version of the site available? This is where a pop up notification like Google’s Inbox provides the user with a means of always having the latest version of cached resources. then(cache => cache.addAll([ './dog.jpg'
Choosing your database architecture may be the most critical decision you’ll make and has a disproportionate impact on the performance, scalability, and availability of your app. Get it right and your application will seamlessly scale from hundreds to tens of millions of users without difficulty, while remaining performant and available.
The reason is because mobile networks are, as a rule, high latency connections. only to find that the resource they’re requesting isn’t in that PoP ’s cache. This is exactly what we did at BBC iPlayer last year: The newly-available Server-Timing header can be added to any response. View full size/quality (533KB).
While web browsers and mobile phones have gigabytes of memory available for graphics, our devices are constrained to mere MBs. Our UI runs on top of a custom rendering engine which uses what we call a “surface cache” to optimize our use of graphics memory. The majority of legacy devices run at 28MB of surface cache.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
Historically, NoSQL paid a lot of attention to tradeoffs between consistency, fault-tolerance and performance to serve geographically distributed systems, low-latency or highly available applications. However, consistency is a very expensive thing in distributed systems, so it can be traded not only to availability. Data Placement.
Using a data-driven approach to size Azure resources, Dynatrace OneAgent captures host metrics out-of-the-box to assess CPU, memory, and network utilization on a VM host. Too many fine-grained services leading to network and communication overhead. Missing caching layers. Too much data requested from a database.
Throughout this evolution, we’ve been able to maintain high availability and a consistent message delivery rate, with Pushy successfully maintaining 99.999% reliability for message delivery over the last few months. As a networking team, we naturally lean towards abstracting the communication layer with encapsulation wherever possible.
However, let’s take a step further and learn how to deploy modern qualities to PWAs, such as offline functionality, network-based optimizing, cross-device user experience, SEO capabilities, and non-intrusive notifications and requests. When developing a PWA, you can cache the application shell’s resources and assets in the browser.
The demand for Redis is skyrocketing across dozens of use cases, particularly for cache, queues, geospatial data, and high speed transactions. ” ScaleGrid is the only Redis cloud service that allows you to customize your master-slave and cross-datacenter configurations for 100% uptime and availability across 30 different Azure regions.
For example, if a lookup fails and times out to your first DNS server it queries the next DNS server until the correct IP address is returned, or it is unable to resolve as seen in the infamous "This webpage is not available" error below. Just like with content delivery networks, DNS hosting providers also have multiple POPs.
Without build optimizations (incremental builds, caching, we will get to those soon) this will eventually become unmanageable as well — think about going through all images in a website: resizing, deleting, and/or creating new files over and over again. The cache is invalidated on a time basis. Creating an On-Demand builder.
I am very excited that today we have launched Amazon Route 53, a high-performance and highly-available Domain Name System (DNS) service. There are two main types of DNS servers: authoritative servers and caching resolvers. Caching techniques ensure that the DNS system doesnt get overloaded with queries. Comments ().
Effectively, the memory available for pages of the table gets less. The more indexes, the more the requirement of memory for effective caching. If we don’t increase the available memory, this starts hurting the entire performance of the system. Less-effective cache results in more datafile read, so read I/O is increased.
Effective management of memory stores with policies like LRU/LFU proactive monitoring of the replication process and advanced metrics such as cache hit ratio and persistence indicators are crucial for ensuring data integrity and optimizing Redis’s performance. Cache Hit Ratio The cache hit ratio represents the efficiency of cache usage.
The Solution: Distributed Caching. A widely used technology called distributed caching meets this need by storing frequently accessed data in memory on a server farm instead of within a database. It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches.
The Solution: Distributed Caching. A widely used technology called distributed caching meets this need by storing frequently accessed data in memory on a server farm instead of within a database. It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches.
the order of the rows on your Netflix home page, issuing content licenses when you click play, finding the Open Connect cache closest to you with the content you requested, and many more). Can we adjust our auto-scaling policies to be more efficiency without risking our availability during traffic spikes?
On top of this foundation, we add layers of caching, prerendering and edge delivery optimizations — not the other way around. Surveying the existing landscape of available developer tools and runtimes, we felt that there is a gap. Large preview ). This is not a debate about dynamic vs. static. You need both.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content